 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Contrastive Quantization for Efficient Cross-View Video Retrieval
Paper and Code
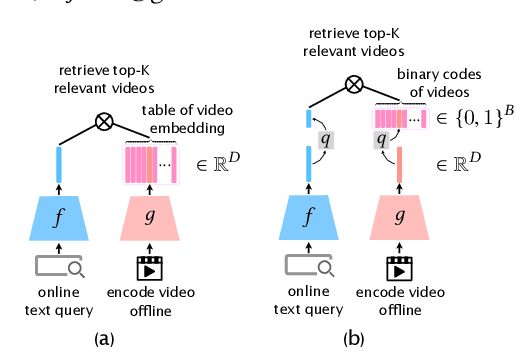
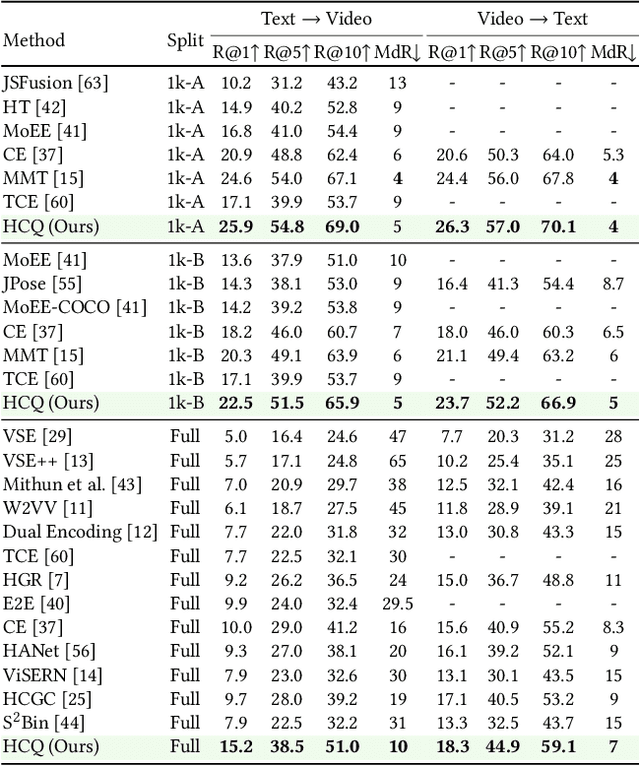
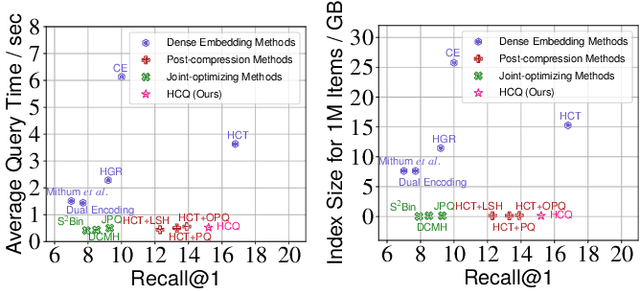

With the recent boom of video-based social platforms (e.g., YouTube and TikTok), video retrieval using sentence queries has become an important demand and attracts increasing research attention. Despite the decent performance, existing text-video retrieval models in vision and language communities are impractical for large-scale Web search because they adopt brute-force search based on high-dimensional embeddings. To improve efficiency, Web search engines widely apply vector compression libraries (e.g., FAISS) to post-process the learned embeddings. Unfortunately, separate compression from feature encoding degrades the robustness of representations and incurs performance decay. To pursue a better balance between performance and efficiency, we propose the first quantized representation learning method for cross-view video retrieval, namely Hybrid Contrastive Quantization (HCQ). Specifically, HCQ learns both coarse-grained and fine-grained quantizations with transformers, which provide complementary understandings for texts and videos and preserve comprehensive semantic information. By performing Asymmetric-Quantized Contrastive Learning (AQ-CL) across views, HCQ aligns texts and videos at coarse-grained and multiple fine-grained levels. This hybrid-grained learning strategy serves as strong supervision on the cross-view video quantization model, where contrastive learning at different levels can be mutually promoted. Extensive experiments on three Web video benchmark datasets demonstrate that HCQ achieves competitive performance with state-of-the-art non-compressed retrieval methods while showing high efficiency in storage and computation. Code and configurations are available at https://github.com/gimpong/WWW22-HCQ.