 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiDARDustX: A LiDAR Dataset for Dusty Unstructured Road Environments
May 28, 2025

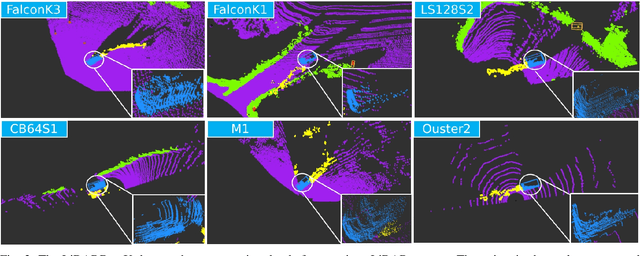

Autonomous driving datasets are essential for validating the progress of intelligent vehicle algorithms, which include localization, perception, and prediction. However, existing datasets are predominantly focused on structured urban environments, which limits the exploration of unstructured and specialized scenarios, particularly those characterized by significant dust levels. This paper introduces the LiDARDustX dataset, which is specifically designed for perception tasks under high-dust conditions, such as those encountered in mining areas. The LiDARDustX dataset consists of 30,000 LiDAR frames captured by six different LiDAR sensors, each accompanied by 3D bounding box annotations and point cloud semantic segmentation. Notably, over 80% of the dataset comprises dust-affected scenes. By utilizing this dataset, we have established a benchmark for evaluating the performance of state-of-the-art 3D detection and segmentation algorithms. Additionally, we have analyzed the impact of dust on perception accuracy and delved into the causes of these effects. The data and further information can be accessed at: https://github.com/vincentweikey/LiDARDustX.
LiSD: An Efficient Multi-Task Learning Framework for LiDAR Segmentation and Detection
Jun 12, 2024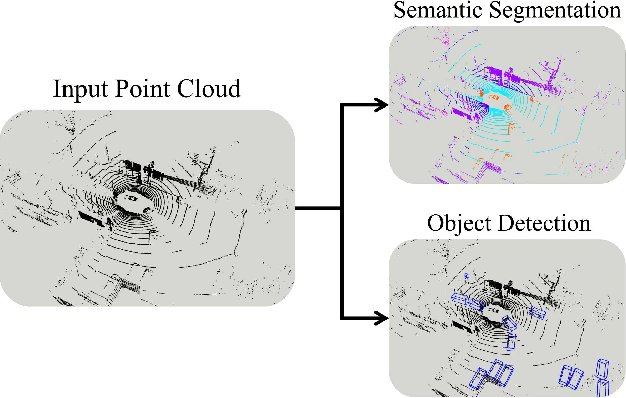
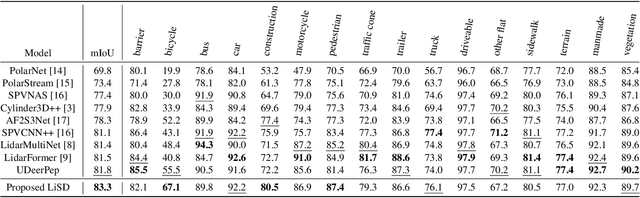
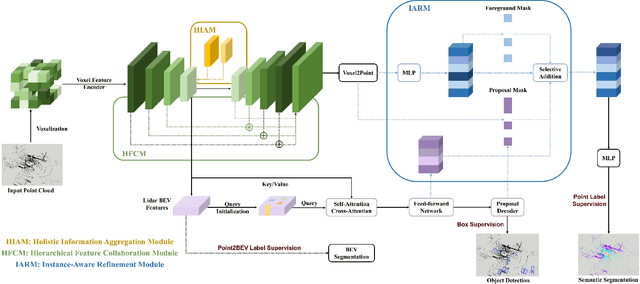
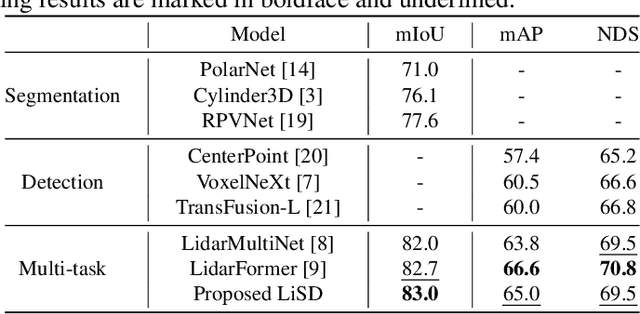
With the rapid proliferation of autonomous driving, there has been a heightened focus on the research of lidar-based 3D semantic segmentation and object detection methodologies, aiming to ensure the safety of traffic participants. In recent decades, learning-based approaches have emerged, demonstrating remarkable performance gains in comparison to conventional algorithms. However, the segmentation and detection tasks have traditionally been examined in isolation to achieve the best precision. To this end, we propose an efficient multi-task learning framework named LiSD which can address both segmentation and detection tasks, aiming to optimize the overall performance. Our proposed LiSD is a voxel-based encoder-decoder framework that contains a hierarchical feature collaboration module and a holistic information aggregation module. Different integration methods are adopted to keep sparsity in segmentation while densifying features for query initialization in detection. Besides, cross-task information is utilized in an instance-aware refinement module to obtain more accurate predictions. Experimental results on the nuScenes dataset and Waymo Open Dataset demonstrate the effectiveness of our proposed model. It is worth noting that LiSD achieves the state-of-the-art performance of 83.3% mIoU on the nuScenes segmentation benchmark for lidar-only methods.
Unsupervised Statistical Feature-Guided Diffusion Model for Sensor-based Human Activity Recognition
May 30, 2023



Recognizing human activities from sensor data is a vital task in various domains, but obtaining diverse and labeled sensor data remains challenging and costly. In this paper, we propose an unsupervised statistical feature-guided diffusion model for sensor-based human activity recognition. The proposed method aims to generate synthetic time-series sensor data without relying on labeled data, addressing the scarcity and annotation difficulties associated with real-world sensor data. By conditioning the diffusion model on statistical information such as mean, standard deviation, Z-score, and skewness, we generate diverse and representative synthetic sensor data. We conducted experiments on public human activity recognition datasets and compared the proposed method to conventional oversampling methods and state-of-the-art generative adversarial network methods. The experimental results demonstrate that the proposed method can improve the performance of human activity recognition and outperform existing techniques.
A Hierarchical Neural Network for Sequence-to-Sequences Learning
Nov 23, 2018
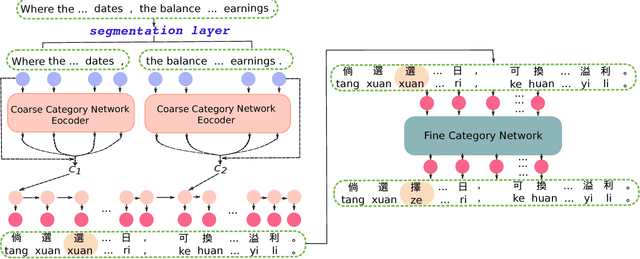

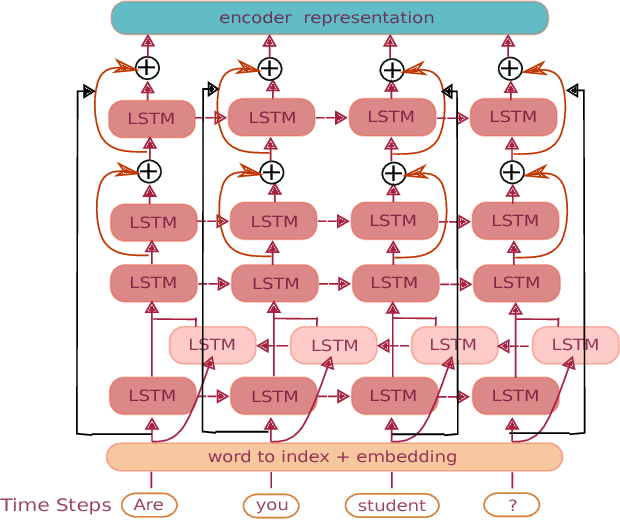
In recent years, the sequence-to-sequence learning neural networks with attention mechanism have achieved great progress. However, there are still challenges, especially for Neural Machine Translation (NMT), such as lower translation quality on long sentences. In this paper, we present a hierarchical deep neural network architecture to improve the quality of long sentences translation. The proposed network embeds sequence-to-sequence neural networks into a two-level category hierarchy by following the coarse-to-fine paradigm. Long sentences are input by splitting them into shorter sequences, which can be well processed by the coarse category network as the long distance dependencies for short sentences is able to be handled by network based on sequence-to-sequence neural network. Then they are concatenated and corrected by the fine category network. The experiments shows that our method can achieve superior results with higher BLEU(Bilingual Evaluation Understudy) scores, lower perplexity and better performance in imitating expression style and words usage than the traditional networks.