 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural ODE and SDE Models for Adaptation and Planning in Model-Based Reinforcement Learning
Mar 24, 2026We investigate neural ordinary and stochastic differential equations (neural ODEs and SDEs) to model stochastic dynamics in fully and partially observed environments within a model-based reinforcement learning (RL) framework. Through a sequence of simulations, we show that neural SDEs more effectively capture the inherent stochasticity of transition dynamics, enabling high-performing policies with improved sample efficiency in challenging scenarios. We leverage neural ODEs and SDEs for efficient policy adaptation to changes in environment dynamics via inverse models, requiring only limited interactions with the new environment. To address partial observability, we introduce a latent SDE model that combines an ODE with a GAN-trained stochastic component in latent space. Policies derived from this model provide a strong baseline, outperforming or matching general model-based and model-free approaches across stochastic continuous-control benchmarks. This work demonstrates the applicability of action-conditional latent SDEs for RL planning in environments with stochastic transitions. Our code is available at: https://github.com/ChaoHan-UoS/NeuralRL
Learning Nonlinear Heterogeneity in Physical Kolmogorov-Arnold Networks
Jan 25, 2026Physical neural networks typically train linear synaptic weights while treating device nonlinearities as fixed. We show the opposite - by training the synaptic nonlinearity itself, as in Kolmogorov-Arnold Network (KAN) architectures, we yield markedly higher task performance per physical resource and improved performance-parameter scaling than conventional linear weight-based networks, demonstrating ability of KAN topologies to exploit reconfigurable nonlinear physical dynamics. We experimentally realise physical KANs in silicon-on-insulator devices we term 'Synaptic Nonlinear Elements' (SYNEs), operating at room temperature, microampere currents, 2 MHz speeds and ~250 fJ per nonlinear operation, with no observed degradation over 10^13 measurements and months-long timescales. We demonstrate nonlinear function regression, classification, and prediction of Li-Ion battery dynamics from noisy real-world multi-sensor data. Physical KANs outperform equivalently-parameterised software multilayer perceptron networks across all tasks, with up to two orders of magnitude fewer parameters, and two orders of magnitude fewer devices than linear weight based physical networks. These results establish learned physical nonlinearity as a hardware-native computational primitive for compact and efficient learning systems, and SYNE devices as effective substrates for heterogenous nonlinear computing.
In Dialogue with Intelligence: Rethinking Large Language Models as Collective Knowledge
May 28, 2025Large Language Models (LLMs) are typically analysed through architectural, behavioural, or training-data lenses. This article offers a theoretical and experiential re-framing: LLMs as dynamic instantiations of Collective human Knowledge (CK), where intelligence is evoked through dialogue rather than stored statically. Drawing on concepts from neuroscience and AI, and grounded in sustained interaction with ChatGPT-4, I examine emergent dialogue patterns, the implications of fine-tuning, and the notion of co-augmentation: mutual enhancement between human and machine cognition. This perspective offers a new lens for understanding interaction, representation, and agency in contemporary AI systems.
Dynamical-VAE-based Hindsight to Learn the Causal Dynamics of Factored-POMDPs
Nov 12, 2024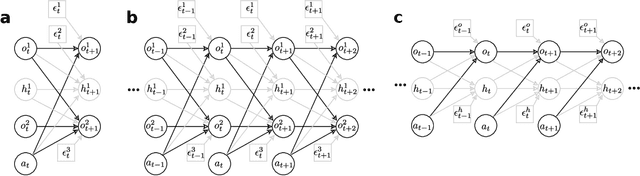
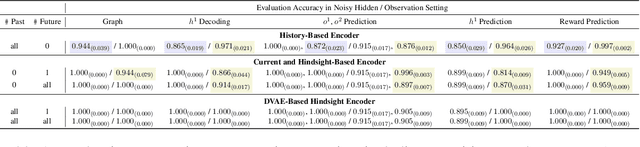
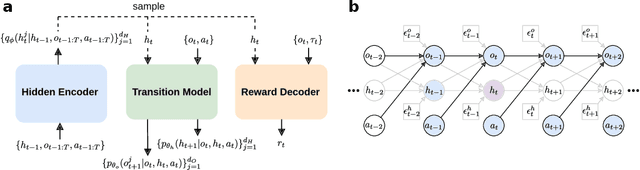
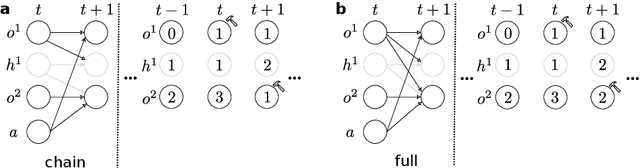
Learning representations of underlying environmental dynamics from partial observations is a critical challenge in machine learning. In the context of Partially Observable Markov Decision Processes (POMDPs), state representations are often inferred from the history of past observations and actions. We demonstrate that incorporating future information is essential to accurately capture causal dynamics and enhance state representations. To address this, we introduce a Dynamical Variational Auto-Encoder (DVAE) designed to learn causal Markovian dynamics from offline trajectories in a POMDP. Our method employs an extended hindsight framework that integrates past, current, and multi-step future information within a factored-POMDP setting. Empirical results reveal that this approach uncovers the causal graph governing hidden state transitions more effectively than history-based and typical hindsight-based models.
Optimising network interactions through device agnostic models
Jan 14, 2024Physically implemented neural networks hold the potential to achieve the performance of deep learning models by exploiting the innate physical properties of devices as computational tools. This exploration of physical processes for computation requires to also consider their intrinsic dynamics, which can serve as valuable resources to process information. However, existing computational methods are unable to extend the success of deep learning techniques to parameters influencing device dynamics, which often lack a precise mathematical description. In this work, we formulate a universal framework to optimise interactions with dynamic physical systems in a fully data-driven fashion. The framework adopts neural stochastic differential equations as differentiable digital twins, effectively capturing both deterministic and stochastic behaviours of devices. Employing differentiation through the trained models provides the essential mathematical estimates for optimizing a physical neural network, harnessing the intrinsic temporal computation abilities of its physical nodes. To accurately model real devices' behaviours, we formulated neural-SDE variants that can operate under a variety of experimental settings. Our work demonstrates the framework's applicability through simulations and physical implementations of interacting dynamic devices, while highlighting the importance of accurately capturing system stochasticity for the successful deployment of a physically defined neural network.
Machine learning using magnetic stochastic synapses
Mar 03, 2023The impressive performance of artificial neural networks has come at the cost of high energy usage and CO$_2$ emissions. Unconventional computing architectures, with magnetic systems as a candidate, have potential as alternative energy-efficient hardware, but, still face challenges, such as stochastic behaviour, in implementation. Here, we present a methodology for exploiting the traditionally detrimental stochastic effects in magnetic domain-wall motion in nanowires. We demonstrate functional binary stochastic synapses alongside a gradient learning rule that allows their training with applicability to a range of stochastic systems. The rule, utilising the mean and variance of the neuronal output distribution, finds a trade-off between synaptic stochasticity and energy efficiency depending on the number of measurements of each synapse. For single measurements, the rule results in binary synapses with minimal stochasticity, sacrificing potential performance for robustness. For multiple measurements, synaptic distributions are broad, approximating better-performing continuous synapses. This observation allows us to choose design principles depending on the desired performance and the device's operational speed and energy cost. We verify performance on physical hardware, showing it is comparable to a standard neural network.
A perspective on physical reservoir computing with nanomagnetic devices
Dec 09, 2022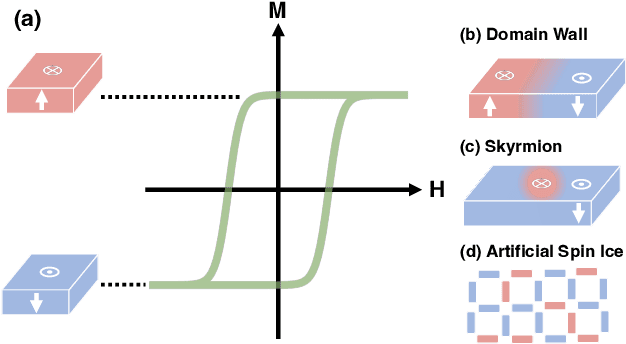
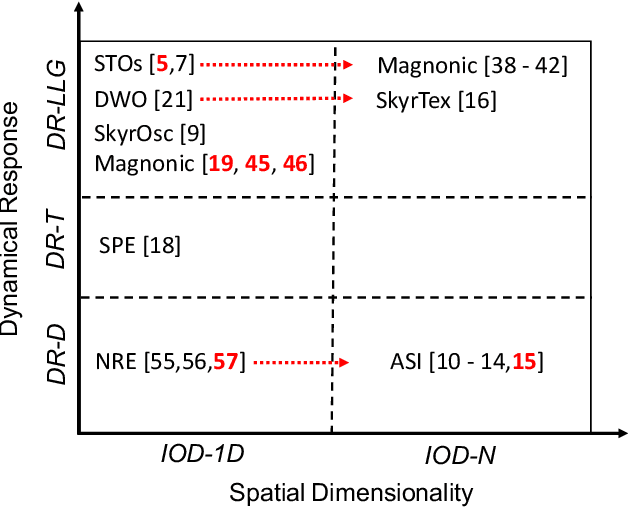
Neural networks have revolutionized the area of artificial intelligence and introduced transformative applications to almost every scientific field and industry. However, this success comes at a great price; the energy requirements for training advanced models are unsustainable. One promising way to address this pressing issue is by developing low-energy neuromorphic hardware that directly supports the algorithm's requirements. The intrinsic non-volatility, non-linearity, and memory of spintronic devices make them appealing candidates for neuromorphic devices. Here we focus on the reservoir computing paradigm, a recurrent network with a simple training algorithm suitable for computation with spintronic devices since they can provide the properties of non-linearity and memory. We review technologies and methods for developing neuromorphic spintronic devices and conclude with critical open issues to address before such devices become widely used.
Quantifying the Computational Capability of a Nanomagnetic Reservoir Computing Platform with Emergent Magnetization Dynamics
Nov 29, 2021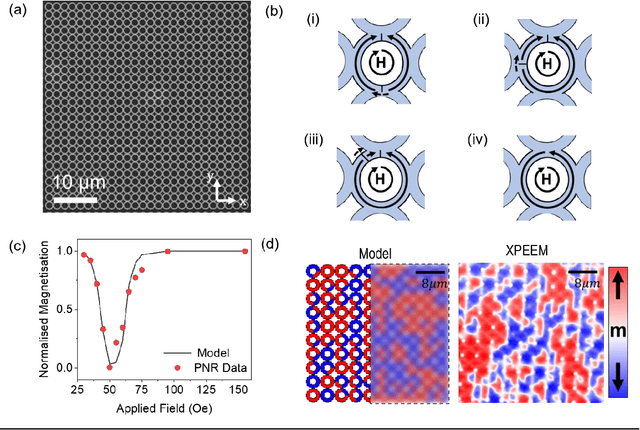
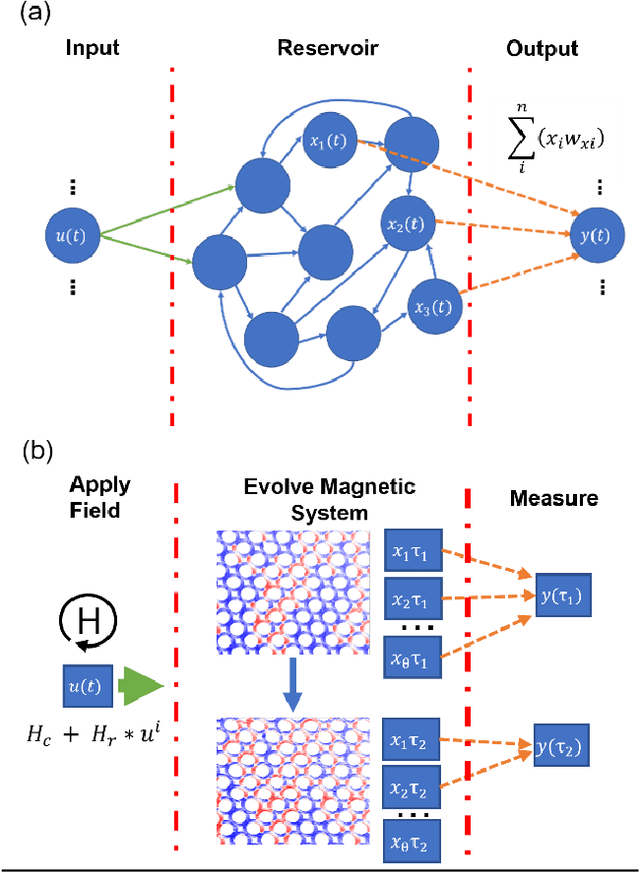
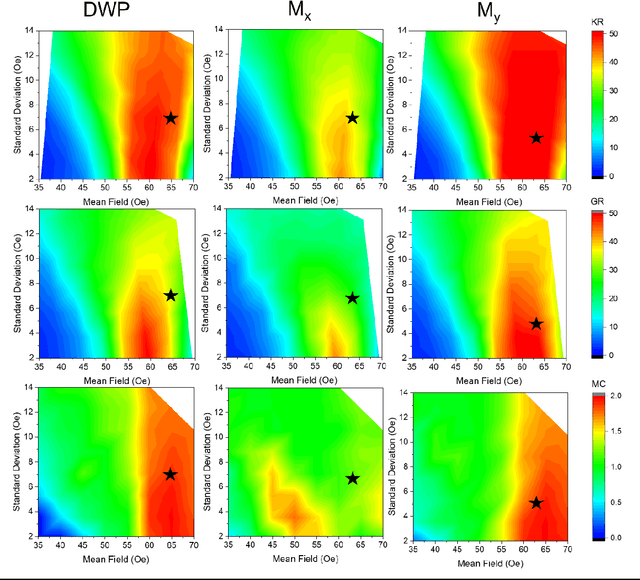
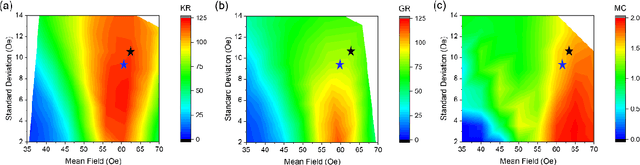
Arrays of interconnected magnetic nano-rings with emergent magnetization dynamics have recently been proposed for use in reservoir computing applications, but for them to be computationally useful it must be possible to optimise their dynamical responses. Here, we use a phenomenological model to demonstrate that such reservoirs can be optimised for classification tasks by tuning hyperparameters that control the scaling and input-rate of data into the system using rotating magnetic fields. We use task-independent metrics to assess the rings' computational capabilities at each set of these hyperparameters and show how these metrics correlate directly to performance in spoken and written digit recognition tasks. We then show that these metrics can be further improved by expanding the reservoir's output to include multiple, concurrent measures of the ring arrays' magnetic states.
EchoVPR: Echo State Networks for Visual Place Recognition
Oct 11, 2021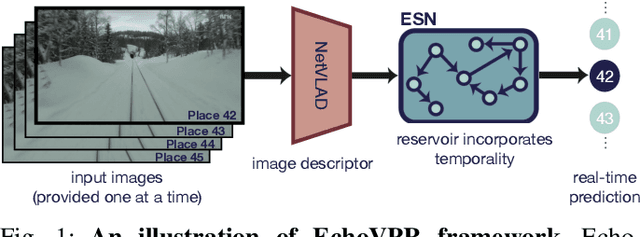

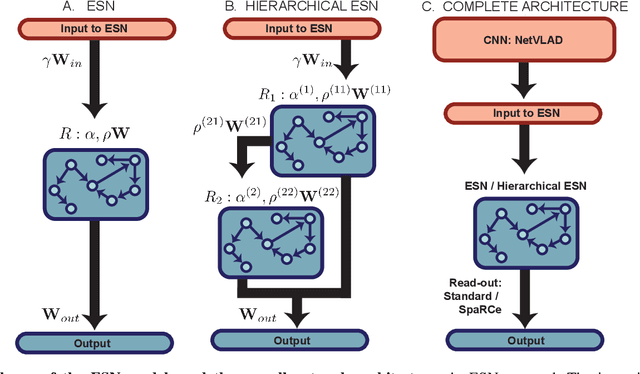
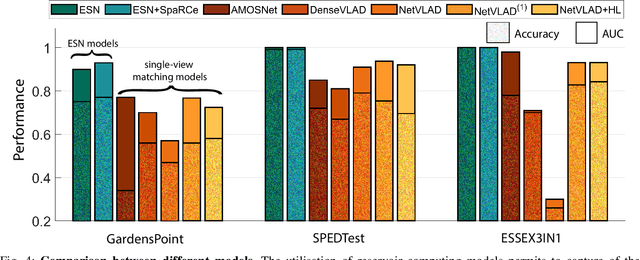
Recognising previously visited locations is an important, but unsolved, task in autonomous navigation. Current visual place recognition (VPR) benchmarks typically challenge models to recover the position of a query image (or images) from sequential datasets that include both spatial and temporal components. Recently, Echo State Network (ESN) varieties have proven particularly powerful at solving machine learning tasks that require spatio-temporal modelling. These networks are simple, yet powerful neural architectures that -- exhibiting memory over multiple time-scales and non-linear high-dimensional representations -- can discover temporal relations in the data while still maintaining linearity in the learning. In this paper, we present a series of ESNs and analyse their applicability to the VPR problem. We report that the addition of ESNs to pre-processed convolutional neural networks led to a dramatic boost in performance in comparison to non-recurrent networks in four standard benchmarks (GardensPoint, SPEDTest, ESSEX3IN1, Nordland) demonstrating that ESNs are able to capture the temporal structure inherent in VPR problems. Moreover, we show that ESNs can outperform class-leading VPR models which also exploit the sequential dynamics of the data. Finally, our results demonstrate that ESNs also improve generalisation abilities, robustness, and accuracy further supporting their suitability to VPR applications.
A Robotic Model of Hippocampal Reverse Replay for Reinforcement Learning
Feb 23, 2021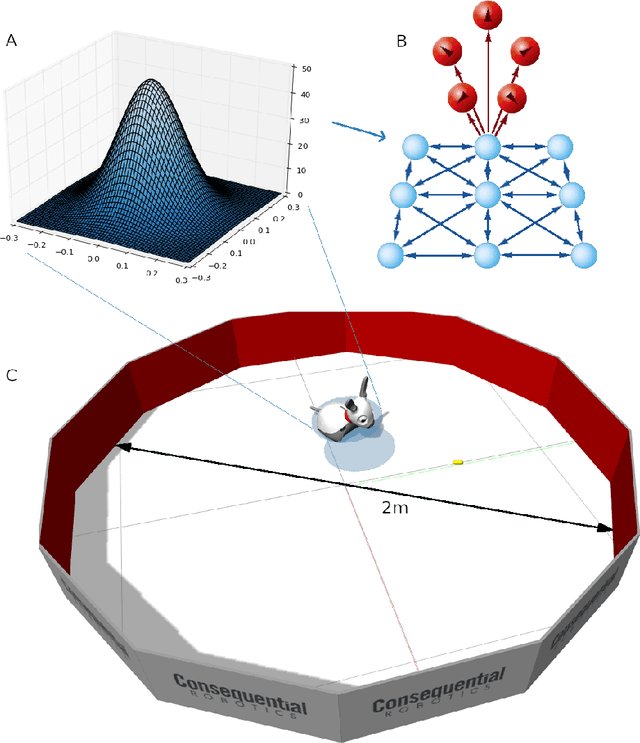


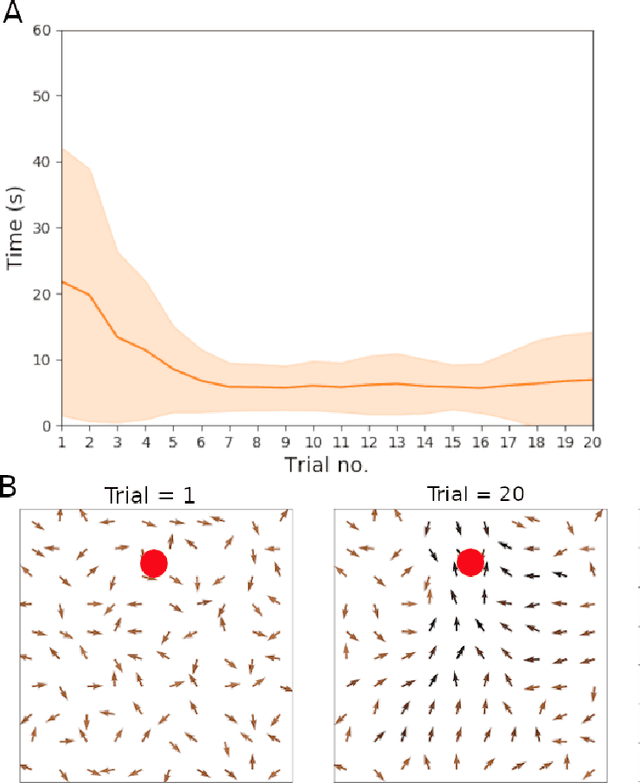
Hippocampal reverse replay is thought to contribute to learning, and particularly reinforcement learning, in animals. We present a computational model of learning in the hippocampus that builds on a previous model of the hippocampal-striatal network viewed as implementing a three-factor reinforcement learning rule. To augment this model with hippocampal reverse replay, a novel policy gradient learning rule is derived that associates place cell activity with responses in cells representing actions. This new model is evaluated using a simulated robot spatial navigation task inspired by the Morris water maze. Results show that reverse replay can accelerate learning from reinforcement, whilst improving stability and robustness over multiple trials. As implied by the neurobiological data, our study implies that reverse replay can make a significant positive contribution to reinforcement learning, although learning that is less efficient and less stable is possible in its absence. We conclude that reverse replay may enhance reinforcement learning in the mammalian hippocampal-striatal system rather than provide its core mechanism.