 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Multiple Timescales in Hierarchical Echo State Networks
Jan 14, 2021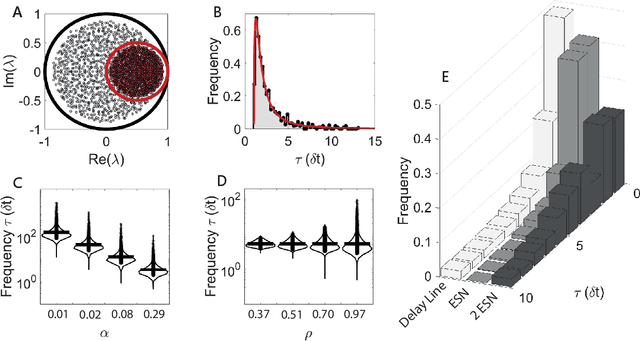
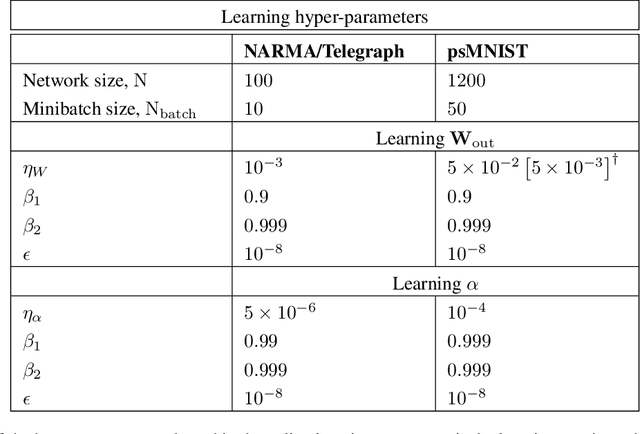
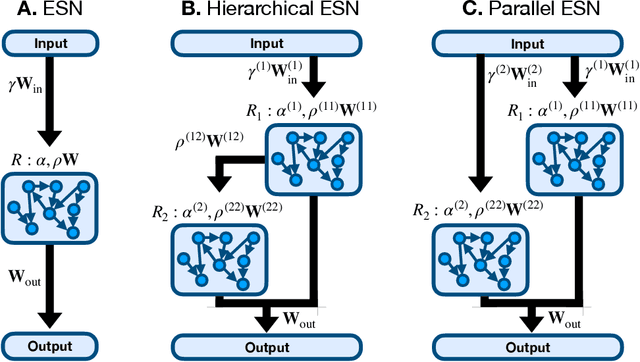
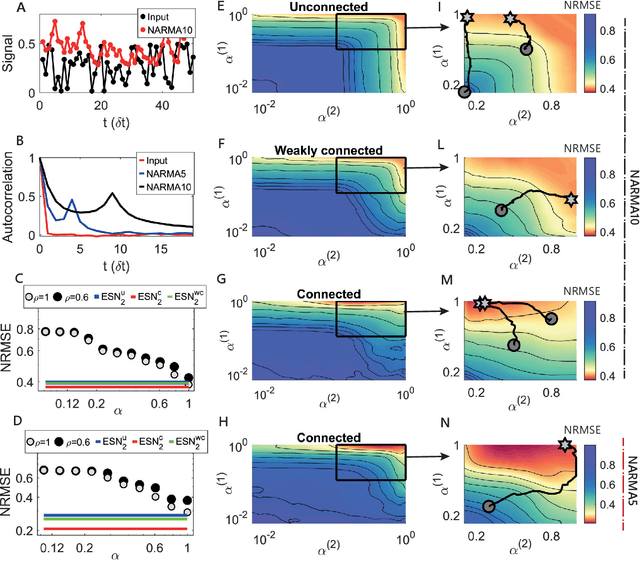
Echo state networks (ESNs) are a powerful form of reservoir computing that only require training of linear output weights whilst the internal reservoir is formed of fixed randomly connected neurons. With a correctly scaled connectivity matrix, the neurons' activity exhibits the echo-state property and responds to the input dynamics with certain timescales. Tuning the timescales of the network can be necessary for treating certain tasks, and some environments require multiple timescales for an efficient representation. Here we explore the timescales in hierarchical ESNs, where the reservoir is partitioned into two smaller linked reservoirs with distinct properties. Over three different tasks (NARMA10, a reconstruction task in a volatile environment, and psMNIST), we show that by selecting the hyper-parameters of each partition such that they focus on different timescales, we achieve a significant performance improvement over a single ESN. Through a linear analysis, and under the assumption that the timescales of the first partition are much shorter than the second's (typically corresponding to optimal operating conditions), we interpret the feedforward coupling of the partitions in terms of an effective representation of the input signal, provided by the first partition to the second, whereby the instantaneous input signal is expanded into a weighted combination of its time derivatives. Furthermore, we propose a data-driven approach to optimise the hyper-parameters through a gradient descent optimisation method that is an online approximation of backpropagation through time. We demonstrate the application of the online learning rule across all the tasks considered.
Scaling of a large-scale simulation of synchronous slow-wave and asynchronous awake-like activity of a cortical model with long-range interconnections
Feb 22, 2019
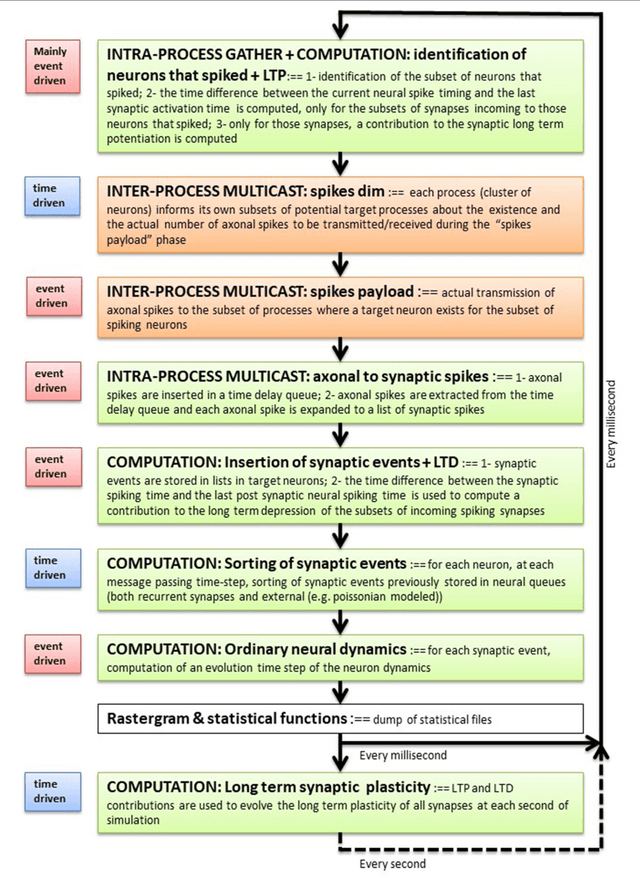
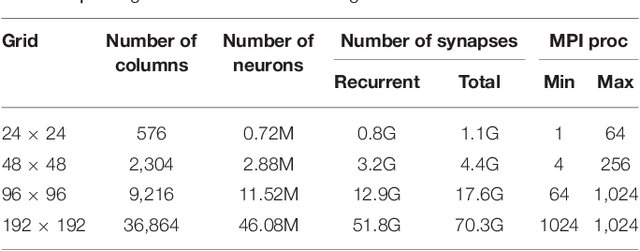
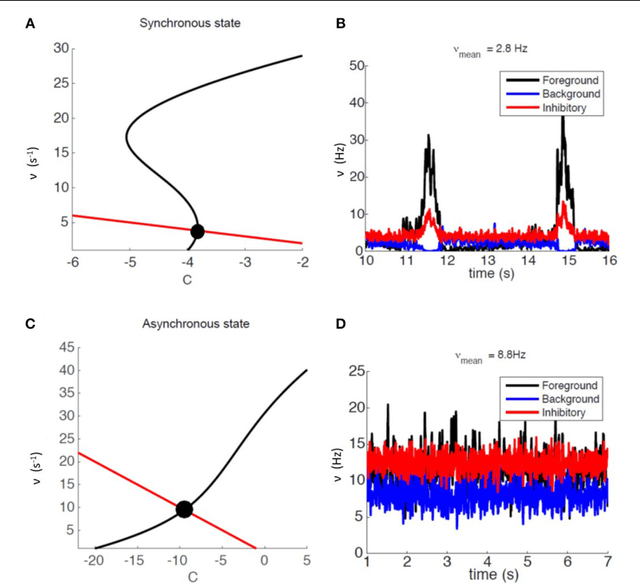
Cortical synapse organization supports a range of dynamic states on multiple spatial and temporal scales, from synchronous slow wave activity (SWA), characteristic of deep sleep or anesthesia, to fluctuating, asynchronous activity during wakefulness (AW). Such dynamic diversity poses a challenge for producing efficient large-scale simulations that embody realistic metaphors of short- and long-range synaptic connectivity. In fact, during SWA and AW different spatial extents of the cortical tissue are active in a given timespan and at different levels, which implies a wide variety of loads of local computation and communication. A balanced evaluation of simulation performance and robustness should therefore include tests of a variety of cortical dynamic states. Here, we demonstrate performance scaling of our proprietary Distributed and Plastic Spiking Neural Networks (DPSNN) simulation engine in both SWA and AW for bidimensional grids of neural populations, which reflects the modular organization of the cortex. We explored networks up to 192x192 modules, each composed of 1250 integrate-and-fire neurons with spike-frequency adaptation, and exponentially decaying inter-modular synaptic connectivity with varying spatial decay constant. For the largest networks the total number of synapses was over 70 billion. The execution platform included up to 64 dual-socket nodes, each socket mounting 8 Intel Xeon Haswell processor cores @ 2.40GHz clock. Network initialization time, memory usage, and execution time showed good scaling performances from 1 to 1024 processes, implemented using the standard Message Passing Interface (MPI) protocol. We achieved simulation speeds of between 2.3x10^9 and 4.1x10^9 synaptic events per second for both cortical states in the explored range of inter-modular interconnections.