 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobally Convergent Accelerated Algorithms for Multilinear Sparse Logistic Regression with $\ell_0$-constraints
Sep 17, 2023



Tensor data represents a multidimensional array. Regression methods based on low-rank tensor decomposition leverage structural information to reduce the parameter count. Multilinear logistic regression serves as a powerful tool for the analysis of multidimensional data. To improve its efficacy and interpretability, we present a Multilinear Sparse Logistic Regression model with $\ell_0$-constraints ($\ell_0$-MLSR). In contrast to the $\ell_1$-norm and $\ell_2$-norm, the $\ell_0$-norm constraint is better suited for feature selection. However, due to its nonconvex and nonsmooth properties, solving it is challenging and convergence guarantees are lacking. Additionally, the multilinear operation in $\ell_0$-MLSR also brings non-convexity. To tackle these challenges, we propose an Accelerated Proximal Alternating Linearized Minimization with Adaptive Momentum (APALM$^+$) method to solve the $\ell_0$-MLSR model. We provide a proof that APALM$^+$ can ensure the convergence of the objective function of $\ell_0$-MLSR. We also demonstrate that APALM$^+$ is globally convergent to a first-order critical point as well as establish convergence rate by using the Kurdyka-Lojasiewicz property. Empirical results obtained from synthetic and real-world datasets validate the superior performance of our algorithm in terms of both accuracy and speed compared to other state-of-the-art methods.
An Accelerated Block Proximal Framework with Adaptive Momentum for Nonconvex and Nonsmooth Optimization
Aug 24, 2023



We propose an accelerated block proximal linear framework with adaptive momentum (ABPL$^+$) for nonconvex and nonsmooth optimization. We analyze the potential causes of the extrapolation step failing in some algorithms, and resolve this issue by enhancing the comparison process that evaluates the trade-off between the proximal gradient step and the linear extrapolation step in our algorithm. Furthermore, we extends our algorithm to any scenario involving updating block variables with positive integers, allowing each cycle to randomly shuffle the update order of the variable blocks. Additionally, under mild assumptions, we prove that ABPL$^+$ can monotonically decrease the function value without strictly restricting the extrapolation parameters and step size, demonstrates the viability and effectiveness of updating these blocks in a random order, and we also more obviously and intuitively demonstrate that the derivative set of the sequence generated by our algorithm is a critical point set. Moreover, we demonstrate the global convergence as well as the linear and sublinear convergence rates of our algorithm by utilizing the Kurdyka-Lojasiewicz (K{\L}) condition. To enhance the effectiveness and flexibility of our algorithm, we also expand the study to the imprecise version of our algorithm and construct an adaptive extrapolation parameter strategy, which improving its overall performance. We apply our algorithm to multiple non-negative matrix factorization with the $\ell_0$ norm, nonnegative tensor decomposition with the $\ell_0$ norm, and perform extensive numerical experiments to validate its effectiveness and efficiency.
Weak Supervision for Fake News Detection via Reinforcement Learning
Jan 20, 2020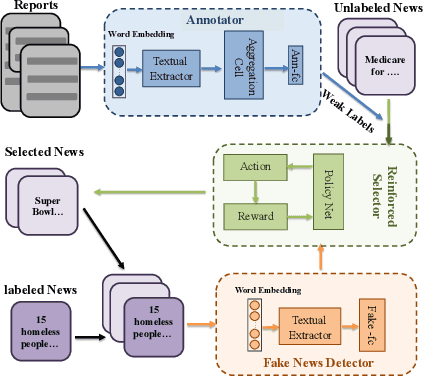
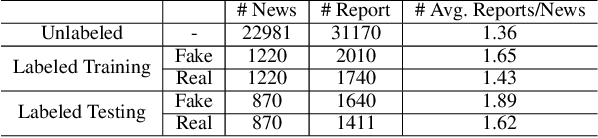
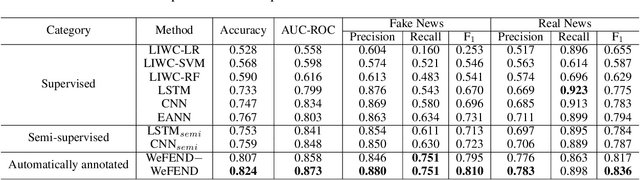
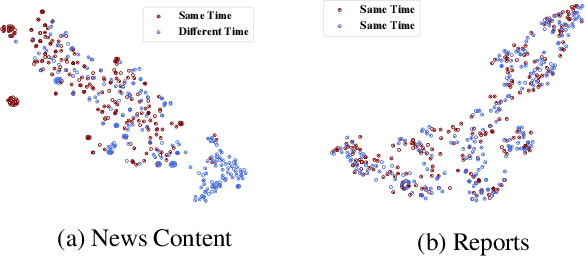
Today social media has become the primary source for news. Via social media platforms, fake news travel at unprecedented speeds, reach global audiences and put users and communities at great risk. Therefore, it is extremely important to detect fake news as early as possible. Recently, deep learning based approaches have shown improved performance in fake news detection. However, the training of such models requires a large amount of labeled data, but manual annotation is time-consuming and expensive. Moreover, due to the dynamic nature of news, annotated samples may become outdated quickly and cannot represent the news articles on newly emerged events. Therefore, how to obtain fresh and high-quality labeled samples is the major challenge in employing deep learning models for fake news detection. In order to tackle this challenge, we propose a reinforced weakly-supervised fake news detection framework, i.e., WeFEND, which can leverage users' reports as weak supervision to enlarge the amount of training data for fake news detection. The proposed framework consists of three main components: the annotator, the reinforced selector and the fake news detector. The annotator can automatically assign weak labels for unlabeled news based on users' reports. The reinforced selector using reinforcement learning techniques chooses high-quality samples from the weakly labeled data and filters out those low-quality ones that may degrade the detector's prediction performance. The fake news detector aims to identify fake news based on the news content. We tested the proposed framework on a large collection of news articles published via WeChat official accounts and associated user reports. Extensive experiments on this dataset show that the proposed WeFEND model achieves the best performance compared with the state-of-the-art methods.