 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLEU, METEOR, BERTScore: Evaluation of Metrics Performance in Assessing Critical Translation Errors in Sentiment-oriented Text
Paper and Code
Sep 29, 2021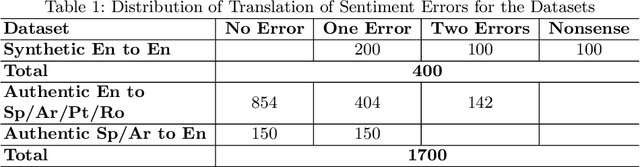
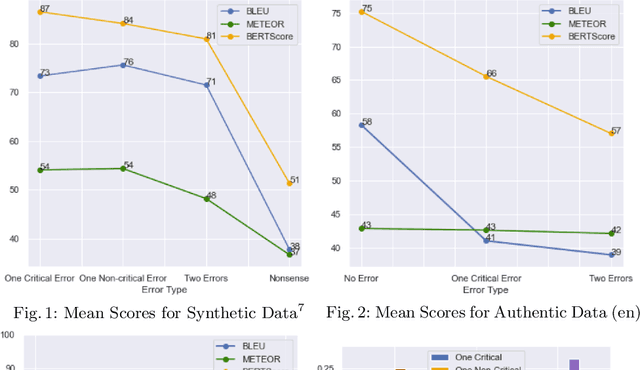
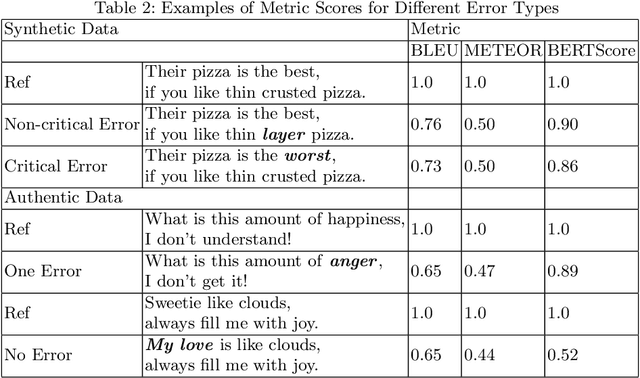

Social media companies as well as authorities make extensive use of artificial intelligence (AI) tools to monitor postings of hate speech, celebrations of violence or profanity. Since AI software requires massive volumes of data to train computers, Machine Translation (MT) of the online content is commonly used to process posts written in several languages and hence augment the data needed for training. However, MT mistakes are a regular occurrence when translating sentiment-oriented user-generated content (UGC), especially when a low-resource language is involved. The adequacy of the whole process relies on the assumption that the evaluation metrics used give a reliable indication of the quality of the translation. In this paper, we assess the ability of automatic quality metrics to detect critical machine translation errors which can cause serious misunderstanding of the affect message. We compare the performance of three canonical metrics on meaningless translations where the semantic content is seriously impaired as compared to meaningful translations with a critical error which exclusively distorts the sentiment of the source text. We conclude that there is a need for fine-tuning of automatic metrics to make them more robust in detecting sentiment critical errors.