 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiBARF: Integrating Imagery of Different Wavelength Regions by Using Neural Radiance Fields
Mar 19, 2025



Optical sensor applications have become popular through digital transformation. Linking observed data to real-world locations and combining different image sensors is essential to make the applications practical and efficient. However, data preparation to try different sensor combinations requires high sensing and image processing expertise. To make data preparation easier for users unfamiliar with sensing and image processing, we have developed MultiBARF. This method replaces the co-registration and geometric calibration by synthesizing pairs of two different sensor images and depth images at assigned viewpoints. Our method extends Bundle Adjusting Neural Radiance Fields(BARF), a deep neural network-based novel view synthesis method, for the two imagers. Through experiments on visible light and thermographic images, we demonstrate that our method superimposes two color channels of those sensor images on NeRF.
Shape-Net: Room Layout Estimation from Panoramic Images Robust to Occlusion using Knowledge Distillation with 3D Shapes as Additional Inputs
Apr 25, 2023Estimating the layout of a room from a single-shot panoramic image is important in virtual/augmented reality and furniture layout simulation. This involves identifying three-dimensional (3D) geometry, such as the location of corners and boundaries, and performing 3D reconstruction. However, occlusion is a common issue that can negatively impact room layout estimation, and this has not been thoroughly studied to date. It is possible to obtain 3D shape information of rooms as drawings of buildings and coordinates of corners from image datasets, thus we propose providing both 2D panoramic and 3D information to a model to effectively deal with occlusion. However, simply feeding 3D information to a model is not sufficient to utilize the shape information for an occluded area. Therefore, we improve the model by introducing 3D Intersection over Union (IoU) loss to effectively use 3D information. In some cases, drawings are not available or the construction deviates from a drawing. Considering such practical cases, we propose a method for distilling knowledge from a model trained with both images and 3D information to a model that takes only images as input. The proposed model, which is called Shape-Net, achieves state-of-the-art (SOTA) performance on benchmark datasets. We also confirmed its effectiveness in dealing with occlusion through significantly improved accuracy on images with occlusion compared with existing models.
Non-learning Stereo-aided Depth Completion under Mis-projection via Selective Stereo Matching
Oct 04, 2022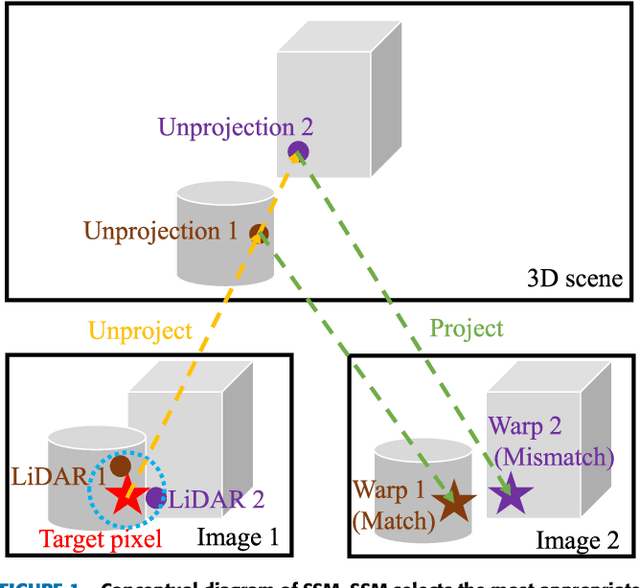
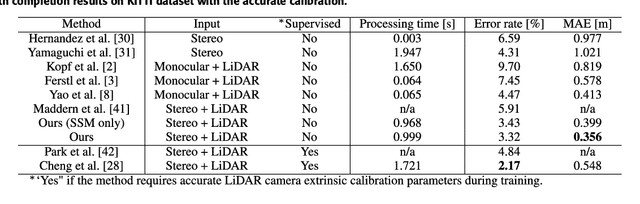
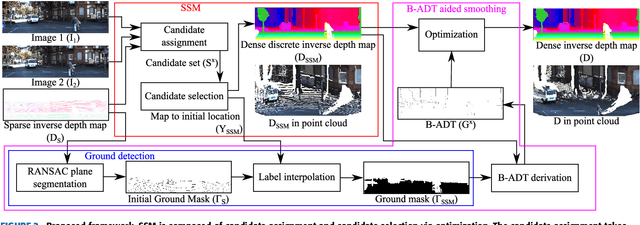

We propose a non-learning depth completion method for a sparse depth map captured using a light detection and ranging (LiDAR) sensor guided by a pair of stereo images. Generally, conventional stereo-aided depth completion methods have two limiations. (i) They assume the given sparse depth map is accurately aligned to the input image, whereas the alignment is difficult to achieve in practice. (ii) They have limited accuracy in the long range because the depth is estimated by pixel disparity. To solve the abovementioned limitations, we propose selective stereo matching (SSM) that searches the most appropriate depth value for each image pixel from its neighborly projected LiDAR points based on an energy minimization framework. This depth selection approach can handle any type of mis-projection. Moreover, SSM has an advantage in terms of long-range depth accuracy because it directly uses the LiDAR measurement rather than the depth acquired from the stereo. SSM is a discrete process; thus, we apply variational smoothing with binary anisotropic diffusion tensor (B-ADT) to generate a continuous depth map while preserving depth discontinuity across object boundaries. Experimentally, compared with the previous state-of-the-art stereo-aided depth completion, the proposed method reduced the mean absolute error (MAE) of the depth estimation to 0.65 times and demonstrated approximately twice more accurate estimation in the long range. Moreover, under various LiDAR-camera calibration errors, the proposed method reduced the depth estimation MAE to 0.34-0.93 times from previous depth completion methods.
* 15 pages, 13 figures