 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegret-Free Reinforcement Learning for LTL Specifications
Nov 18, 2024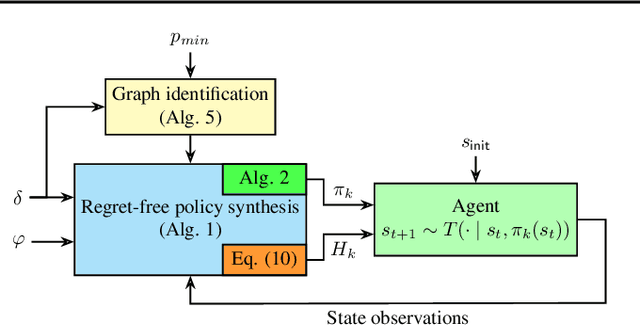
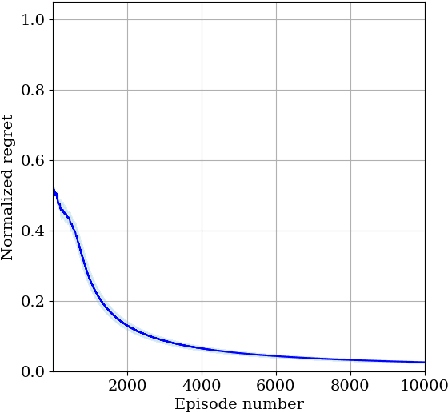
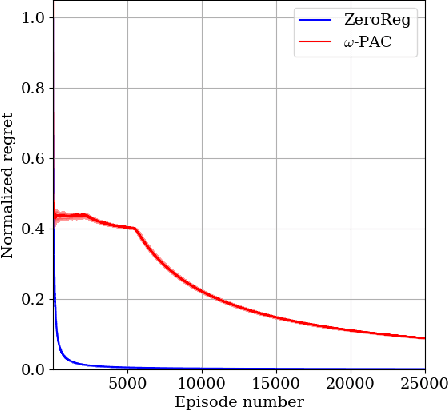
Reinforcement learning (RL) is a promising method to learn optimal control policies for systems with unknown dynamics. In particular, synthesizing controllers for safety-critical systems based on high-level specifications, such as those expressed in temporal languages like linear temporal logic (LTL), presents a significant challenge in control systems research. Current RL-based methods designed for LTL tasks typically offer only asymptotic guarantees, which provide no insight into the transient performance during the learning phase. While running an RL algorithm, it is crucial to assess how close we are to achieving optimal behavior if we stop learning. In this paper, we present the first regret-free online algorithm for learning a controller that addresses the general class of LTL specifications over Markov decision processes (MDPs) with a finite set of states and actions. We begin by proposing a regret-free learning algorithm to solve infinite-horizon reach-avoid problems. For general LTL specifications, we show that the synthesis problem can be reduced to a reach-avoid problem when the graph structure is known. Additionally, we provide an algorithm for learning the graph structure, assuming knowledge of a minimum transition probability, which operates independently of the main regret-free algorithm.
Neural Abstraction-Based Controller Synthesis and Deployment
Jul 07, 2023Abstraction-based techniques are an attractive approach for synthesizing correct-by-construction controllers to satisfy high-level temporal requirements. A main bottleneck for successful application of these techniques is the memory requirement, both during controller synthesis and in controller deployment. We propose memory-efficient methods for mitigating the high memory demands of the abstraction-based techniques using neural network representations. To perform synthesis for reach-avoid specifications, we propose an on-the-fly algorithm that relies on compressed neural network representations of the forward and backward dynamics of the system. In contrast to usual applications of neural representations, our technique maintains soundness of the end-to-end process. To ensure this, we correct the output of the trained neural network such that the corrected output representations are sound with respect to the finite abstraction. For deployment, we provide a novel training algorithm to find a neural network representation of the synthesized controller and experimentally show that the controller can be correctly represented as a combination of a neural network and a look-up table that requires a substantially smaller memory. We demonstrate experimentally that our approach significantly reduces the memory requirements of abstraction-based methods. For the selected benchmarks, our approach reduces the memory requirements respectively for the synthesis and deployment by a factor of $1.31\times 10^5$ and $7.13\times 10^3$ on average, and up to $7.54\times 10^5$ and $3.18\times 10^4$. Although this reduction is at the cost of increased off-line computations to train the neural networks, all the steps of our approach are parallelizable and can be implemented on machines with higher number of processing units to reduce the required computational time.
Perception-in-the-Loop Adversarial Examples
Jan 21, 2019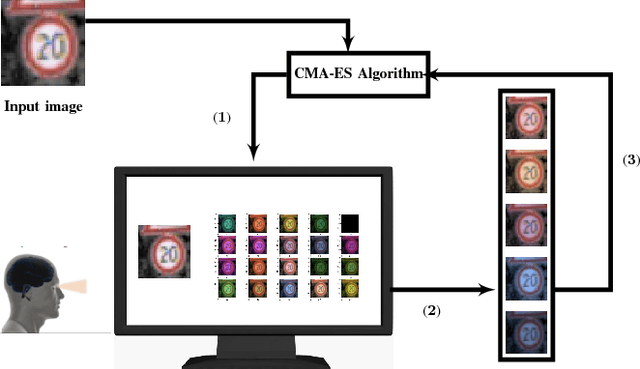



We present a scalable, black box, perception-in-the-loop technique to find adversarial examples for deep neural network classifiers. Black box means that our procedure only has input-output access to the classifier, and not to the internal structure, parameters, or intermediate confidence values. Perception-in-the-loop means that the notion of proximity between inputs can be directly queried from human participants rather than an arbitrarily chosen metric. Our technique is based on covariance matrix adaptation evolution strategy (CMA-ES), a black box optimization approach. CMA-ES explores the search space iteratively in a black box manner, by generating populations of candidates according to a distribution, choosing the best candidates according to a cost function, and updating the posterior distribution to favor the best candidates. We run CMA-ES using human participants to provide the fitness function, using the insight that the choice of best candidates in CMA-ES can be naturally modeled as a perception task: pick the top $k$ inputs perceptually closest to a fixed input. We empirically demonstrate that finding adversarial examples is feasible using small populations and few iterations. We compare the performance of CMA-ES on the MNIST benchmark with other black-box approaches using $L_p$ norms as a cost function, and show that it performs favorably both in terms of success in finding adversarial examples and in minimizing the distance between the original and the adversarial input. In experiments on the MNIST, CIFAR10, and GTSRB benchmarks, we demonstrate that CMA-ES can find perceptually similar adversarial inputs with a small number of iterations and small population sizes when using perception-in-the-loop. Finally, we show that networks trained specifically to be robust against $L_\infty$ norm can still be susceptible to perceptually similar adversarial examples.