 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmazon Books Rating prediction & Recommendation Model
Oct 04, 2023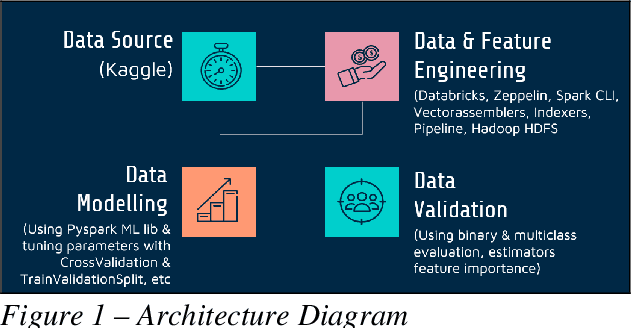
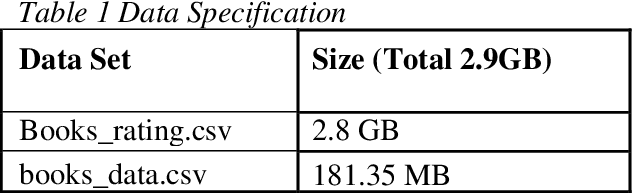
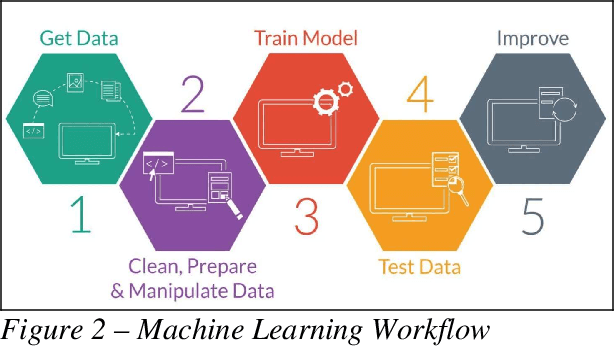

This paper uses the dataset of Amazon to predict the books ratings listed on Amazon website. As part of this project, we predicted the ratings of the books, and also built a recommendation cluster. This recommendation cluster provides the recommended books based on the column's values from dataset, for instance, category, description, author, price, reviews etc. This paper provides a flow of handling big data files, data engineering, building models and providing predictions. The models predict book ratings column using various PySpark Machine Learning APIs. Additionally, we used hyper-parameters and parameters tuning. Also, Cross Validation and TrainValidationSplit were used for generalization. Finally, we performed a comparison between Binary Classification and Multiclass Classification in their accuracies. We converted our label from multiclass to binary to see if we could find any difference between the two classifications. As a result, we found out that we get higher accuracy in binary classification than in multiclass classification.