 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiSD: An Efficient Multi-Task Learning Framework for LiDAR Segmentation and Detection
Paper and Code
Jun 12, 2024
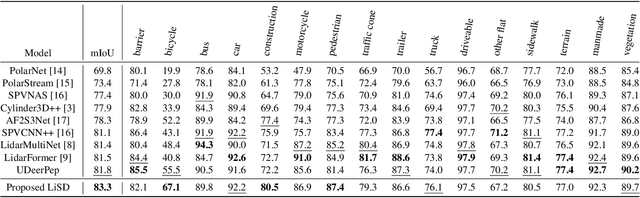
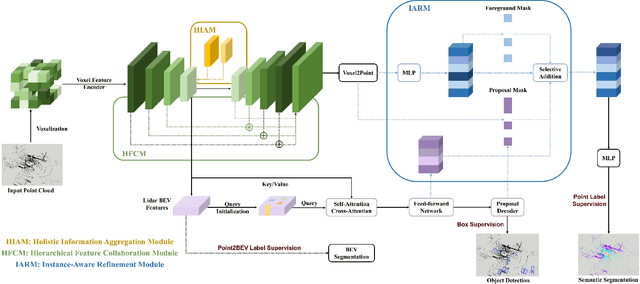
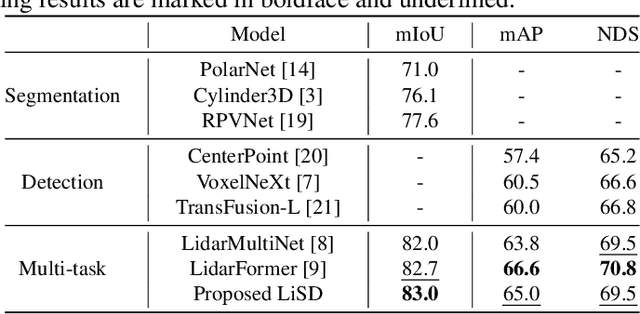
With the rapid proliferation of autonomous driving, there has been a heightened focus on the research of lidar-based 3D semantic segmentation and object detection methodologies, aiming to ensure the safety of traffic participants. In recent decades, learning-based approaches have emerged, demonstrating remarkable performance gains in comparison to conventional algorithms. However, the segmentation and detection tasks have traditionally been examined in isolation to achieve the best precision. To this end, we propose an efficient multi-task learning framework named LiSD which can address both segmentation and detection tasks, aiming to optimize the overall performance. Our proposed LiSD is a voxel-based encoder-decoder framework that contains a hierarchical feature collaboration module and a holistic information aggregation module. Different integration methods are adopted to keep sparsity in segmentation while densifying features for query initialization in detection. Besides, cross-task information is utilized in an instance-aware refinement module to obtain more accurate predictions. Experimental results on the nuScenes dataset and Waymo Open Dataset demonstrate the effectiveness of our proposed model. It is worth noting that LiSD achieves the state-of-the-art performance of 83.3% mIoU on the nuScenes segmentation benchmark for lidar-only methods.