 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompeting Ratio Loss for Discriminative Multi-class Image Classification
Dec 25, 2019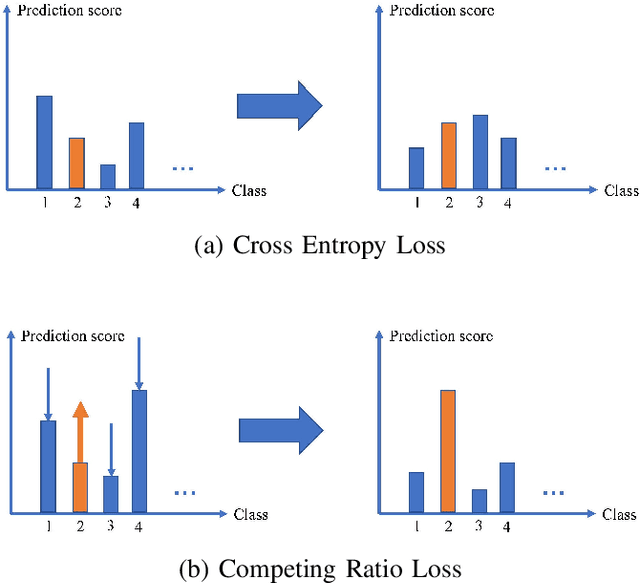
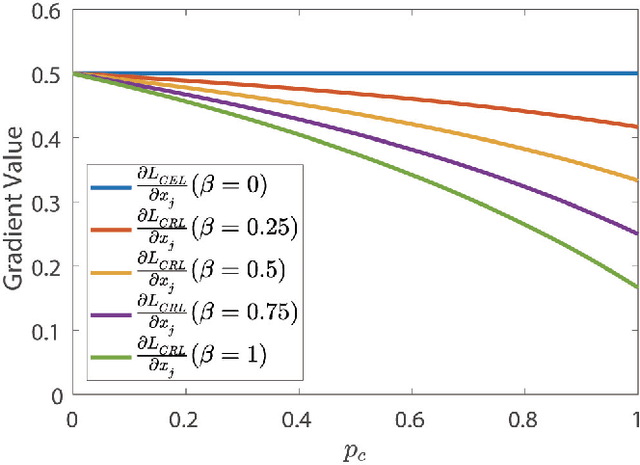
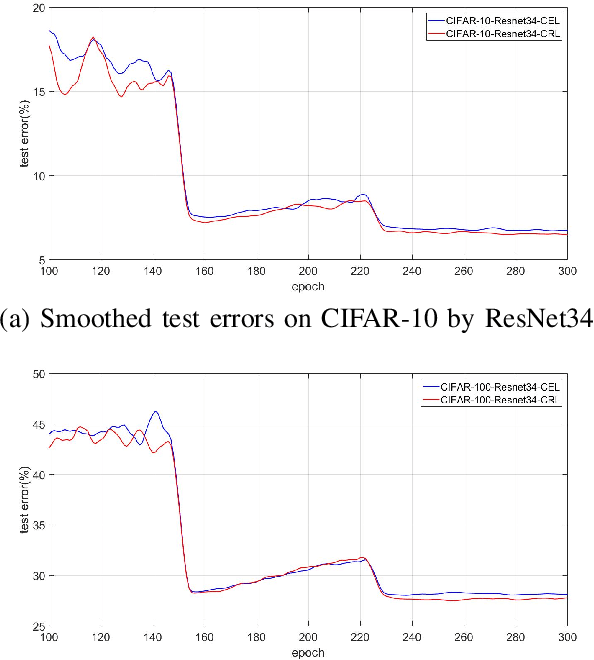

The development of deep convolutional neural network architecture is critical to the improvement of image classification task performance. Many image classification studies use deep convolutional neural network and focus on modifying the network structure to improve image classification performance. Conversely, our study focuses on loss function design. Cross-entropy Loss (CEL) has been widely used for training deep convolutional neural network for the task of multi-class classification. Although CEL has been successfully implemented in several image classification tasks, it only focuses on the posterior probability of the correct class. For this reason, a negative log likelihood ratio loss (NLLR) was proposed to better differentiate between the correct class and the competing incorrect ones. However, during the training of the deep convolutional neural network, the value of NLLR is not always positive or negative, which severely affects the convergence of NLLR. Our proposed competing ratio loss (CRL) calculates the posterior probability ratio between the correct class and the competing incorrect classes to further enlarge the probability difference between the correct and incorrect classes. We added hyperparameters to CRL, thereby ensuring its value to be positive and that the update size of backpropagation is suitable for the CRL's fast convergence. To demonstrate the performance of CRL, we conducted experiments on general image classification tasks (CIFAR10/100, SVHN, ImageNet), the fine-grained image classification tasks (CUB200-2011 and Stanford Car), and the challenging face age estimation task (using Adience). Experimental results show the effectiveness and robustness of the proposed loss function on different deep convolutional neural network architectures and different image classification tasks.
Age Group and Gender Estimation in the Wild with Deep RoR Architecture
Oct 09, 2017
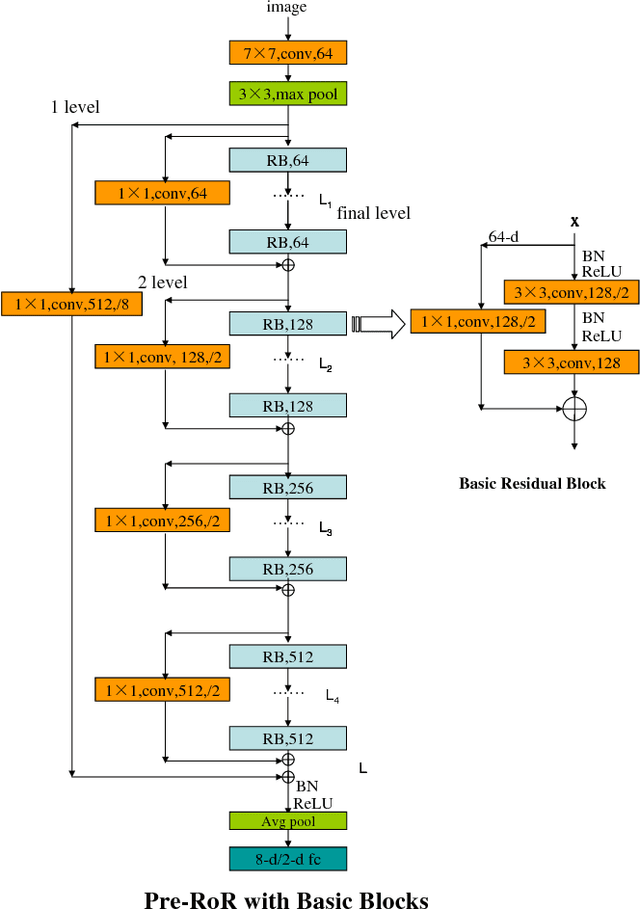
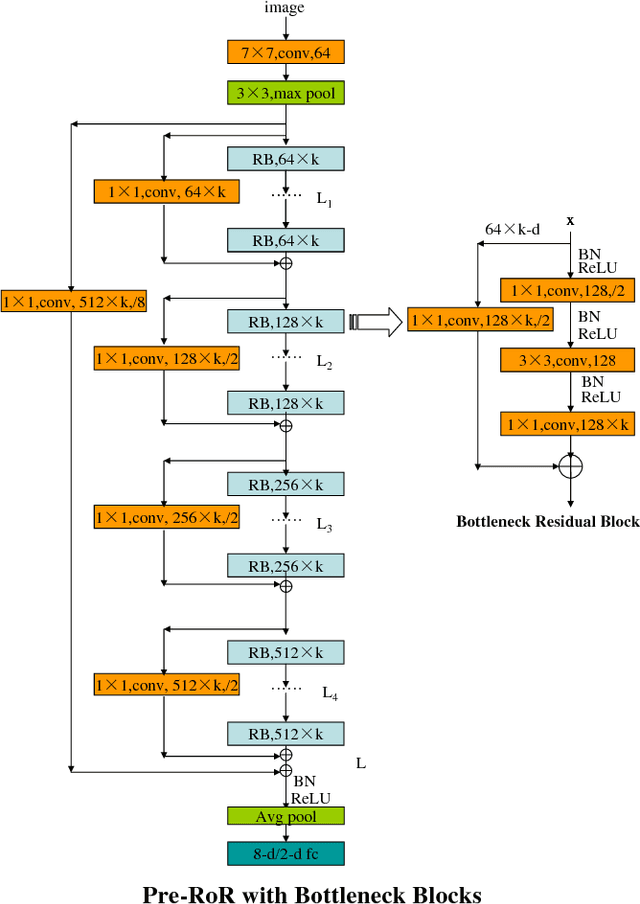
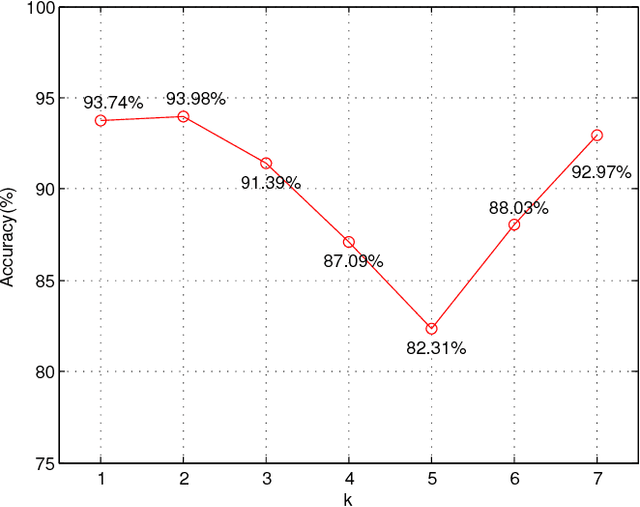
Automatically predicting age group and gender from face images acquired in unconstrained conditions is an important and challenging task in many real-world applications. Nevertheless, the conventional methods with manually-designed features on in-the-wild benchmarks are unsatisfactory because of incompetency to tackle large variations in unconstrained images. This difficulty is alleviated to some degree through Convolutional Neural Networks (CNN) for its powerful feature representation. In this paper, we propose a new CNN based method for age group and gender estimation leveraging Residual Networks of Residual Networks (RoR), which exhibits better optimization ability for age group and gender classification than other CNN architectures.Moreover, two modest mechanisms based on observation of the characteristics of age group are presented to further improve the performance of age estimation.In order to further improve the performance and alleviate over-fitting problem, RoR model is pre-trained on ImageNet firstly, and then it is fune-tuned on the IMDB-WIKI-101 data set for further learning the features of face images, finally, it is used to fine-tune on Adience data set. Our experiments illustrate the effectiveness of RoR method for age and gender estimation in the wild, where it achieves better performance than other CNN methods. Finally, the RoR-152+IMDB-WIKI-101 with two mechanisms achieves new state-of-the-art results on Adience benchmark.
Residual Networks of Residual Networks: Multilevel Residual Networks
Mar 05, 2017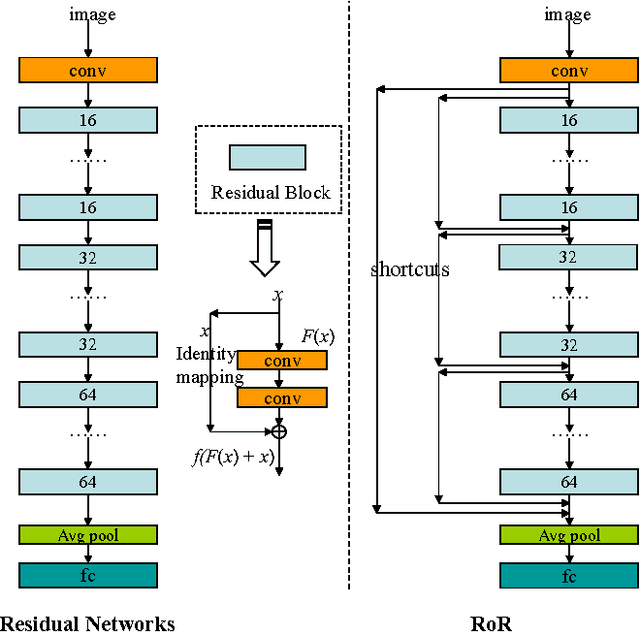
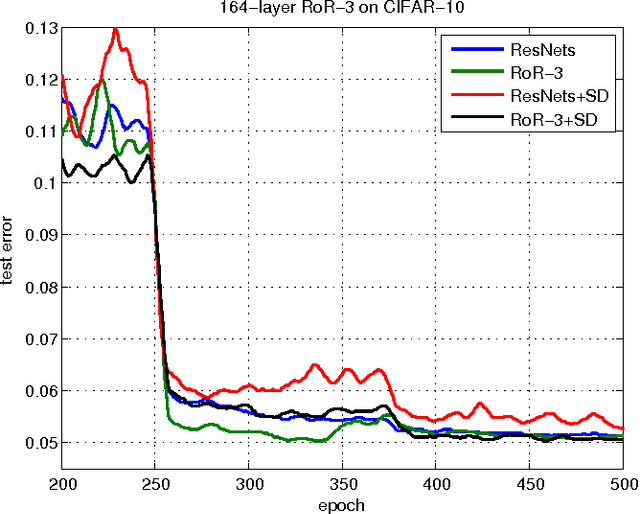
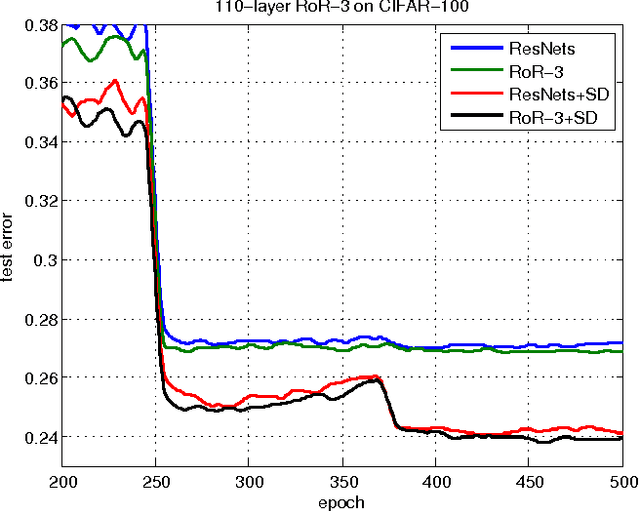
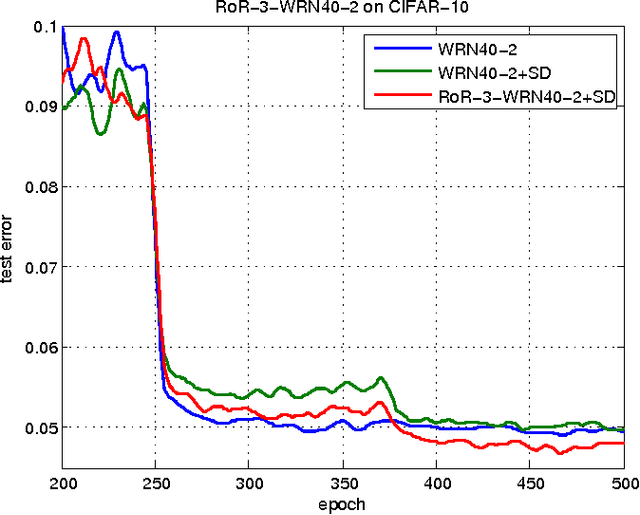
A residual-networks family with hundreds or even thousands of layers dominates major image recognition tasks, but building a network by simply stacking residual blocks inevitably limits its optimization ability. This paper proposes a novel residual-network architecture, Residual networks of Residual networks (RoR), to dig the optimization ability of residual networks. RoR substitutes optimizing residual mapping of residual mapping for optimizing original residual mapping. In particular, RoR adds level-wise shortcut connections upon original residual networks to promote the learning capability of residual networks. More importantly, RoR can be applied to various kinds of residual networks (ResNets, Pre-ResNets and WRN) and significantly boost their performance. Our experiments demonstrate the effectiveness and versatility of RoR, where it achieves the best performance in all residual-network-like structures. Our RoR-3-WRN58-4+SD models achieve new state-of-the-art results on CIFAR-10, CIFAR-100 and SVHN, with test errors 3.77%, 19.73% and 1.59%, respectively. RoR-3 models also achieve state-of-the-art results compared to ResNets on ImageNet data set.
Multiple Instance Learning Convolutional Neural Networks for Object Recognition
Oct 11, 2016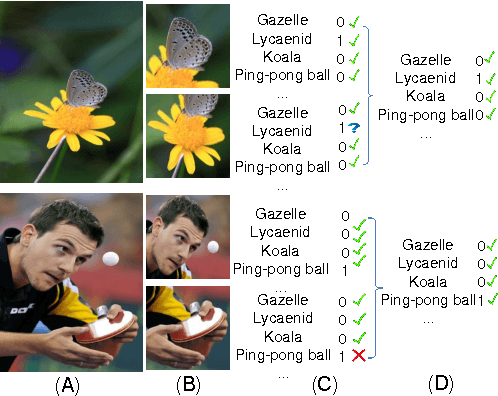
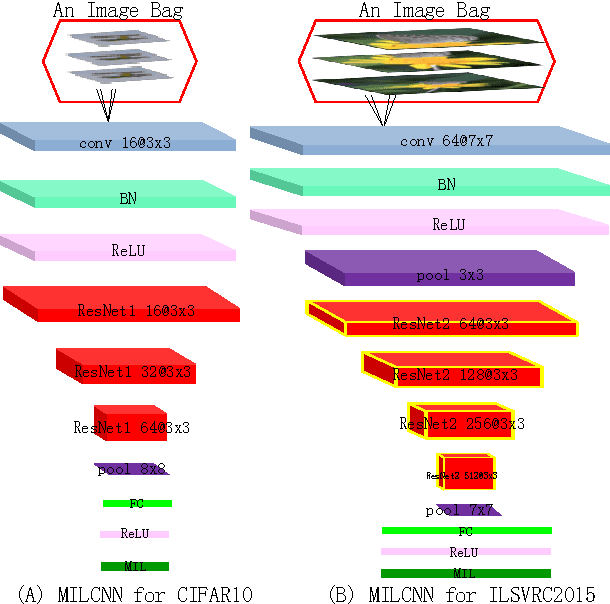


Convolutional Neural Networks (CNN) have demon- strated its successful applications in computer vision, speech recognition, and natural language processing. For object recog- nition, CNNs might be limited by its strict label requirement and an implicit assumption that images are supposed to be target- object-dominated for optimal solutions. However, the labeling procedure, necessitating laying out the locations of target ob- jects, is very tedious, making high-quality large-scale dataset prohibitively expensive. Data augmentation schemes are widely used when deep networks suffer the insufficient training data problem. All the images produced through data augmentation share the same label, which may be problematic since not all data augmentation methods are label-preserving. In this paper, we propose a weakly supervised CNN framework named Multiple Instance Learning Convolutional Neural Networks (MILCNN) to solve this problem. We apply MILCNN framework to object recognition and report state-of-the-art performance on three benchmark datasets: CIFAR10, CIFAR100 and ILSVRC2015 classification dataset.
Latent Model Ensemble with Auto-localization
Oct 11, 2016

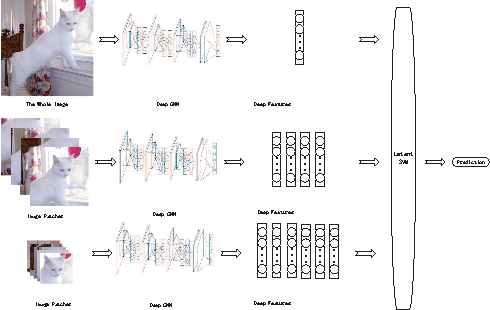
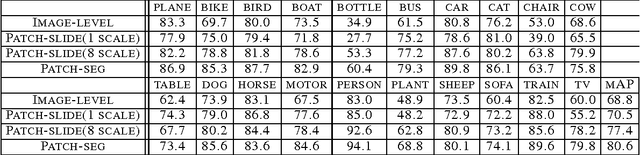
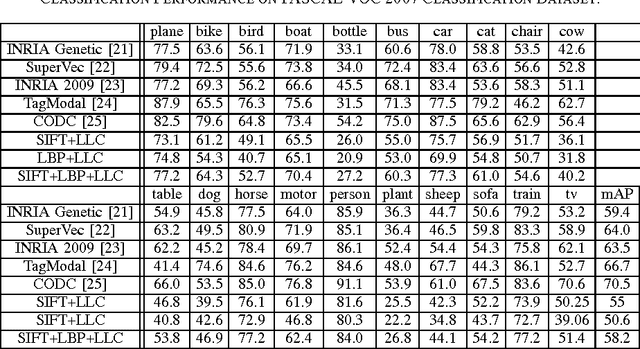
Deep Convolutional Neural Networks (CNN) have exhibited superior performance in many visual recognition tasks including image classification, object detection, and scene label- ing, due to their large learning capacity and resistance to overfit. For the image classification task, most of the current deep CNN- based approaches take the whole size-normalized image as input and have achieved quite promising results. Compared with the previously dominating approaches based on feature extraction, pooling, and classification, the deep CNN-based approaches mainly rely on the learning capability of deep CNN to achieve superior results: the burden of minimizing intra-class variation while maximizing inter-class difference is entirely dependent on the implicit feature learning component of deep CNN; we rely upon the implicitly learned filters and pooling component to select the discriminative regions, which correspond to the activated neurons. However, if the irrelevant regions constitute a large portion of the image of interest, the classification performance of the deep CNN, which takes the whole image as input, can be heavily affected. To solve this issue, we propose a novel latent CNN framework, which treats the most discriminate region as a latent variable. We can jointly learn the global CNN with the latent CNN to avoid the aforementioned big irrelevant region issue, and our experimental results show the evident advantage of the proposed latent CNN over traditional deep CNN: latent CNN outperforms the state-of-the-art performance of deep CNN on standard benchmark datasets including the CIFAR-10, CIFAR- 100, MNIST and PASCAL VOC 2007 Classification dataset.
A Classification Leveraged Object Detector
Apr 07, 2016
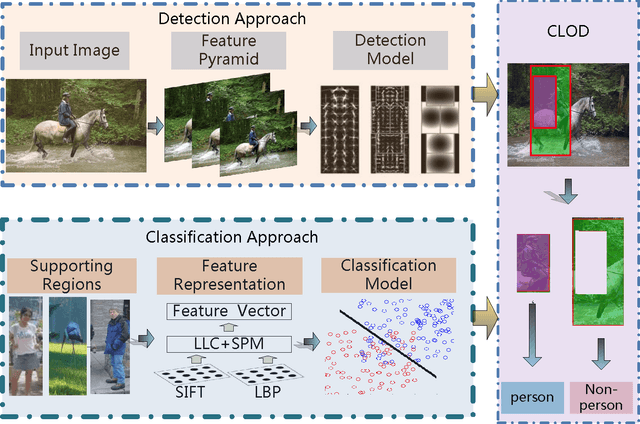
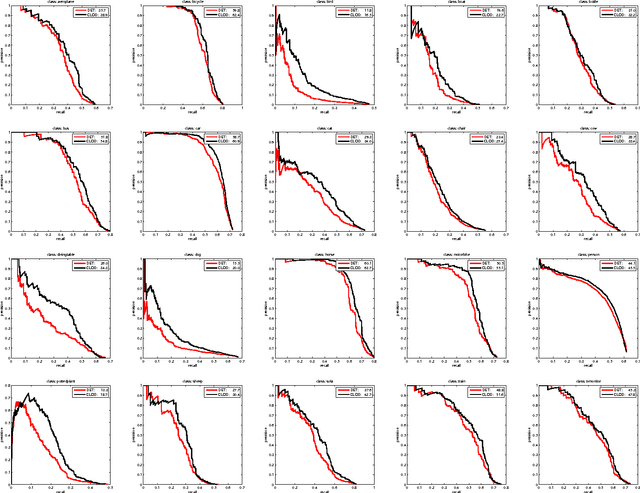
Currently, the state-of-the-art image classification algorithms outperform the best available object detector by a big margin in terms of average precision. We, therefore, propose a simple yet principled approach that allows us to leverage object detection through image classification on supporting regions specified by a preliminary object detector. Using a simple bag-of- words model based image classification algorithm, we leveraged the performance of the deformable model objector from 35.9% to 39.5% in average precision over 20 categories on standard PASCAL VOC 2007 detection dataset.