 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning In-House Large Language Models to Infer Differential Diagnosis from Radiology Reports
Oct 11, 2024



Radiology reports summarize key findings and differential diagnoses derived from medical imaging examinations. The extraction of differential diagnoses is crucial for downstream tasks, including patient management and treatment planning. However, the unstructured nature of these reports, characterized by diverse linguistic styles and inconsistent formatting, presents significant challenges. Although proprietary large language models (LLMs) such as GPT-4 can effectively retrieve clinical information, their use is limited in practice by high costs and concerns over the privacy of protected health information (PHI). This study introduces a pipeline for developing in-house LLMs tailored to identify differential diagnoses from radiology reports. We first utilize GPT-4 to create 31,056 labeled reports, then fine-tune open source LLM using this dataset. Evaluated on a set of 1,067 reports annotated by clinicians, the proposed model achieves an average F1 score of 92.1\%, which is on par with GPT-4 (90.8\%). Through this study, we provide a methodology for constructing in-house LLMs that: match the performance of GPT, reduce dependence on expensive proprietary models, and enhance the privacy and security of PHI.
Humor@IITK at SemEval-2021 Task 7: Large Language Models for Quantifying Humor and Offensiveness
Apr 02, 2021
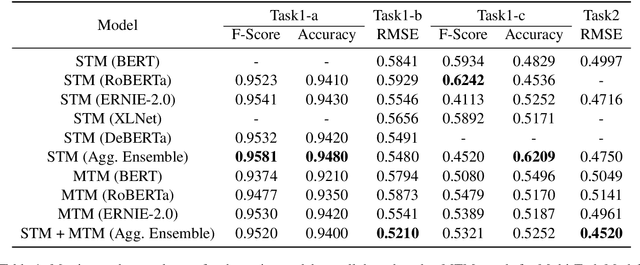
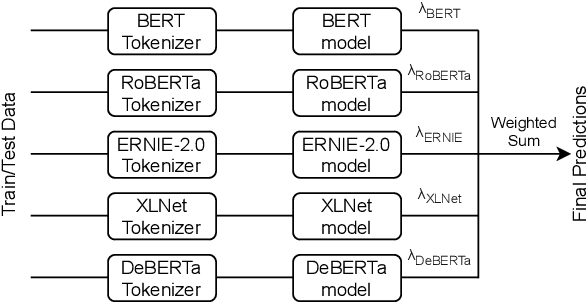
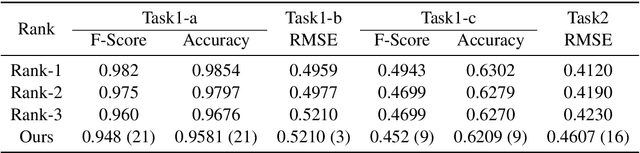
Humor and Offense are highly subjective due to multiple word senses, cultural knowledge, and pragmatic competence. Hence, accurately detecting humorous and offensive texts has several compelling use cases in Recommendation Systems and Personalized Content Moderation. However, due to the lack of an extensive labeled dataset, most prior works in this domain haven't explored large neural models for subjective humor understanding. This paper explores whether large neural models and their ensembles can capture the intricacies associated with humor/offense detection and rating. Our experiments on the SemEval-2021 Task 7: HaHackathon show that we can develop reasonable humor and offense detection systems with such models. Our models are ranked third in subtask 1b and consistently ranked around the top 33% of the leaderboard for the remaining subtasks.