 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVPbev: Multi-view Perspective Image Generation from BEV with Test-time Controllability and Generalizability
Jul 28, 2024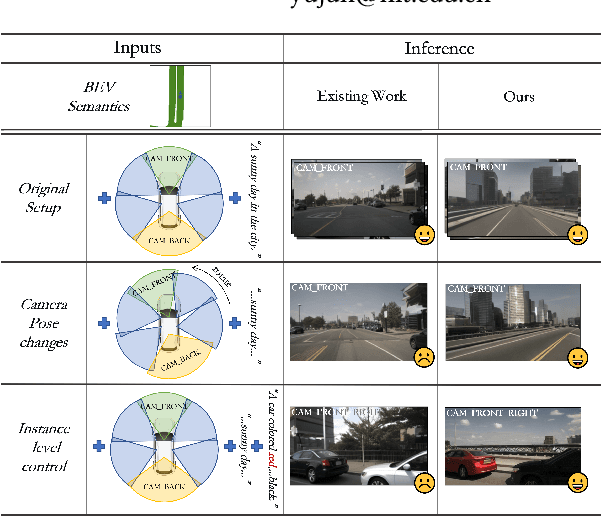
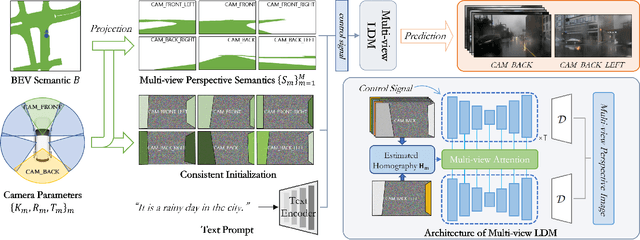
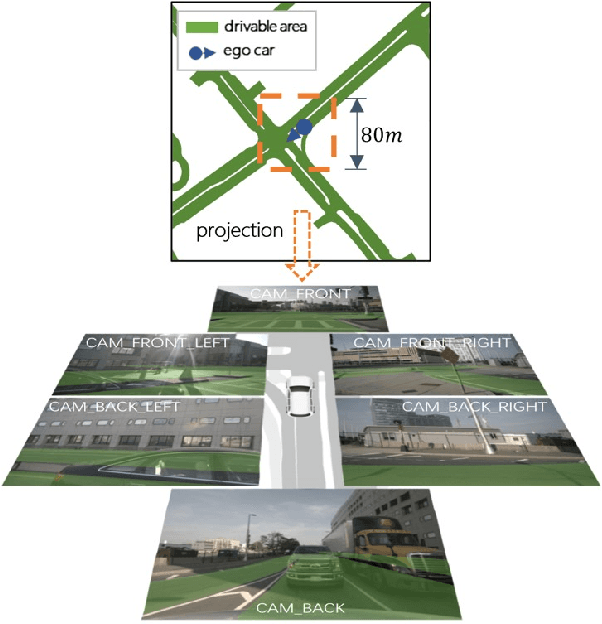
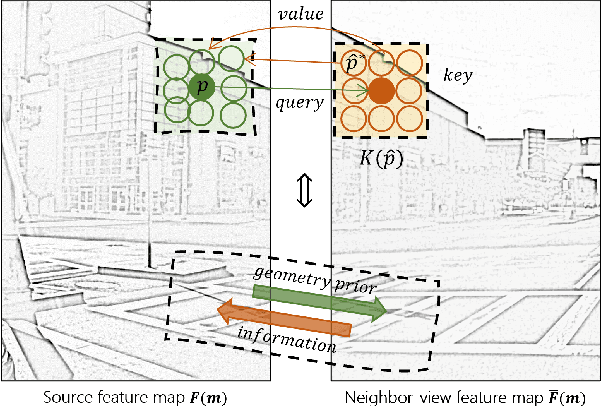
This work aims to address the multi-view perspective RGB generation from text prompts given Bird-Eye-View(BEV) semantics. Unlike prior methods that neglect layout consistency, lack the ability to handle detailed text prompts, or are incapable of generalizing to unseen view points, MVPbev simultaneously generates cross-view consistent images of different perspective views with a two-stage design, allowing object-level control and novel view generation at test-time. Specifically, MVPbev firstly projects given BEV semantics to perspective view with camera parameters, empowering the model to generalize to unseen view points. Then we introduce a multi-view attention module where special initialization and de-noising processes are introduced to explicitly enforce local consistency among overlapping views w.r.t. cross-view homography. Last but not least, MVPbev further allows test-time instance-level controllability by refining a pre-trained text-to-image diffusion model. Our extensive experiments on NuScenes demonstrate that our method is capable of generating high-resolution photorealistic images from text descriptions with thousands of training samples, surpassing the state-of-the-art methods under various evaluation metrics. We further demonstrate the advances of our method in terms of generalizability and controllability with the help of novel evaluation metrics and comprehensive human analysis. Our code, data, and model can be found in \url{https://github.com/kkaiwwana/MVPbev}.
The Story in Your Eyes: An Individual-difference-aware Model for Cross-person Gaze Estimation
Jun 27, 2021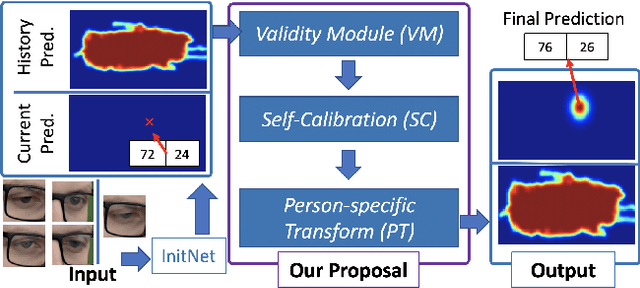

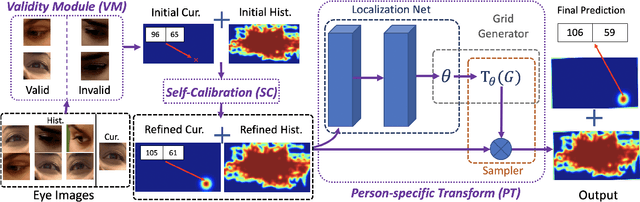
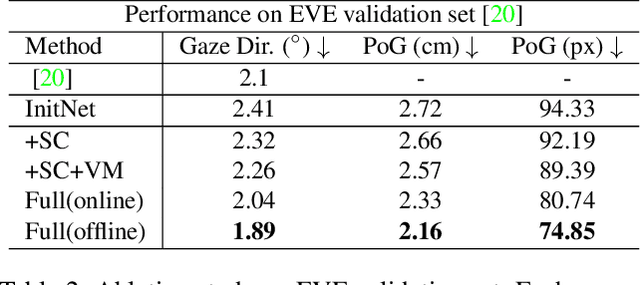
We propose a novel method on refining cross-person gaze prediction task with eye/face images only by explicitly modelling the person-specific differences. Specifically, we first assume that we can obtain some initial gaze prediction results with existing method, which we refer to as InitNet, and then introduce three modules, the Validity Module (VM), Self-Calibration (SC) and Person-specific Transform (PT)) Module. By predicting the reliability of current eye/face images, our VM is able to identify invalid samples, e.g. eye blinking images, and reduce their effects in our modelling process. Our SC and PT module then learn to compensate for the differences on valid samples only. The former models the translation offsets by bridging the gap between initial predictions and dataset-wise distribution. And the later learns more general person-specific transformation by incorporating the information from existing initial predictions of the same person. We validate our ideas on three publicly available datasets, EVE, XGaze and MPIIGaze and demonstrate that our proposed method outperforms the SOTA methods significantly on all of them, e.g. respectively 21.7%, 36.0% and 32.9% relative performance improvements. We won the GAZE 2021 Competition on the EVE dataset. Our code can be found here https://github.com/bjj9/EVE_SCPT.