 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Construction of Spiking Neural Networks using up to thousands of GPUs
Dec 10, 2025



Diverse scientific and engineering research areas deal with discrete, time-stamped changes in large systems of interacting delay differential equations. Simulating such complex systems at scale on high-performance computing clusters demands efficient management of communication and memory. Inspired by the human cerebral cortex -- a sparsely connected network of $\mathcal{O}(10^{10})$ neurons, each forming $\mathcal{O}(10^{3})$--$\mathcal{O}(10^{4})$ synapses and communicating via short electrical pulses called spikes -- we study the simulation of large-scale spiking neural networks for computational neuroscience research. This work presents a novel network construction method for multi-GPU clusters and upcoming exascale supercomputers using the Message Passing Interface (MPI), where each process builds its local connectivity and prepares the data structures for efficient spike exchange across the cluster during state propagation. We demonstrate scaling performance of two cortical models using point-to-point and collective communication, respectively.
Two-compartment neuronal spiking model expressing brain-state specific apical-amplification, -isolation and -drive regimes
Nov 10, 2023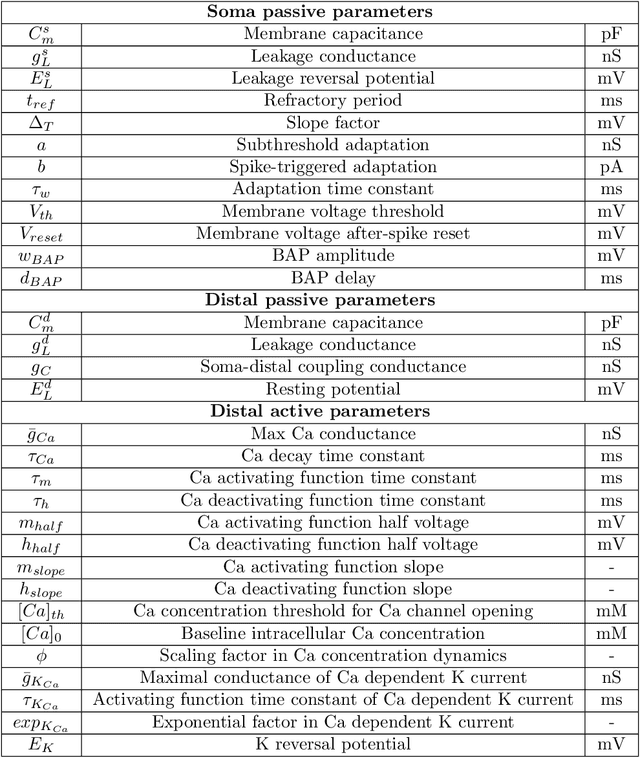
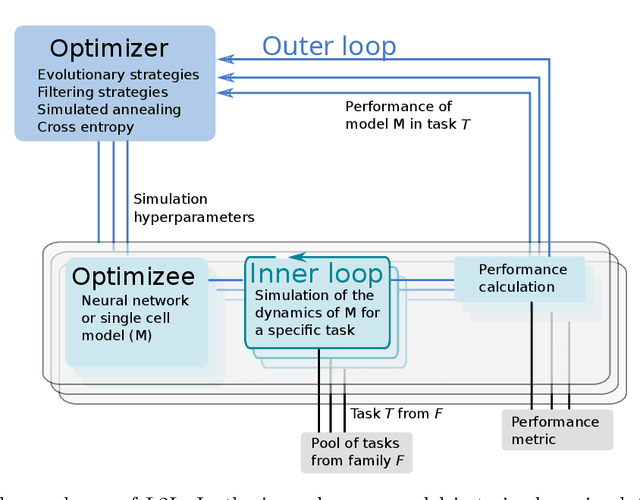
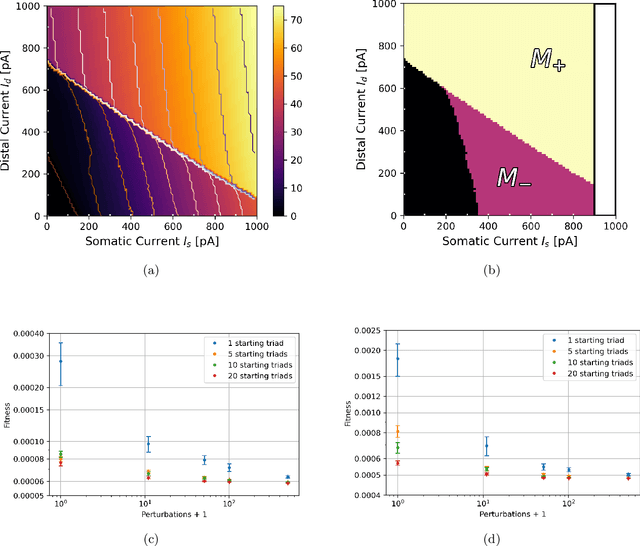

There is mounting experimental evidence that brain-state specific neural mechanisms supported by connectomic architectures serve to combine past and contextual knowledge with current, incoming flow of evidence (e.g. from sensory systems). Such mechanisms are distributed across multiple spatial and temporal scales and require dedicated support at the levels of individual neurons and synapses. A prominent feature in the neocortex is the structure of large, deep pyramidal neurons which show a peculiar separation between an apical dendritic compartment and a basal dentritic/peri-somatic compartment, with distinctive patterns of incoming connections and brain-state specific activation mechanisms, namely apical-amplification, -isolation and -drive associated to the wakefulness, deeper NREM sleep stages and REM sleep. The cognitive roles of apical mechanisms have been demonstrated in behaving animals. In contrast, classical models of learning spiking networks are based on single compartment neurons that miss the description of mechanisms to combine apical and basal/somatic information. This work aims to provide the computational community with a two-compartment spiking neuron model which includes features that are essential for supporting brain-state specific learning and with a piece-wise linear transfer function (ThetaPlanes) at highest abstraction level to be used in large scale bio-inspired artificial intelligence systems. A machine learning algorithm, constrained by a set of fitness functions, selected the parameters defining neurons expressing the desired apical mechanisms.
Runtime Construction of Large-Scale Spiking Neuronal Network Models on GPU Devices
Jun 16, 2023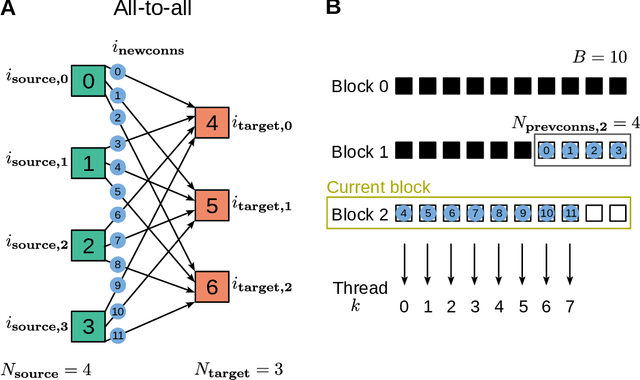
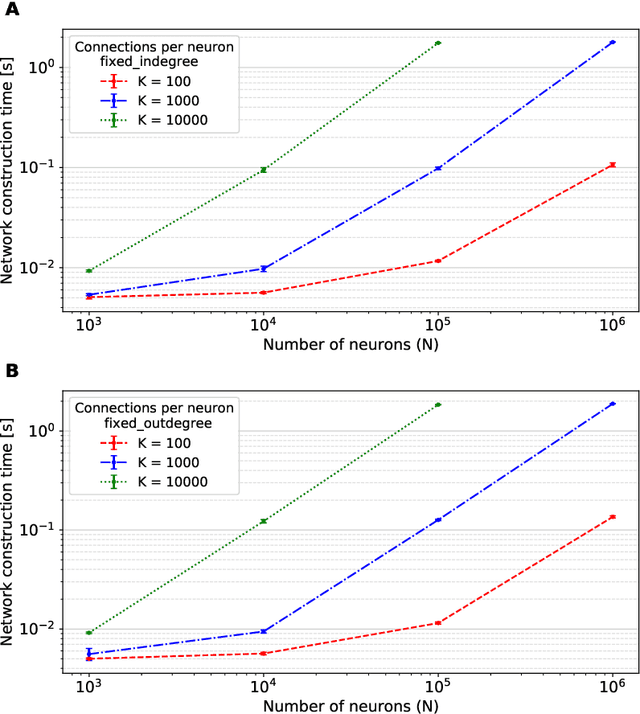


Simulation speed matters for neuroscientific research: this includes not only how quickly the simulated model time of a large-scale spiking neuronal network progresses, but also how long it takes to instantiate the network model in computer memory. On the hardware side, acceleration via highly parallel GPUs is being increasingly utilized. On the software side, code generation approaches ensure highly optimized code, at the expense of repeated code regeneration and recompilation after modifications to the network model. Aiming for a greater flexibility with respect to iterative model changes, here we propose a new method for creating network connections interactively, dynamically, and directly in GPU memory through a set of commonly used high-level connection rules. We validate the simulation performance with both consumer and data center GPUs on two neuroscientifically relevant models: a cortical microcircuit of about 77,000 leaky-integrate-and-fire neuron models and 300 million static synapses, and a two-population network recurrently connected using a variety of connection rules. With our proposed ad hoc network instantiation, both network construction and simulation times are comparable or shorter than those obtained with other state-of-the-art simulation technologies, while still meeting the flexibility demands of explorative network modeling.
A new GPU library for fast simulation of large-scale networks of spiking neurons
Jul 29, 2020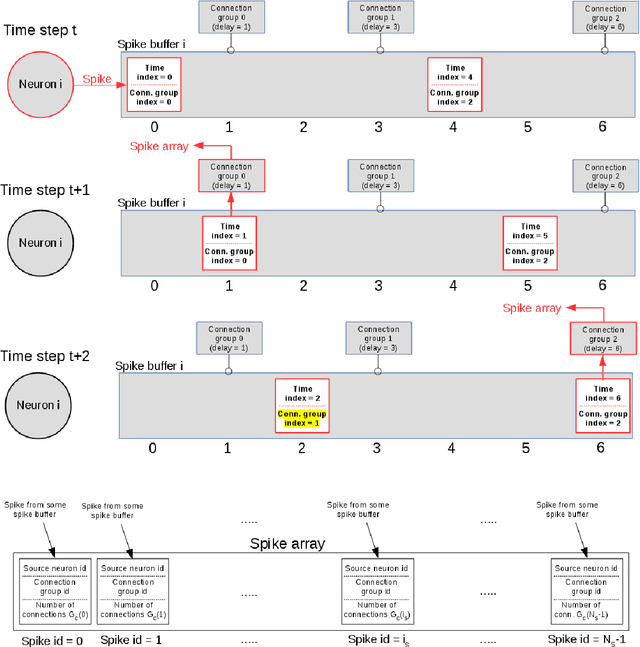
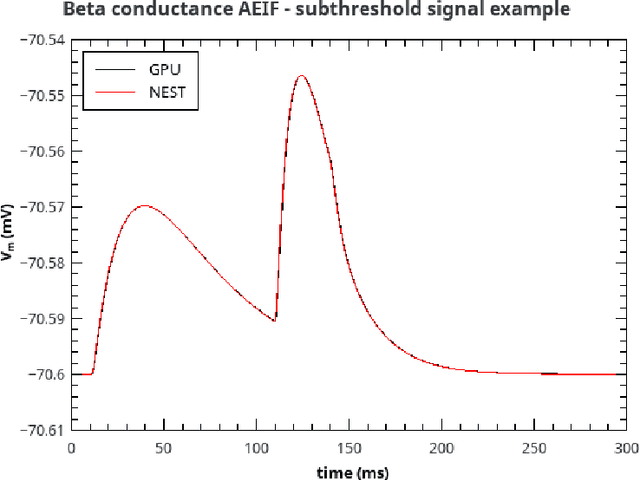
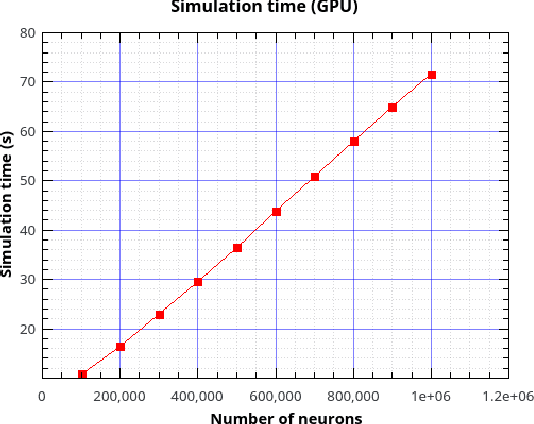

Over the past decade there has been a growing interest in the development of parallel hardware systems for simulating large-scale networks of spiking neurons. Compared to other highly-parallel systems, GPU-accelerated solutions have the advantage of a relatively low cost and a great versatility, thanks also to the possibility of using the CUDA-C/C++ programming languages. NeuronGPU is a GPU library for large-scale simulations of spiking neural network models, written in the C++ and CUDA-C++ programming languages, based on a novel spike-delivery algorithm. This library includes simple LIF (leaky-integrate-and-fire) neuron models as well as several multisynapse AdEx (adaptive-exponential-integrate-and-fire) neuron models with current or conductance based synapses, user definable models and different devices. The numerical solution of the differential equations of the dynamics of the AdEx models is performed through a parallel implementation, written in CUDA-C++, of the fifth-order Runge-Kutta method with adaptive step-size control. In this work we evaluate the performance of this library on the simulation of a well-known cortical microcircuit model, based on LIF neurons and current-based synapses, and on a balanced networks of excitatory and inhibitory neurons, using AdEx neurons and conductance-based synapses. On these models, we will show that the proposed library achieves state-of-the-art performance in terms of simulation time per second of biological activity. In particular, using a single NVIDIA GeForce RTX 2080 Ti GPU board, the full-scale cortical-microcircuit model, which includes about 77,000 neurons and $3 \cdot 10^8$ connections, can be simulated at a speed very close to real time, while the simulation time of a balanced network of 1,000,000 AdEx neurons with 1,000 connections per neuron was about 70 s per second of biological activity.
Scaling of a large-scale simulation of synchronous slow-wave and asynchronous awake-like activity of a cortical model with long-range interconnections
Feb 22, 2019
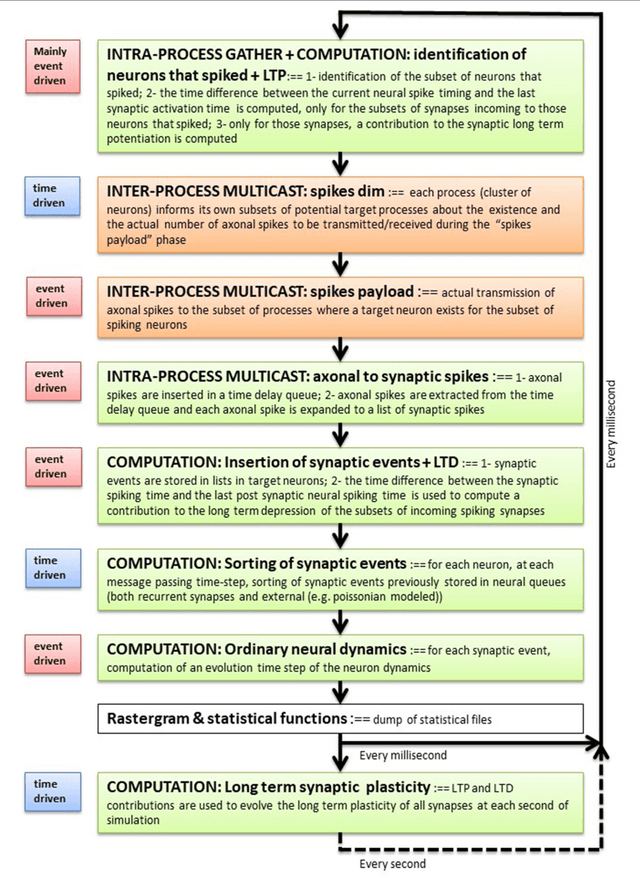
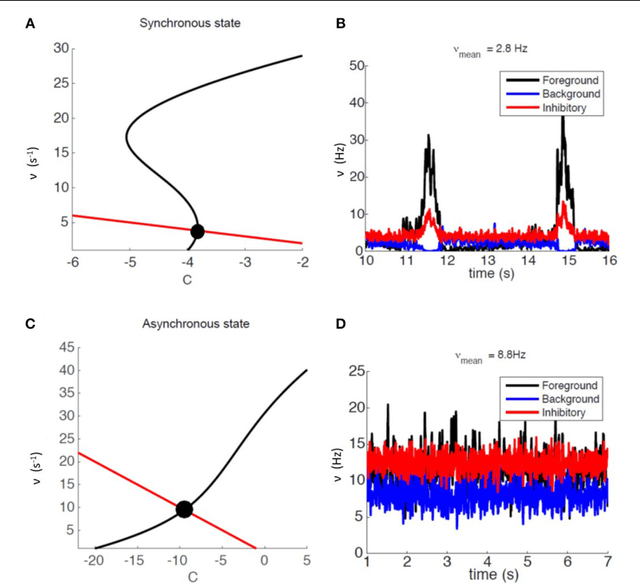
Cortical synapse organization supports a range of dynamic states on multiple spatial and temporal scales, from synchronous slow wave activity (SWA), characteristic of deep sleep or anesthesia, to fluctuating, asynchronous activity during wakefulness (AW). Such dynamic diversity poses a challenge for producing efficient large-scale simulations that embody realistic metaphors of short- and long-range synaptic connectivity. In fact, during SWA and AW different spatial extents of the cortical tissue are active in a given timespan and at different levels, which implies a wide variety of loads of local computation and communication. A balanced evaluation of simulation performance and robustness should therefore include tests of a variety of cortical dynamic states. Here, we demonstrate performance scaling of our proprietary Distributed and Plastic Spiking Neural Networks (DPSNN) simulation engine in both SWA and AW for bidimensional grids of neural populations, which reflects the modular organization of the cortex. We explored networks up to 192x192 modules, each composed of 1250 integrate-and-fire neurons with spike-frequency adaptation, and exponentially decaying inter-modular synaptic connectivity with varying spatial decay constant. For the largest networks the total number of synapses was over 70 billion. The execution platform included up to 64 dual-socket nodes, each socket mounting 8 Intel Xeon Haswell processor cores @ 2.40GHz clock. Network initialization time, memory usage, and execution time showed good scaling performances from 1 to 1024 processes, implemented using the standard Message Passing Interface (MPI) protocol. We achieved simulation speeds of between 2.3x10^9 and 4.1x10^9 synaptic events per second for both cortical states in the explored range of inter-modular interconnections.
Real-time cortical simulations: energy and interconnect scaling on distributed systems
Dec 27, 2018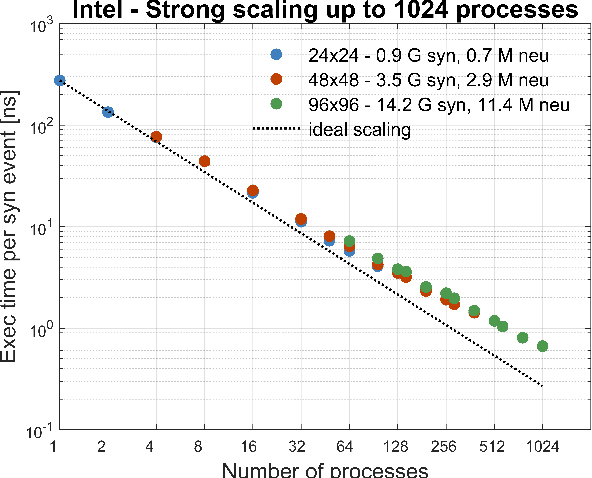
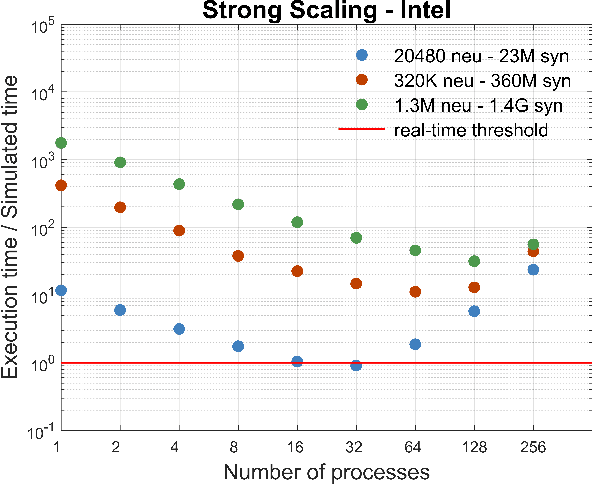
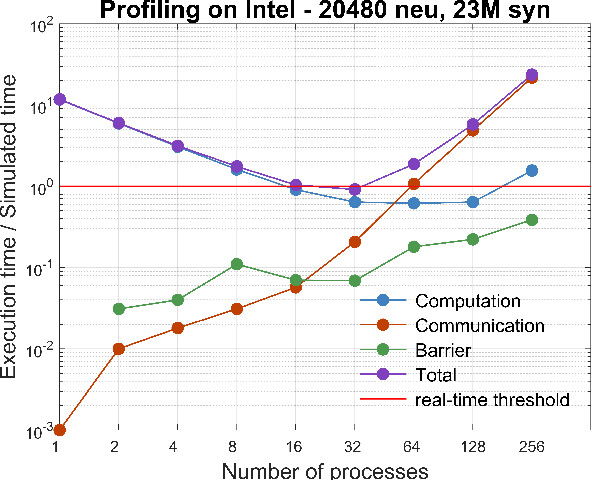
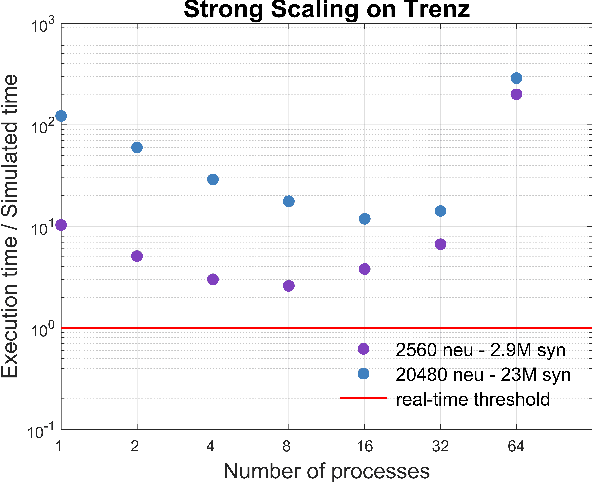
We profile the impact of computation and inter-processor communication on the energy consumption and on the scaling of cortical simulations approaching the real-time regime on distributed computing platforms. Also, the speed and energy consumption of processor architectures typical of standard HPC and embedded platforms are compared. We demonstrate the importance of the design of low-latency interconnect for speed and energy consumption. The cost of cortical simulations is quantified using the Joule per synaptic event metric on both architectures. Reaching efficient real-time on large scale cortical simulations is of increasing relevance for both future bio-inspired artificial intelligence applications and for understanding the cognitive functions of the brain, a scientific quest that will require to embed large scale simulations into highly complex virtual or real worlds. This work stands at the crossroads between the WaveScalES experiment in the Human Brain Project (HBP), which includes the objective of large scale thalamo-cortical simulations of brain states and their transitions, and the ExaNeSt and EuroExa projects, that investigate the design of an ARM-based, low-power High Performance Computing (HPC) architecture with a dedicated interconnect scalable to million of cores; simulation of deep sleep Slow Wave Activity (SWA) and Asynchronous aWake (AW) regimes expressed by thalamo-cortical models are among their benchmarks.
Sleep-like slow oscillations induce hierarchical memory association and synaptic homeostasis in thalamo-cortical simulations
Oct 24, 2018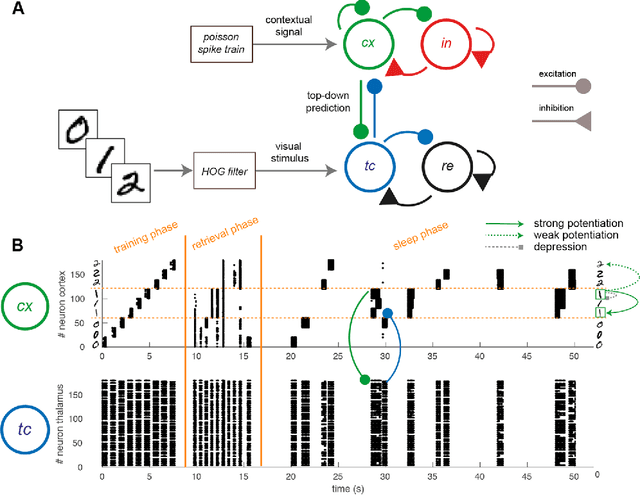
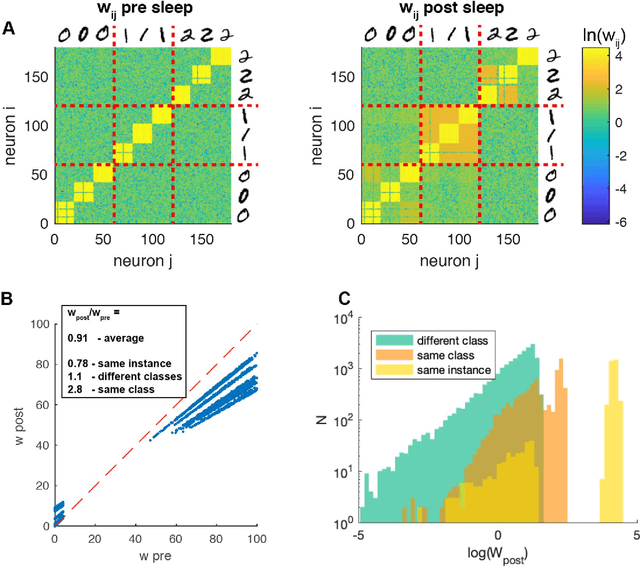
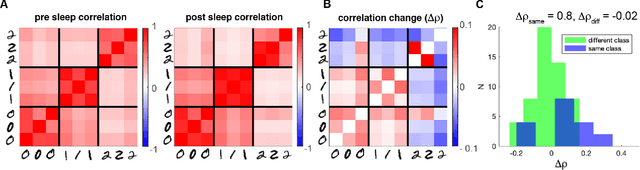
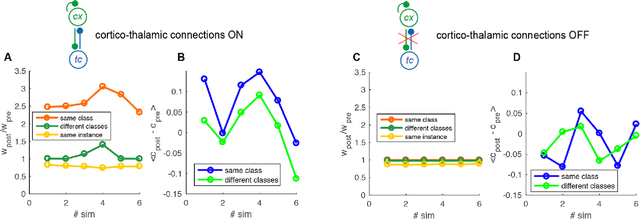
The occurrence of sleep is widespread over the large majority of animal species, suggesting a specific evolutionary strategy. The activity displayed in such a state is known to be beneficial for cognitive functions, stabilizing memories and improving the performances in several tasks. Despite this, a theoretical and computational approach to achieve the understanding of such mechanism is still lacking. In this paper we show the effect of sleep-like activity on a simplified thalamo-cortical model which is trained to encode and retrieve images of handwritten digits. We show that, if spike-timing-dependent-plasticity (STDP) is active during sleep, the connections among groups of neurons associated to instances of the same class (digit) are enhanced, and that the internal representation is hierarchical and orthogonalized. Such effect might be beneficial to the network to obtain better performances in retrieval and classification tasks and to create hierarchies of categories in integrated representations. The model leverages on the coincidence of top-down contextual information with bottom-up sensory flow during the training phase and on the integration of top-down predictions and bottom-up pathways during deep-sleep-like slow oscillations.
The Brain on Low Power Architectures - Efficient Simulation of Cortical Slow Waves and Asynchronous States
Apr 10, 2018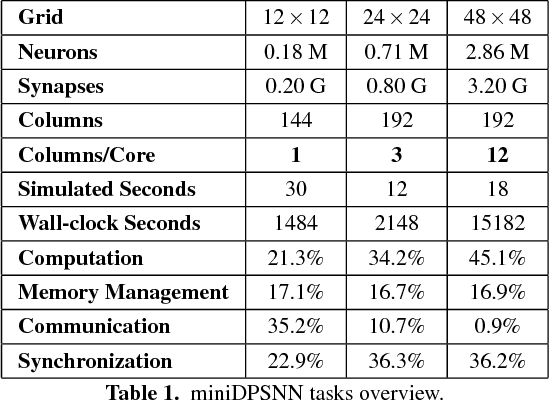
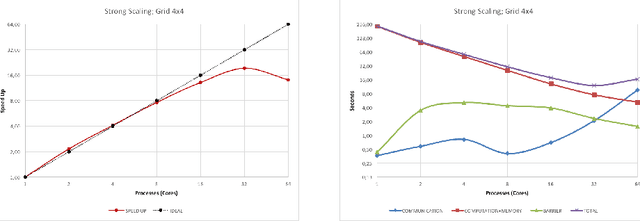
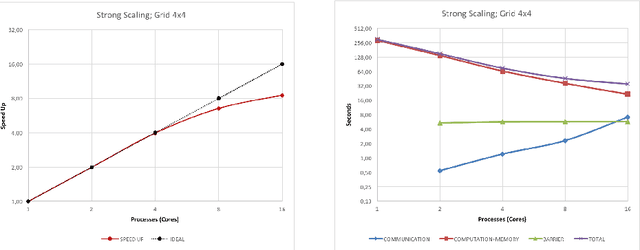
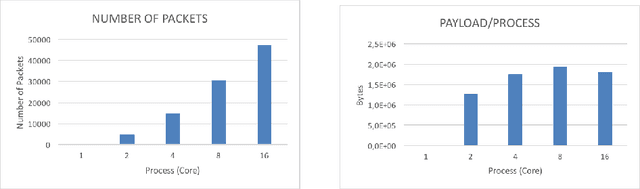
Efficient brain simulation is a scientific grand challenge, a parallel/distributed coding challenge and a source of requirements and suggestions for future computing architectures. Indeed, the human brain includes about 10^15 synapses and 10^11 neurons activated at a mean rate of several Hz. Full brain simulation poses Exascale challenges even if simulated at the highest abstraction level. The WaveScalES experiment in the Human Brain Project (HBP) has the goal of matching experimental measures and simulations of slow waves during deep-sleep and anesthesia and the transition to other brain states. The focus is the development of dedicated large-scale parallel/distributed simulation technologies. The ExaNeSt project designs an ARM-based, low-power HPC architecture scalable to million of cores, developing a dedicated scalable interconnect system, and SWA/AW simulations are included among the driving benchmarks. At the joint between both projects is the INFN proprietary Distributed and Plastic Spiking Neural Networks (DPSNN) simulation engine. DPSNN can be configured to stress either the networking or the computation features available on the execution platforms. The simulation stresses the networking component when the neural net - composed by a relatively low number of neurons, each one projecting thousands of synapses - is distributed over a large number of hardware cores. When growing the number of neurons per core, the computation starts to be the dominating component for short range connections. This paper reports about preliminary performance results obtained on an ARM-based HPC prototype developed in the framework of the ExaNeSt project. Furthermore, a comparison is given of instantaneous power, total energy consumption, execution time and energetic cost per synaptic event of SWA/AW DPSNN simulations when executed on either ARM- or Intel-based server platforms.
Gaussian and exponential lateral connectivity on distributed spiking neural network simulation
Mar 23, 2018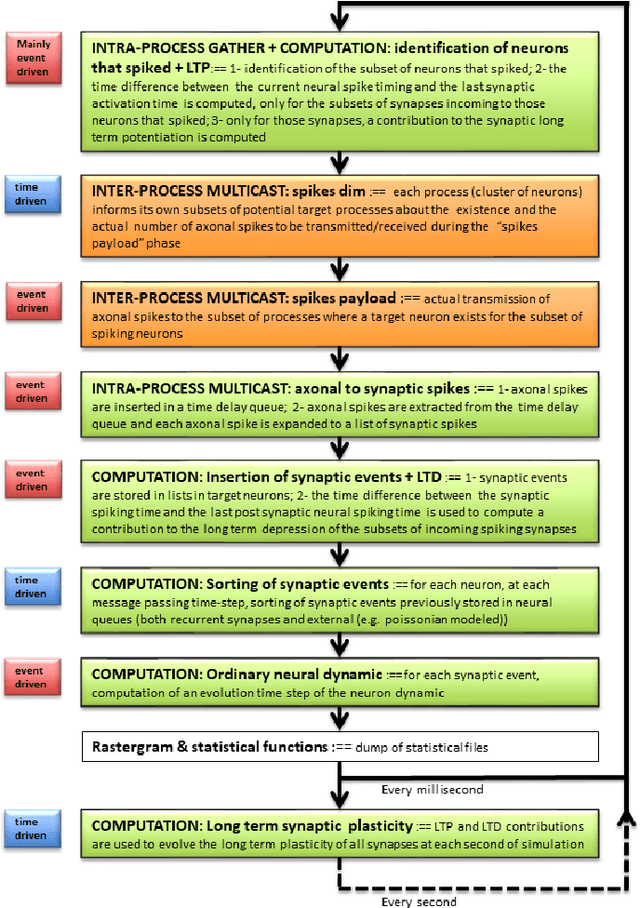
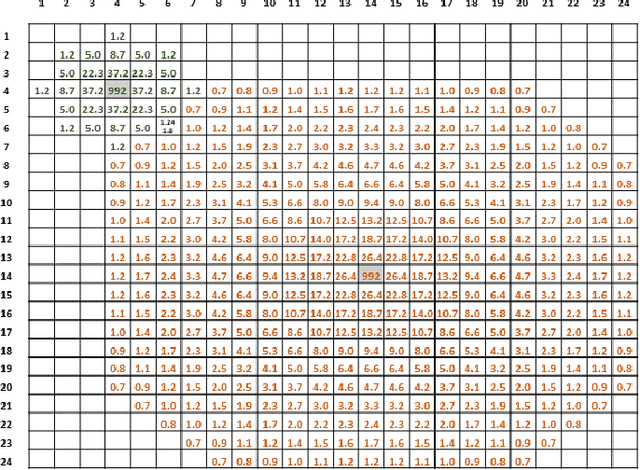
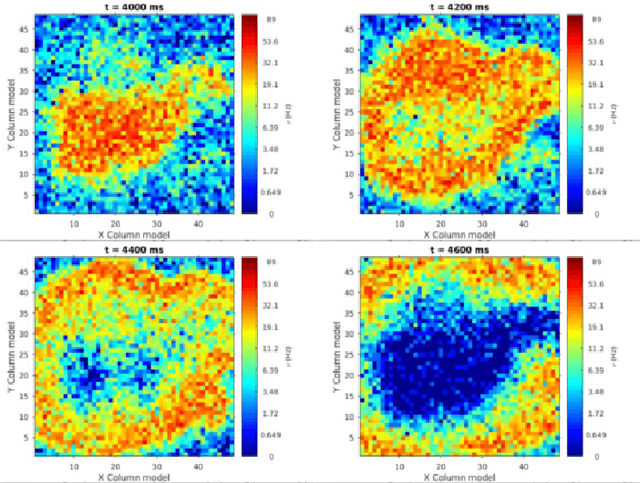
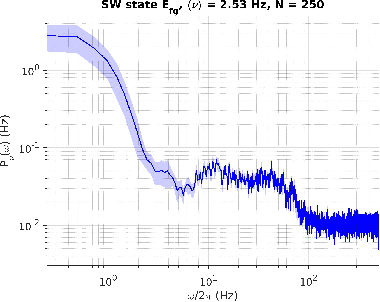
We measured the impact of long-range exponentially decaying intra-areal lateral connectivity on the scaling and memory occupation of a distributed spiking neural network simulator compared to that of short-range Gaussian decays. While previous studies adopted short-range connectivity, recent experimental neurosciences studies are pointing out the role of longer-range intra-areal connectivity with implications on neural simulation platforms. Two-dimensional grids of cortical columns composed by up to 11 M point-like spiking neurons with spike frequency adaption were connected by up to 30 G synapses using short- and long-range connectivity models. The MPI processes composing the distributed simulator were run on up to 1024 hardware cores, hosted on a 64 nodes server platform. The hardware platform was a cluster of IBM NX360 M5 16-core compute nodes, each one containing two Intel Xeon Haswell 8-core E5-2630 v3 processors, with a clock of 2.40 G Hz, interconnected through an InfiniBand network, equipped with 4x QDR switches.
EURETILE D7.3 - Dynamic DAL benchmark coding, measurements on MPI version of DPSNN-STDP (distributed plastic spiking neural net) and improvements to other DAL codes
Aug 20, 2014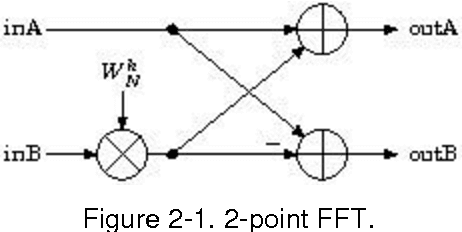
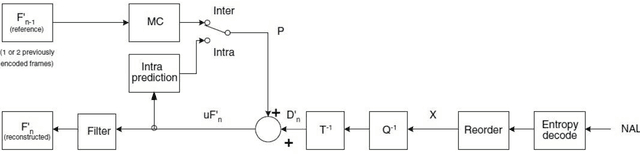
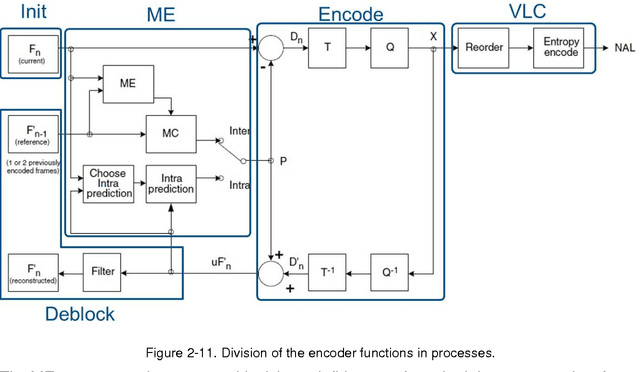
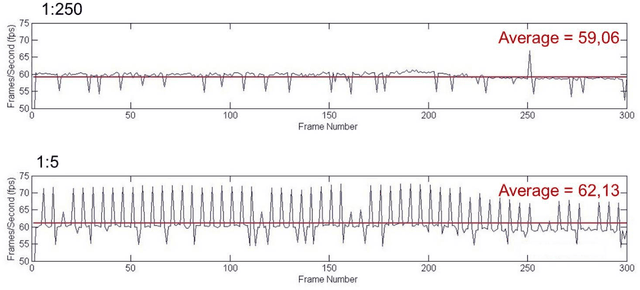
The EURETILE project required the selection and coding of a set of dedicated benchmarks. The project is about the software and hardware architecture of future many-tile distributed fault-tolerant systems. We focus on dynamic workloads characterised by heavy numerical processing requirements. The ambition is to identify common techniques that could be applied to both the Embedded Systems and HPC domains. This document is the first public deliverable of Work Package 7: Challenging Tiled Applications.