 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsuring Smiles: Predicting routine dental coverage using Spark ML
Oct 13, 2023Finding suitable health insurance coverage can be challenging for individuals and small enterprises in the USA. The Health Insurance Exchange Public Use Files (Exchange PUFs) dataset provided by CMS offers valuable information on health and dental policies [1]. In this paper, we leverage machine learning algorithms to predict if a health insurance plan covers routine dental services for adults. By analyzing plan type, region, deductibles, out-of-pocket maximums, and copayments, we employ Logistic Regression, Decision Tree, Random Forest, Gradient Boost, Factorization Model and Support Vector Machine algorithms. Our goal is to provide a clinical strategy for individuals and families to select the most suitable insurance plan based on income and expenses.
Using Spark Machine Learning Models to Perform Predictive Analysis on Flight Ticket Pricing Data
Oct 11, 2023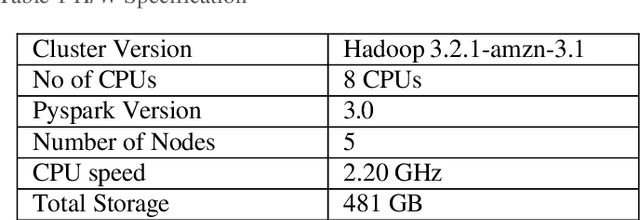

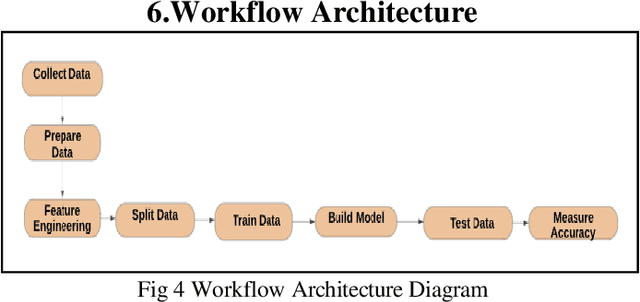
This paper discusses predictive performance and processes undertaken on flight pricing data utilizing r2(r-square) and RMSE that leverages a large dataset, originally from Expedia.com, consisting of approximately 20 million records or 4.68 gigabytes. The project aims to determine the best models usable in the real world to predict airline ticket fares for non-stop flights across the US. Therefore, good generalization capability and optimized processing times are important measures for the model. We will discover key business insights utilizing feature importance and discuss the process and tools used for our analysis. Four regression machine learning algorithms were utilized: Random Forest, Gradient Boost Tree, Decision Tree, and Factorization Machines utilizing Cross Validator and Training Validator functions for assessing performance and generalization capability.
Amazon Books Rating prediction & Recommendation Model
Oct 04, 2023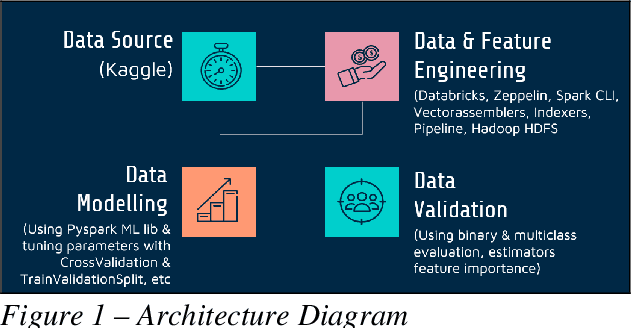
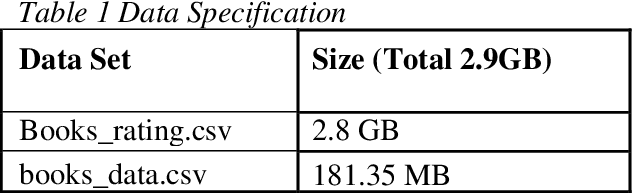

This paper uses the dataset of Amazon to predict the books ratings listed on Amazon website. As part of this project, we predicted the ratings of the books, and also built a recommendation cluster. This recommendation cluster provides the recommended books based on the column's values from dataset, for instance, category, description, author, price, reviews etc. This paper provides a flow of handling big data files, data engineering, building models and providing predictions. The models predict book ratings column using various PySpark Machine Learning APIs. Additionally, we used hyper-parameters and parameters tuning. Also, Cross Validation and TrainValidationSplit were used for generalization. Finally, we performed a comparison between Binary Classification and Multiclass Classification in their accuracies. We converted our label from multiclass to binary to see if we could find any difference between the two classifications. As a result, we found out that we get higher accuracy in binary classification than in multiclass classification.
Scalable Predictive Time-Series Analysis of COVID-19: Cases and Fatalities
Apr 22, 2021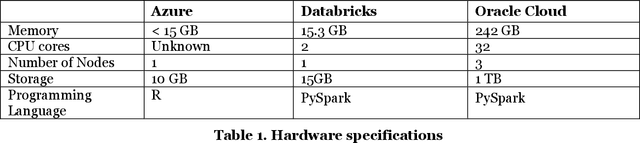
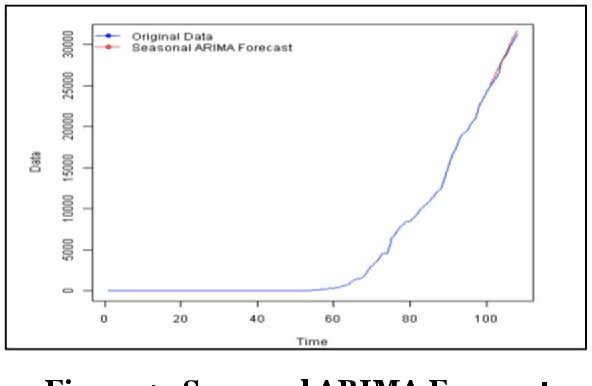
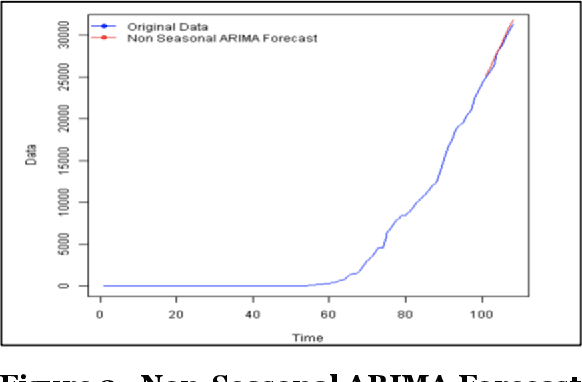

COVID 19 is an acute disease that started spreading throughout the world, beginning in December 2019. It has spread worldwide and has affected more than 7 million people, and 200 thousand people have died due to this infection as of Oct 2020. In this paper, we have forecasted the number of deaths and the confirmed cases in Los Angeles and New York of the United States using the traditional and Big Data platforms based on the Times Series: ARIMA and ETS. We also implemented a more sophisticated time-series forecast model using Facebook Prophet API. Furthermore, we developed the classification models: Logistic Regression and Random Forest regression to show that the Weather does not affect the number of the confirmed cases. The models are built and run in legacy systems (Azure ML Studio) and Big Data systems (Oracle Cloud and Databricks). Besides, we present the accuracy of the models.