 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Scale Transfer Learning for Tabular Data via Language Modeling
Paper and Code
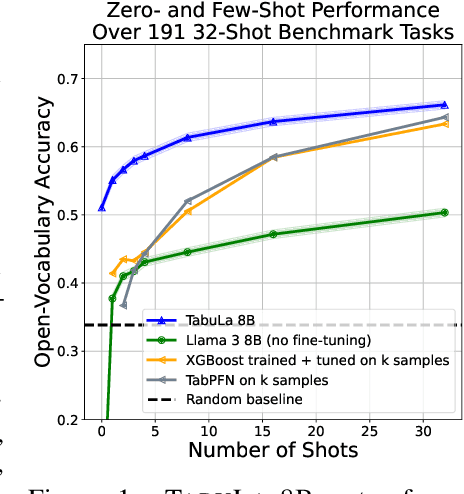
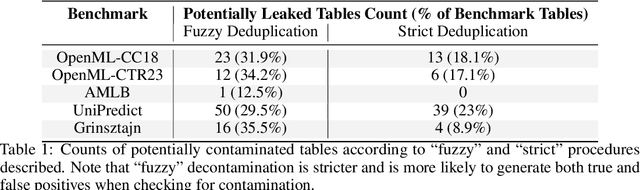


Tabular data -- structured, heterogeneous, spreadsheet-style data with rows and columns -- is widely used in practice across many domains. However, while recent foundation models have reduced the need for developing task-specific datasets and predictors in domains such as language modeling and computer vision, this transfer learning paradigm has not had similar impact in the tabular domain. In this work, we seek to narrow this gap and present TabuLa-8B, a language model for tabular prediction. We define a process for extracting a large, high-quality training dataset from the TabLib corpus, proposing methods for tabular data filtering and quality control. Using the resulting dataset, which comprises over 1.6B rows from 3.1M unique tables, we fine-tune a Llama 3-8B large language model (LLM) for tabular data prediction (classification and binned regression) using a novel packing and attention scheme for tabular prediction. Through evaluation across a test suite of 329 datasets, we find that TabuLa-8B has zero-shot accuracy on unseen tables that is over 15 percentage points (pp) higher than random guessing, a feat that is not possible with existing state-of-the-art tabular prediction models (e.g. XGBoost, TabPFN). In the few-shot setting (1-32 shots), without any fine-tuning on the target datasets, TabuLa-8B is 5-15 pp more accurate than XGBoost and TabPFN models that are explicitly trained on equal, or even up to 16x more data. We release our model, code, and data along with the publication of this paper.