 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptic-Net: A Novel Convolutional Neural Network for Diagnosis of Retinal Diseases from Optical Tomography Images
Oct 13, 2019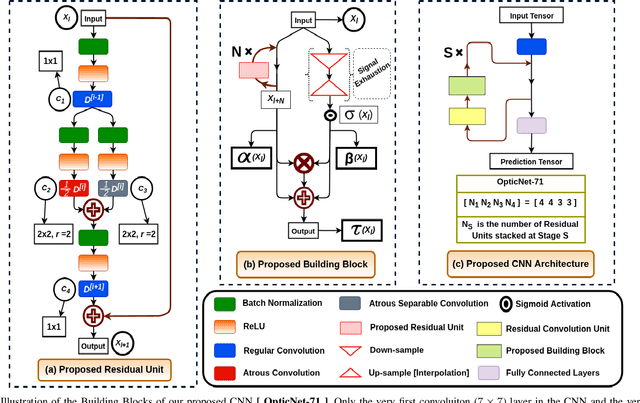
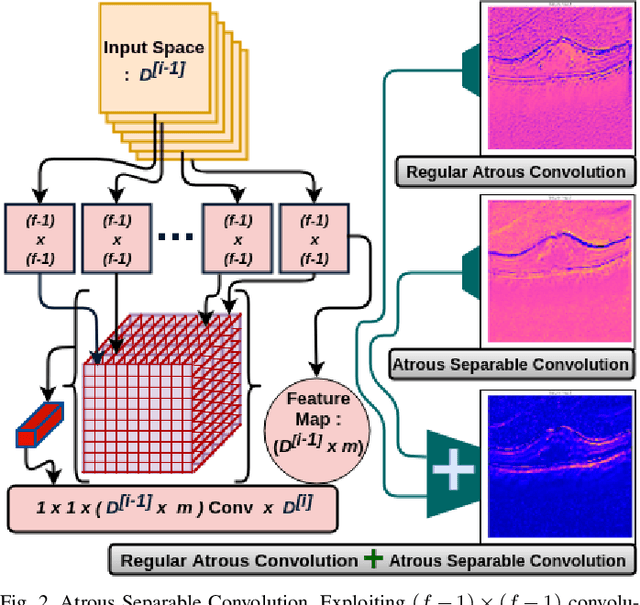
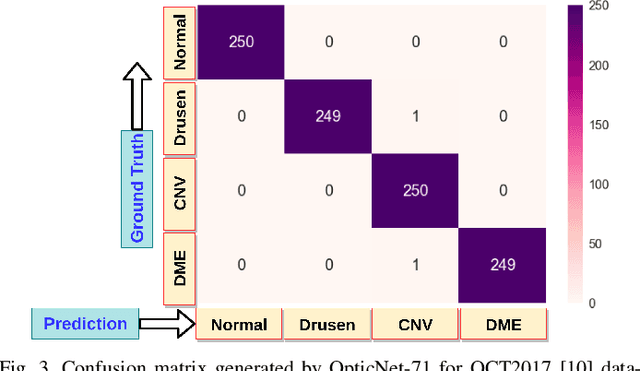
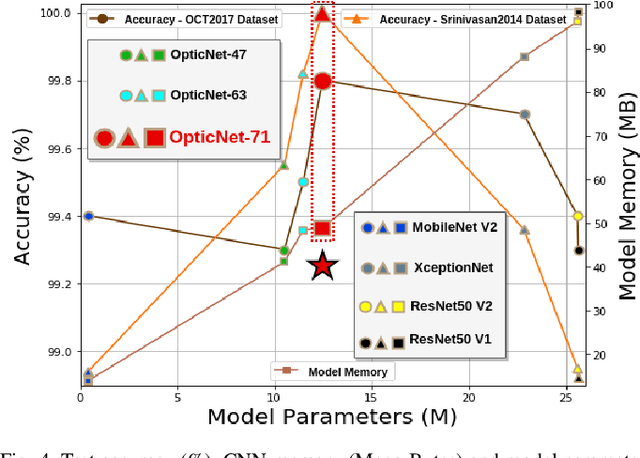
Diagnosing different retinal diseases from Spectral Domain Optical Coherence Tomography (SD-OCT) images is a challenging task. Different automated approaches such as image processing, machine learning and deep learning algorithms have been used for early detection and diagnosis of retinal diseases. Unfortunately, these are prone to error and computational inefficiency, which requires further intervention from human experts. In this paper, we propose a novel convolution neural network architecture to successfully distinguish between different degeneration of retinal layers and their underlying causes. The proposed novel architecture outperforms other classification models while addressing the issue of gradient explosion. Our approach reaches near perfect accuracy of 99.8% and 100% for two separately available Retinal SD-OCT data-set respectively. Additionally, our architecture predicts retinal diseases in real time while outperforming human diagnosticians.
Total Recall: Understanding Traffic Signs using Deep Hierarchical Convolutional Neural Networks
Oct 26, 2018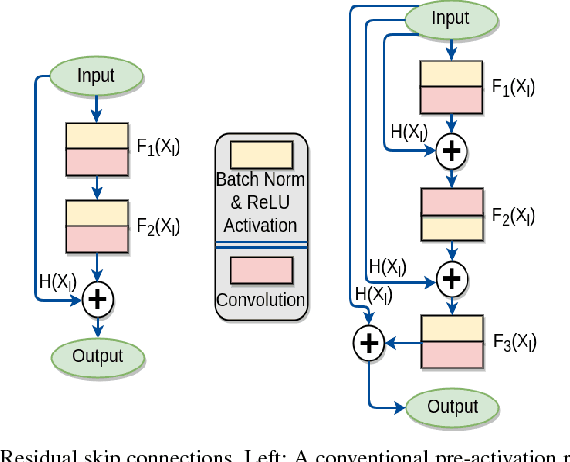
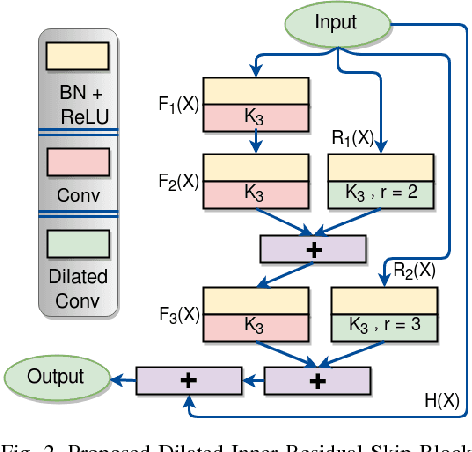
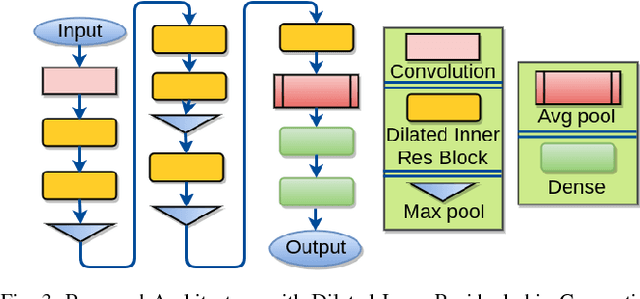

Recognizing Traffic Signs using intelligent systems can drastically reduce the number of accidents happening world-wide. With the arrival of Self-driving cars it has become a staple challenge to solve the automatic recognition of Traffic and Hand-held signs in the major streets. Various machine learning techniques like Random Forest, SVM as well as deep learning models has been proposed for classifying traffic signs. Though they reach state-of-the-art performance on a particular data-set, but fall short of tackling multiple Traffic Sign Recognition benchmarks. In this paper, we propose a novel and one-for-all architecture that aces multiple benchmarks with better overall score than the state-of-the-art architectures. Our model is made of residual convolutional blocks with hierarchical dilated skip connections joined in steps. With this we score 99.33% Accuracy in German sign recognition benchmark and 99.17% Accuracy in Belgian traffic sign classification benchmark. Moreover, we propose a newly devised dilated residual learning representation technique which is very low in both memory and computational complexity.
Efficient Yet Deep Convolutional Neural Networks for Semantic Segmentation
Jul 28, 2018



Semantic Segmentation using deep convolutional neural network pose more complex challenge for any GPU intensive task. As it has to compute million of parameters, it results to huge memory consumption. Moreover, extracting finer features and conducting supervised training tends to increase the complexity. With the introduction of Fully Convolutional Neural Network, which uses finer strides and utilizes deconvolutional layers for upsampling, it has been a go to for any image segmentation task. In this paper, we propose two segmentation architecture which not only needs one-third the parameters to compute but also gives better accuracy than the similar architectures. The model weights were transferred from the popular neural net like VGG19 and VGG16 which were trained on Imagenet classification data-set. Then we transform all the fully connected layers to convolutional layers and use dilated convolution for decreasing the parameters. Lastly, we add finer strides and attach four skip architectures which are element-wise summed with the deconvolutional layers in steps. We train and test on different sparse and fine data-sets like Pascal VOC2012, Pascal-Context and NYUDv2 and show how better our model performs in this tasks. On the other hand our model has a faster inference time and consumes less memory for training and testing on NVIDIA Pascal GPUs, making it more efficient and less memory consuming architecture for pixel-wise segmentation.