 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Exploration in Reinforcement Learning via Optimal Transport in Policy Space
Feb 14, 2024



Exploration is the key ingredient of reinforcement learning (RL) that determines the speed and success of learning. Here, we quantify and compare the amount of exploration and learning accomplished by a Reinforcement Learning (RL) algorithm. Specifically, we propose a novel measure, named Exploration Index, that quantifies the relative effort of knowledge transfer (transferability) by an RL algorithm in comparison to supervised learning (SL) that transforms the initial data distribution of RL to the corresponding final data distribution. The comparison is established by formulating learning in RL as a sequence of SL tasks, and using optimal transport based metrics to compare the total path traversed by the RL and SL algorithms in the data distribution space. We perform extensive empirical analysis on various environments and with multiple algorithms to demonstrate that the exploration index yields insights about the exploration behaviour of any RL algorithm, and also allows us to compare the exploratory behaviours of different RL algorithms.
A Robotic Model of Hippocampal Reverse Replay for Reinforcement Learning
Feb 23, 2021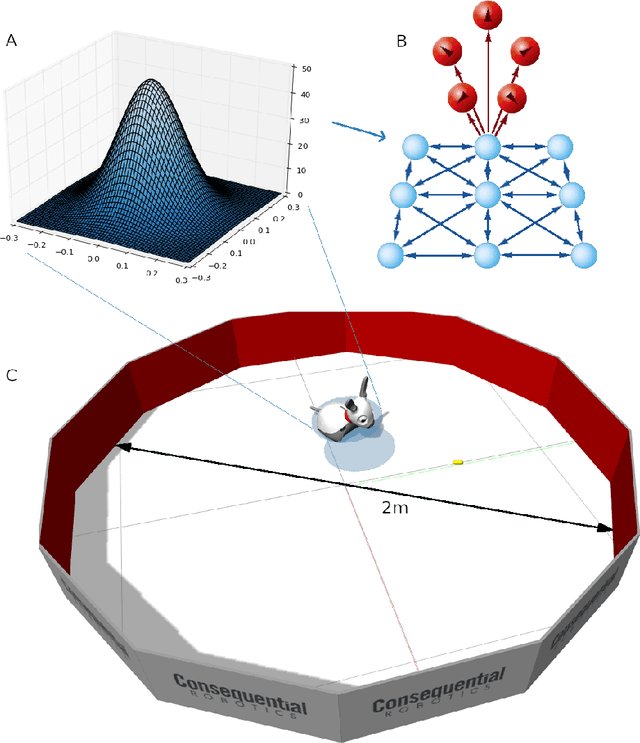


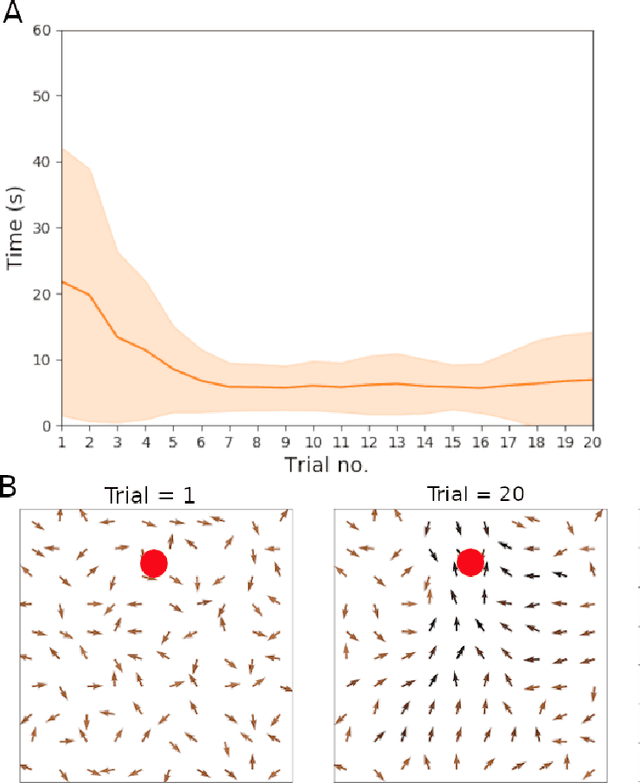
Hippocampal reverse replay is thought to contribute to learning, and particularly reinforcement learning, in animals. We present a computational model of learning in the hippocampus that builds on a previous model of the hippocampal-striatal network viewed as implementing a three-factor reinforcement learning rule. To augment this model with hippocampal reverse replay, a novel policy gradient learning rule is derived that associates place cell activity with responses in cells representing actions. This new model is evaluated using a simulated robot spatial navigation task inspired by the Morris water maze. Results show that reverse replay can accelerate learning from reinforcement, whilst improving stability and robustness over multiple trials. As implied by the neurobiological data, our study implies that reverse replay can make a significant positive contribution to reinforcement learning, although learning that is less efficient and less stable is possible in its absence. We conclude that reverse replay may enhance reinforcement learning in the mammalian hippocampal-striatal system rather than provide its core mechanism.
DAC-h3: A Proactive Robot Cognitive Architecture to Acquire and Express Knowledge About the World and the Self
Sep 18, 2017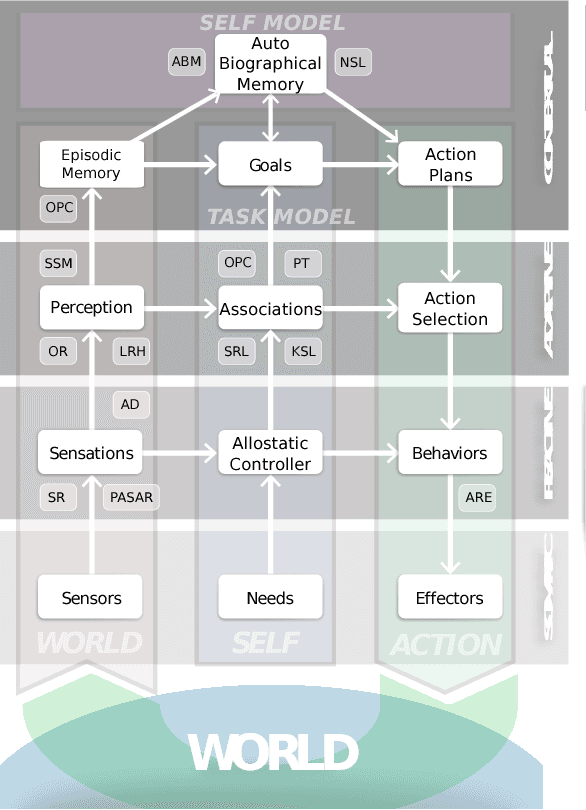


This paper introduces a cognitive architecture for a humanoid robot to engage in a proactive, mixed-initiative exploration and manipulation of its environment, where the initiative can originate from both the human and the robot. The framework, based on a biologically-grounded theory of the brain and mind, integrates a reactive interaction engine, a number of state-of-the-art perceptual and motor learning algorithms, as well as planning abilities and an autobiographical memory. The architecture as a whole drives the robot behavior to solve the symbol grounding problem, acquire language capabilities, execute goal-oriented behavior, and express a verbal narrative of its own experience in the world. We validate our approach in human-robot interaction experiments with the iCub humanoid robot, showing that the proposed cognitive architecture can be applied in real time within a realistic scenario and that it can be used with naive users.
* Preprint version; final version available at http://ieeexplore.ieee.org/ IEEE Transactions on Cognitive and Developmental Systems (Accepted) DOI: 10.1109/TCDS.2017.2754143
Automatic recognition of child speech for robotic applications in noisy environments
Nov 08, 2016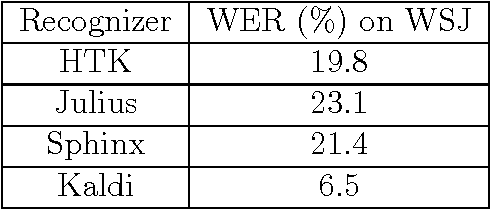



Automatic speech recognition (ASR) allows a natural and intuitive interface for robotic educational applications for children. However there are a number of challenges to overcome to allow such an interface to operate robustly in realistic settings, including the intrinsic difficulties of recognising child speech and high levels of background noise often present in classrooms. As part of the EU EASEL project we have provided several contributions to address these challenges, implementing our own ASR module for use in robotics applications. We used the latest deep neural network algorithms which provide a leap in performance over the traditional GMM approach, and apply data augmentation methods to improve robustness to noise and speaker variation. We provide a close integration between the ASR module and the rest of the dialogue system, allowing the ASR to receive in real-time the language models relevant to the current section of the dialogue, greatly improving the accuracy. We integrated our ASR module into an interactive, multimodal system using a small humanoid robot to help children learn about exercise and energy. The system was installed at a public museum event as part of a research study where 320 children (aged 3 to 14) interacted with the robot, with our ASR achieving 90% accuracy for fluent and near-fluent speech.