 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural ODE and SDE Models for Adaptation and Planning in Model-Based Reinforcement Learning
Mar 24, 2026We investigate neural ordinary and stochastic differential equations (neural ODEs and SDEs) to model stochastic dynamics in fully and partially observed environments within a model-based reinforcement learning (RL) framework. Through a sequence of simulations, we show that neural SDEs more effectively capture the inherent stochasticity of transition dynamics, enabling high-performing policies with improved sample efficiency in challenging scenarios. We leverage neural ODEs and SDEs for efficient policy adaptation to changes in environment dynamics via inverse models, requiring only limited interactions with the new environment. To address partial observability, we introduce a latent SDE model that combines an ODE with a GAN-trained stochastic component in latent space. Policies derived from this model provide a strong baseline, outperforming or matching general model-based and model-free approaches across stochastic continuous-control benchmarks. This work demonstrates the applicability of action-conditional latent SDEs for RL planning in environments with stochastic transitions. Our code is available at: https://github.com/ChaoHan-UoS/NeuralRL
Lagrangian-based Equilibrium Propagation: generalisation to arbitrary boundary conditions & equivalence with Hamiltonian Echo Learning
Jun 06, 2025Equilibrium Propagation (EP) is a learning algorithm for training Energy-based Models (EBMs) on static inputs which leverages the variational description of their fixed points. Extending EP to time-varying inputs is a challenging problem, as the variational description must apply to the entire system trajectory rather than just fixed points, and careful consideration of boundary conditions becomes essential. In this work, we present Generalized Lagrangian Equilibrium Propagation (GLEP), which extends the variational formulation of EP to time-varying inputs. We demonstrate that GLEP yields different learning algorithms depending on the boundary conditions of the system, many of which are impractical for implementation. We then show that Hamiltonian Echo Learning (HEL) -- which includes the recently proposed Recurrent HEL (RHEL) and the earlier known Hamiltonian Echo Backpropagation (HEB) algorithms -- can be derived as a special case of GLEP. Notably, HEL is the only instance of GLEP we found that inherits the properties that make EP a desirable alternative to backpropagation for hardware implementations: it operates in a "forward-only" manner (i.e. using the same system for both inference and learning), it scales efficiently (requiring only two or more passes through the system regardless of model size), and enables local learning.
Dynamical-VAE-based Hindsight to Learn the Causal Dynamics of Factored-POMDPs
Nov 12, 2024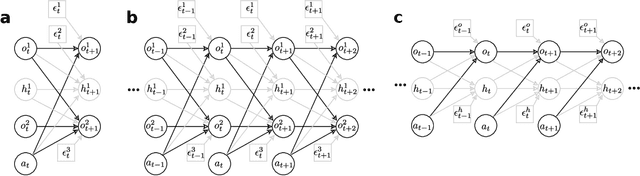
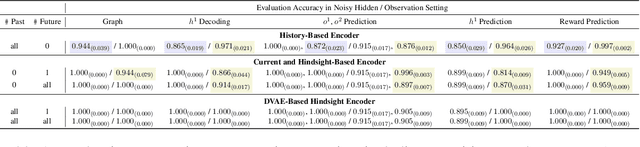
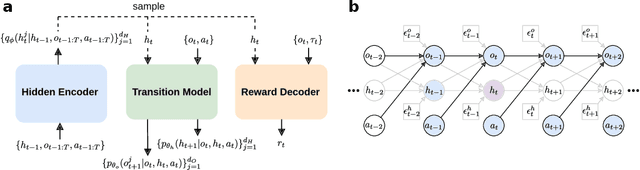
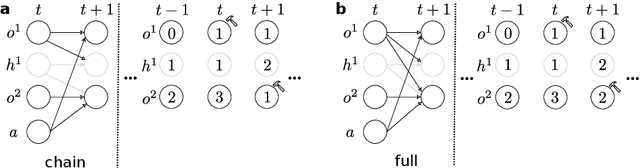
Learning representations of underlying environmental dynamics from partial observations is a critical challenge in machine learning. In the context of Partially Observable Markov Decision Processes (POMDPs), state representations are often inferred from the history of past observations and actions. We demonstrate that incorporating future information is essential to accurately capture causal dynamics and enhance state representations. To address this, we introduce a Dynamical Variational Auto-Encoder (DVAE) designed to learn causal Markovian dynamics from offline trajectories in a POMDP. Our method employs an extended hindsight framework that integrates past, current, and multi-step future information within a factored-POMDP setting. Empirical results reveal that this approach uncovers the causal graph governing hidden state transitions more effectively than history-based and typical hindsight-based models.
Measuring Exploration in Reinforcement Learning via Optimal Transport in Policy Space
Feb 14, 2024



Exploration is the key ingredient of reinforcement learning (RL) that determines the speed and success of learning. Here, we quantify and compare the amount of exploration and learning accomplished by a Reinforcement Learning (RL) algorithm. Specifically, we propose a novel measure, named Exploration Index, that quantifies the relative effort of knowledge transfer (transferability) by an RL algorithm in comparison to supervised learning (SL) that transforms the initial data distribution of RL to the corresponding final data distribution. The comparison is established by formulating learning in RL as a sequence of SL tasks, and using optimal transport based metrics to compare the total path traversed by the RL and SL algorithms in the data distribution space. We perform extensive empirical analysis on various environments and with multiple algorithms to demonstrate that the exploration index yields insights about the exploration behaviour of any RL algorithm, and also allows us to compare the exploratory behaviours of different RL algorithms.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
Non-linear motor control by local learning in spiking neural networks
Dec 29, 2017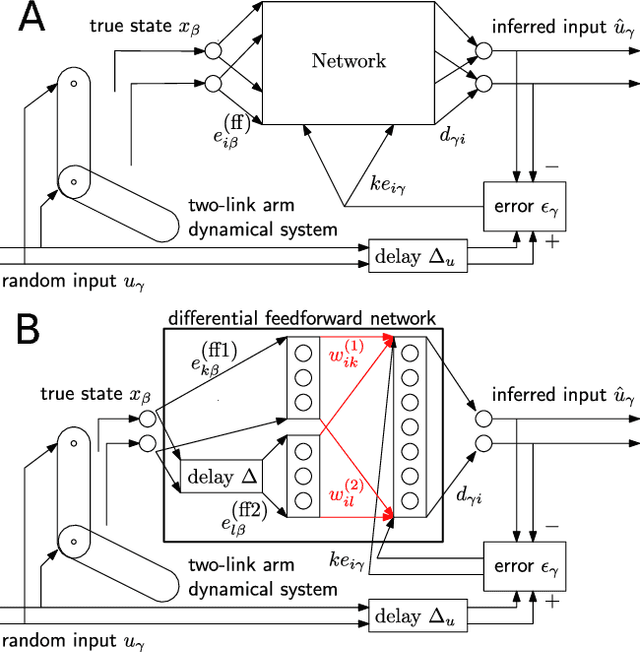
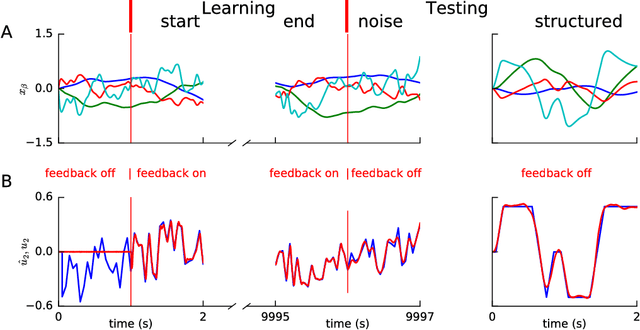
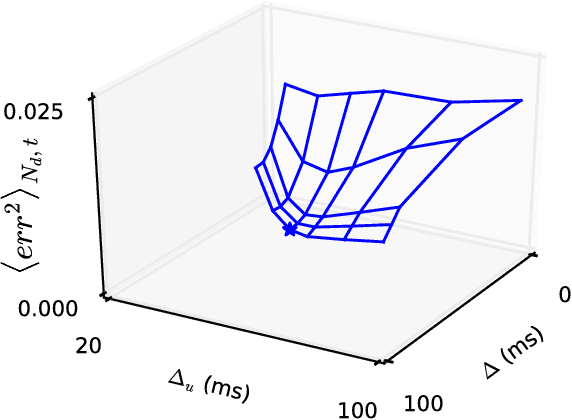

Learning weights in a spiking neural network with hidden neurons, using local, stable and online rules, to control non-linear body dynamics is an open problem. Here, we employ a supervised scheme, Feedback-based Online Local Learning Of Weights (FOLLOW), to train a network of heterogeneous spiking neurons with hidden layers, to control a two-link arm so as to reproduce a desired state trajectory. The network first learns an inverse model of the non-linear dynamics, i.e. from state trajectory as input to the network, it learns to infer the continuous-time command that produced the trajectory. Connection weights are adjusted via a local plasticity rule that involves pre-synaptic firing and post-synaptic feedback of the error in the inferred command. We choose a network architecture, termed differential feedforward, that gives the lowest test error from different feedforward and recurrent architectures. The learned inverse model is then used to generate a continuous-time motor command to control the arm, given a desired trajectory.
Multi-timescale memory dynamics in a reinforcement learning network with attention-gated memory
Dec 28, 2017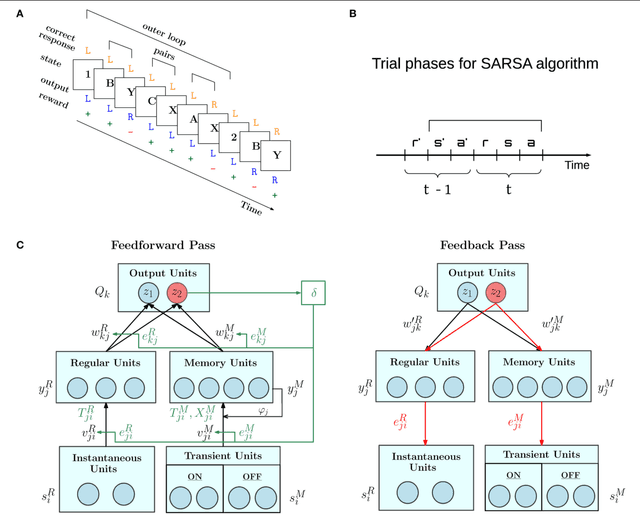



Learning and memory are intertwined in our brain and their relationship is at the core of several recent neural network models. In particular, the Attention-Gated MEmory Tagging model (AuGMEnT) is a reinforcement learning network with an emphasis on biological plausibility of memory dynamics and learning. We find that the AuGMEnT network does not solve some hierarchical tasks, where higher-level stimuli have to be maintained over a long time, while lower-level stimuli need to be remembered and forgotten over a shorter timescale. To overcome this limitation, we introduce hybrid AuGMEnT, with leaky or short-timescale and non-leaky or long-timescale units in memory, that allow to exchange lower-level information while maintaining higher-level one, thus solving both hierarchical and distractor tasks.
Predicting non-linear dynamics by stable local learning in a recurrent spiking neural network
Apr 26, 2017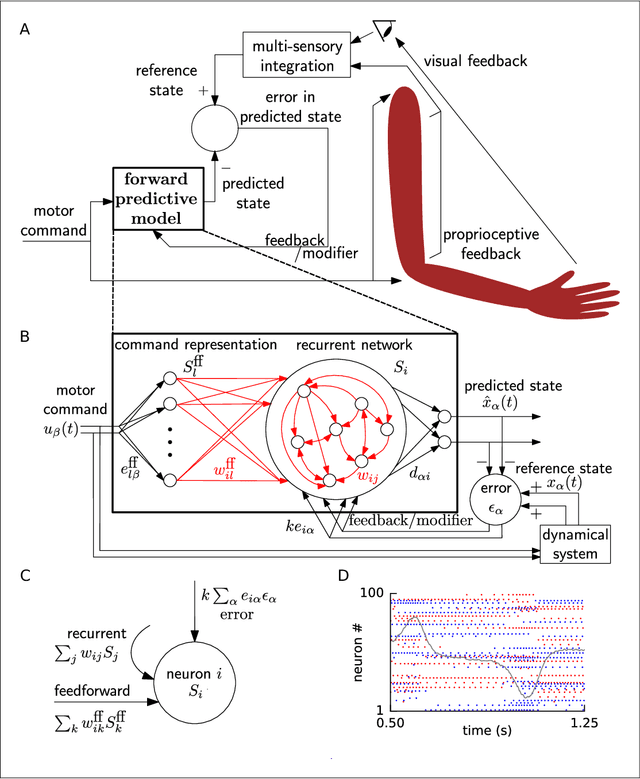
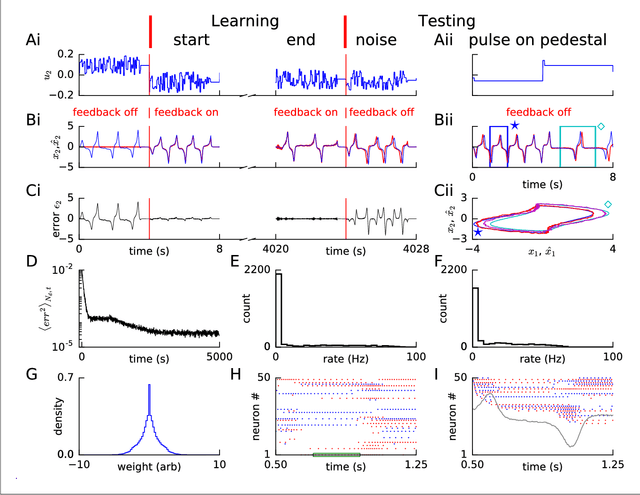

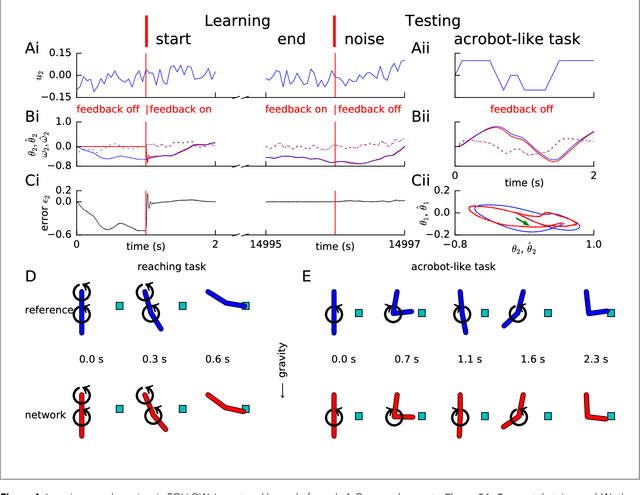
Brains need to predict how the body reacts to motor commands. It is an open question how networks of spiking neurons can learn to reproduce the non-linear body dynamics caused by motor commands, using local, online and stable learning rules. Here, we present a supervised learning scheme for the feedforward and recurrent connections in a network of heterogeneous spiking neurons. The error in the output is fed back through fixed random connections with a negative gain, causing the network to follow the desired dynamics, while an online and local rule changes the weights. The rule for Feedback-based Online Local Learning Of Weights (FOLLOW) is local in the sense that weight changes depend on the presynaptic activity and the error signal projected onto the postsynaptic neuron. We provide examples of learning linear, non-linear and chaotic dynamics, as well as the dynamics of a two-link arm. Using the Lyapunov method, and under reasonable assumptions and approximations, we show that FOLLOW learning is stable uniformly, with the error going to zero asymptotically.