 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubgroup Robustness Grows On Trees: An Empirical Baseline Investigation
Nov 23, 2022
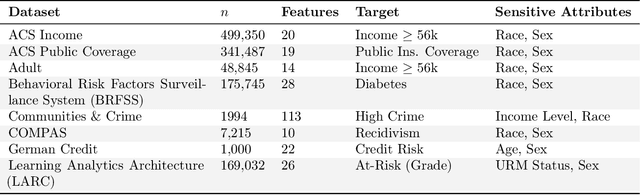

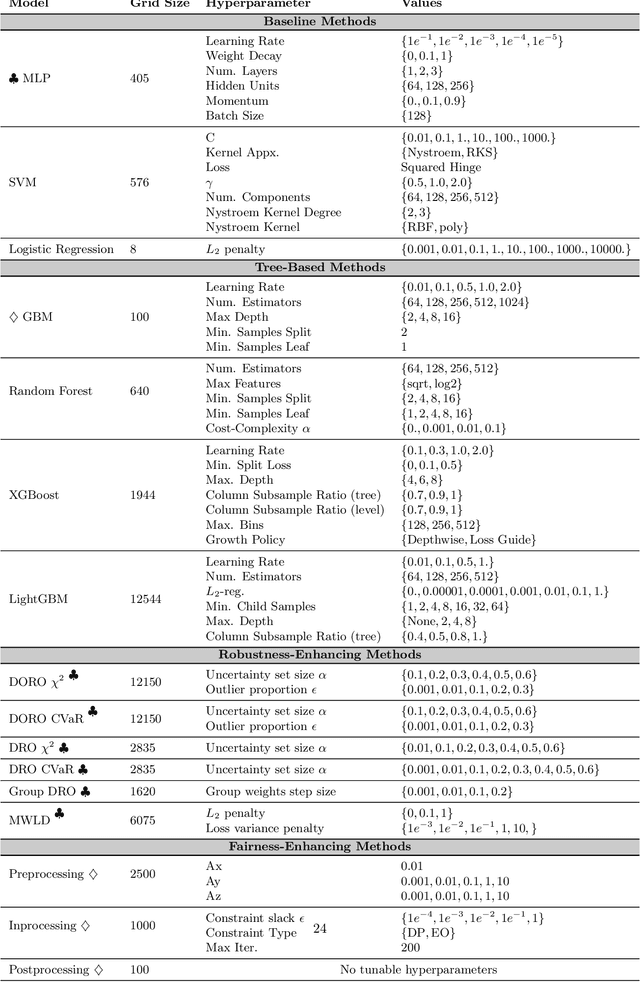
Researchers have proposed many methods for fair and robust machine learning, but comprehensive empirical evaluation of their subgroup robustness is lacking. In this work, we address this gap in the context of tabular data, where sensitive subgroups are clearly-defined, real-world fairness problems abound, and prior works often do not compare to state-of-the-art tree-based models as baselines. We conduct an empirical comparison of several previously-proposed methods for fair and robust learning alongside state-of-the-art tree-based methods and other baselines. Via experiments with more than $340{,}000$ model configurations on eight datasets, we show that tree-based methods have strong subgroup robustness, even when compared to robustness- and fairness-enhancing methods. Moreover, the best tree-based models tend to show good performance over a range of metrics, while robust or group-fair models can show brittleness, with significant performance differences across different metrics for a fixed model. We also demonstrate that tree-based models show less sensitivity to hyperparameter configurations, and are less costly to train. Our work suggests that tree-based ensemble models make an effective baseline for tabular data, and are a sensible default when subgroup robustness is desired. For associated code and detailed results, see https://github.com/jpgard/subgroup-robustness-grows-on-trees .
Exploring The Role of Local and Global Explanations in Recommender Systems
Sep 27, 2021



Explanations are well-known to improve recommender systems' transparency. These explanations may be local, explaining an individual recommendation, or global, explaining the recommender model in general. Despite their widespread use, there has been little investigation into the relative benefits of these two approaches. Do they provide the same benefits to users, or do they serve different purposes? We conducted a 30-participant exploratory study and a 30-participant controlled user study with a research-paper recommender system to analyze how providing participants local, global, or both explanations influences user understanding of system behavior. Our results provide evidence suggesting that both explanations are more helpful than either alone for explaining how to improve recommendations, yet both appeared less helpful than global alone for efficiency in identifying false positives and negatives. However, we note that the two explanation approaches may be better compared in the context of a higher-stakes or more opaque domain.