 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Latent Transformer for Interpretable Monocular Height Estimation
Paper and Code
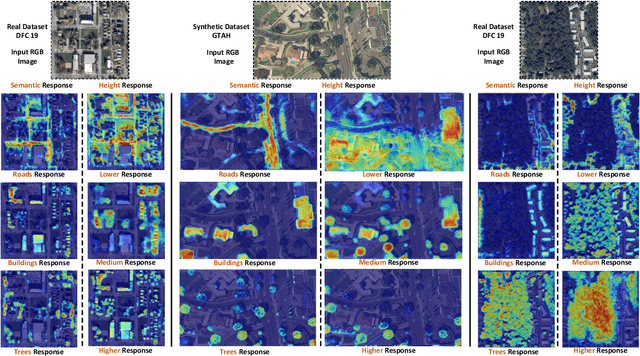
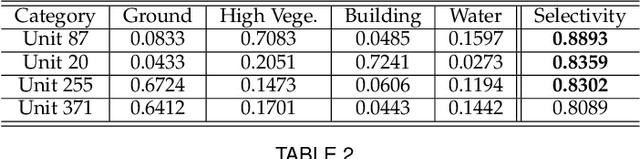
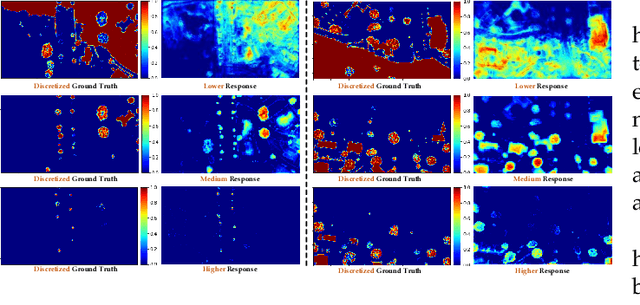

Monocular height estimation (MHE) from remote sensing imagery has high potential in generating 3D city models efficiently for a quick response to natural disasters. Most existing works pursue higher performance. However, there is little research exploring the interpretability of MHE networks. In this paper, we target at exploring how deep neural networks predict height from a single monocular image. Towards a comprehensive understanding of MHE networks, we propose to interpret them from multiple levels: 1) Neurons: unit-level dissection. Exploring the semantic and height selectivity of the learned internal deep representations; 2) Instances: object-level interpretation. Studying the effects of different semantic classes, scales, and spatial contexts on height estimation; 3) Attribution: pixel-level analysis. Understanding which input pixels are important for the height estimation. Based on the multi-level interpretation, a disentangled latent Transformer network is proposed towards a more compact, reliable, and explainable deep model for monocular height estimation. Furthermore, a novel unsupervised semantic segmentation task based on height estimation is first introduced in this work. Additionally, we also construct a new dataset for joint semantic segmentation and height estimation. Our work provides novel insights for both understanding and designing MHE models.