 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaperMentor: A Human-Centered Multi-Agent Writing Tutor for AI Research Papers on Overleaf
Jun 07, 2026Expert writing feedback from experienced researchers is critical for early-career scholars to improve their manuscripts, yet high-quality feedback often remains scarce because reviewing research papers is labor-intensive. Emerging AI-powered writing assistants largely focus on grammar fixes or simulating peer review with final scores, yet they fall short of providing concrete, actionable suggestions that help students improve their papers during drafting. We present PaperMentor, a human-centered writing assistant system that delivers actionable suggestions as Overleaf-native inline comments while leaving the actual writing entirely to human authors. PaperMentor integrates an expert skill library carefully curated from established researchers' writing advice with 12 specialized agents covering different aspects of paper writing, such as formatting compliance, phrasing accuracy, and terminology consistency. In a user study (n=14), 90.6% of the generated comments were rated actionable and 67.5% were rated valid, significantly outperforming a GPT-5.2 baseline uswithout the skill library. We release PaperMentor as open source for public use. Our code is publicly available under the AGPL-3.0 license at https://github.com/jiarui-liu/overleaf
Tracing Persona Vectors Through LLM Pretraining
May 13, 2026How large language models internally represent high-level behaviors is a core interpretability question with direct relevance to AI safety: it determines what we can detect, audit, or intervene on. Recent work has shown that traits such as evil or sycophancy correspond to linear directions in the internal activations, the so-called persona vectors. Although these vectors are now routinely utilized to inspect and steer model behavior in safety-relevant settings, how these representations are formed during training remains unknown. To address this gap, we trace persona vectors across the pretraining of OLMo-3-7B, finding that persona vectors form remarkably early -- within 0.22% of OLMo-3 pretraining -- and remain effective for steering the fully post-trained instruct models. Although core representations are formed early on, persona vectors continue to refine geometrically and semantically throughout pretraining. We further compare alternative elicitation strategies and find that all yield effective directions, with each strategy surfacing qualitatively distinct facets of the underlying persona. Replicating our analysis on Apertus-8B reveals that our findings transfer qualitatively beyond OLMo-3. Our results establish persona representations as stable features of early pretraining and open a path to studying how training forms, refines, and shapes them.
Scalable and Explainable Learner-Video Interaction Prediction using Multimodal Large Language Models
Apr 06, 2026Learners' use of video controls in educational videos provides implicit signals of cognitive processing and instructional design quality, yet the lack of scalable and explainable predictive models limits instructors' ability to anticipate such behavior before deployment. We propose a scalable, interpretable pipeline for predicting population-level watching, pausing, skipping, and rewinding behavior as proxies for cognitive load from video content alone. Our approach leverages multimodal large language models (MLLMs) to compute embeddings of short video segments and trains a neural classifier to identify temporally fine-grained interaction peaks. Drawing from multimedia learning theory on instructional design for optimal cognitive load, we code features of the video segments using GPT-5 and employ them as a basis for interpreting model predictions via concept activation vectors. We evaluate our pipeline on 77 million video control events from 66 online courses. Our findings demonstrate that classifiers based on MLLM embeddings reliably predict interaction peaks, generalize to unseen academic fields, and encode interpretable, theory-relevant instructional concepts. Overall, our results show the feasibility of cost-efficient, interpretable pre-screening of educational video design and open new opportunities to empirically examine multimedia learning theory at scale.
SCRIBE: Structured Chain Reasoning for Interactive Behaviour Explanations using Tool Calling
Oct 30, 2025Language models can be used to provide interactive, personalized student feedback in educational settings. However, real-world deployment faces three key challenges: privacy concerns, limited computational resources, and the need for pedagogically valid responses. These constraints require small, open-source models that can run locally and reliably ground their outputs in correct information. We introduce SCRIBE, a framework for multi-hop, tool-augmented reasoning designed to generate valid responses to student questions about feedback reports. SCRIBE combines domain-specific tools with a self-reflective inference pipeline that supports iterative reasoning, tool use, and error recovery. We distil these capabilities into 3B and 8B models via two-stage LoRA fine-tuning on synthetic GPT-4o-generated data. Evaluation with a human-aligned GPT-Judge and a user study with 108 students shows that 8B-SCRIBE models achieve comparable or superior quality to much larger models in key dimensions such as relevance and actionability, while being perceived on par with GPT-4o and Llama-3.3 70B by students. These findings demonstrate the viability of SCRIBE for low-resource, privacy-sensitive educational applications.
Grammar Control in Dialogue Response Generation for Language Learning Chatbots
Feb 11, 2025Chatbots based on large language models offer cheap conversation practice opportunities for language learners. However, they are hard to control for linguistic forms that correspond to learners' current needs, such as grammar. We control grammar in chatbot conversation practice by grounding a dialogue response generation model in a pedagogical repository of grammar skills. We also explore how this control helps learners to produce specific grammar. We comprehensively evaluate prompting, fine-tuning, and decoding strategies for grammar-controlled dialogue response generation. Strategically decoding Llama3 outperforms GPT-3.5 when tolerating minor response quality losses. Our simulation predicts grammar-controlled responses to support grammar acquisition adapted to learner proficiency. Existing language learning chatbots and research on second language acquisition benefit from these affordances. Code available on GitHub.
Temporal and Between-Group Variability in College Dropout Prediction
Jan 12, 2024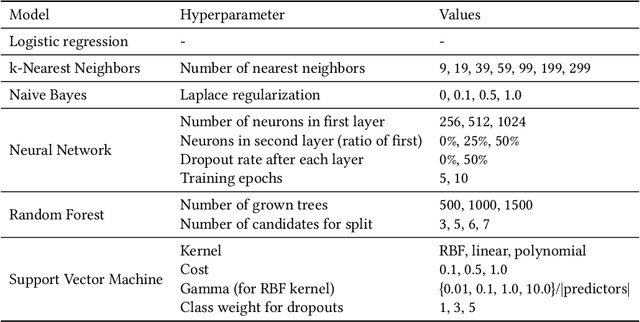


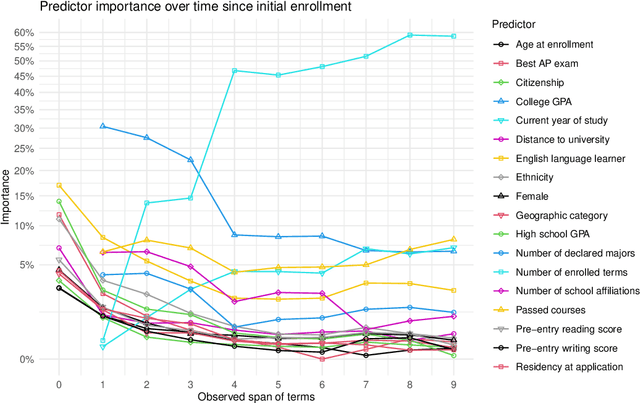
Large-scale administrative data is a common input in early warning systems for college dropout in higher education. Still, the terminology and methodology vary significantly across existing studies, and the implications of different modeling decisions are not fully understood. This study provides a systematic evaluation of contributing factors and predictive performance of machine learning models over time and across different student groups. Drawing on twelve years of administrative data at a large public university in the US, we find that dropout prediction at the end of the second year has a 20% higher AUC than at the time of enrollment in a Random Forest model. Also, most predictive factors at the time of enrollment, including demographics and high school performance, are quickly superseded in predictive importance by college performance and in later stages by enrollment behavior. Regarding variability across student groups, college GPA has more predictive value for students from traditionally disadvantaged backgrounds than their peers. These results can help researchers and administrators understand the comparative value of different data sources when building early warning systems and optimizing decisions under specific policy goals.