 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Object Detection in Remote Sensing: Lifting the Curse of Incompletely Annotated Novel Objects
Paper and Code
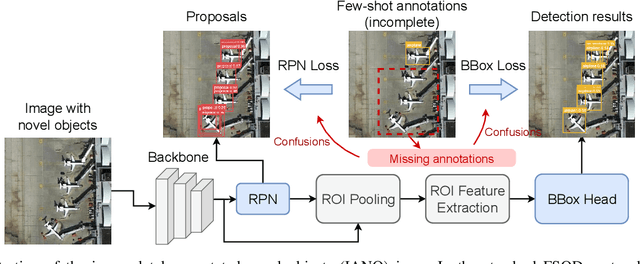
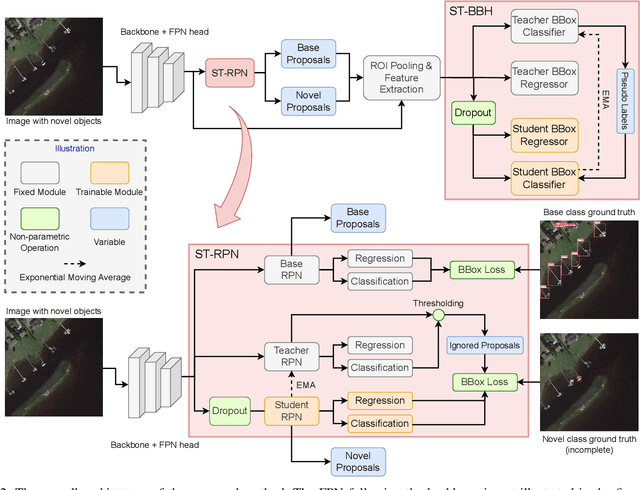
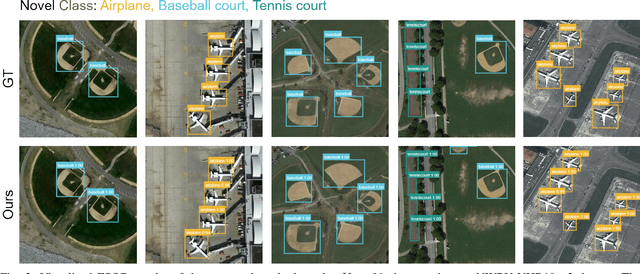
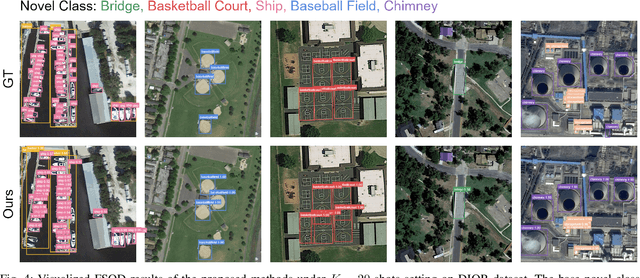
Object detection is an essential and fundamental task in computer vision and satellite image processing. Existing deep learning methods have achieved impressive performance thanks to the availability of large-scale annotated datasets. Yet, in real-world applications the availability of labels is limited. In this context, few-shot object detection (FSOD) has emerged as a promising direction, which aims at enabling the model to detect novel objects with only few of them annotated. However, many existing FSOD algorithms overlook a critical issue: when an input image contains multiple novel objects and only a subset of them are annotated, the unlabeled objects will be considered as background during training. This can cause confusions and severely impact the model's ability to recall novel objects. To address this issue, we propose a self-training-based FSOD (ST-FSOD) approach, which incorporates the self-training mechanism into the few-shot fine-tuning process. ST-FSOD aims to enable the discovery of novel objects that are not annotated, and take them into account during training. On the one hand, we devise a two-branch region proposal networks (RPN) to separate the proposal extraction of base and novel objects, On another hand, we incorporate the student-teacher mechanism into RPN and the region of interest (RoI) head to include those highly confident yet unlabeled targets as pseudo labels. Experimental results demonstrate that our proposed method outperforms the state-of-the-art in various FSOD settings by a large margin. The codes will be publicly available at https://github.com/zhu-xlab/ST-FSOD.