 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Instance Learning Convolutional Neural Networks for Object Recognition
Oct 11, 2016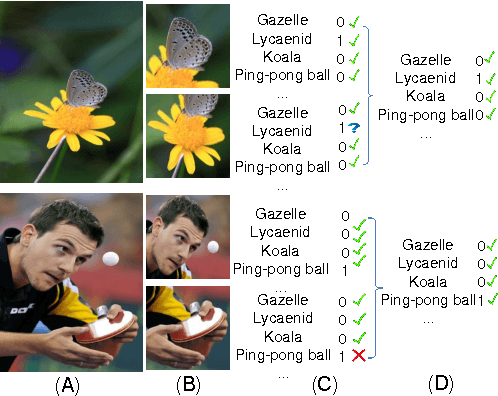
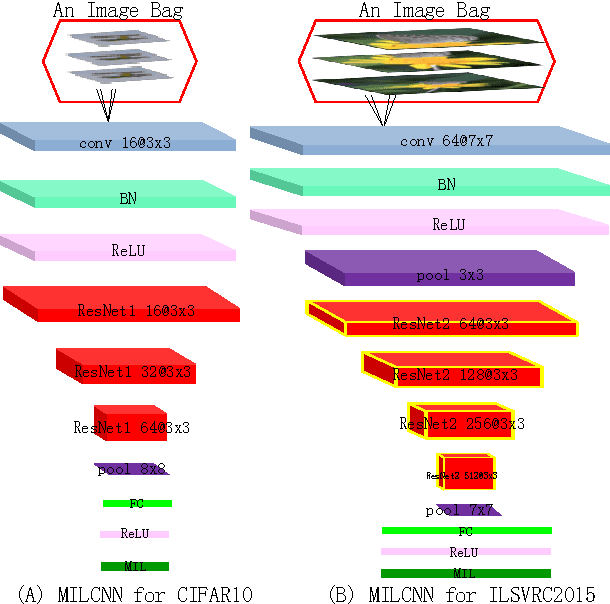


Convolutional Neural Networks (CNN) have demon- strated its successful applications in computer vision, speech recognition, and natural language processing. For object recog- nition, CNNs might be limited by its strict label requirement and an implicit assumption that images are supposed to be target- object-dominated for optimal solutions. However, the labeling procedure, necessitating laying out the locations of target ob- jects, is very tedious, making high-quality large-scale dataset prohibitively expensive. Data augmentation schemes are widely used when deep networks suffer the insufficient training data problem. All the images produced through data augmentation share the same label, which may be problematic since not all data augmentation methods are label-preserving. In this paper, we propose a weakly supervised CNN framework named Multiple Instance Learning Convolutional Neural Networks (MILCNN) to solve this problem. We apply MILCNN framework to object recognition and report state-of-the-art performance on three benchmark datasets: CIFAR10, CIFAR100 and ILSVRC2015 classification dataset.
Latent Model Ensemble with Auto-localization
Oct 11, 2016

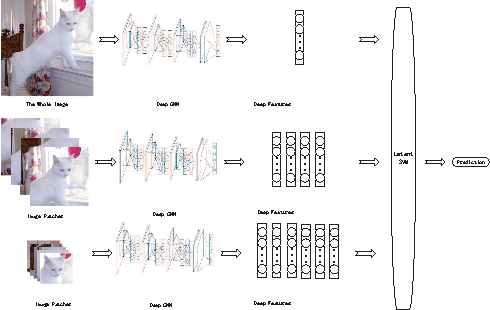
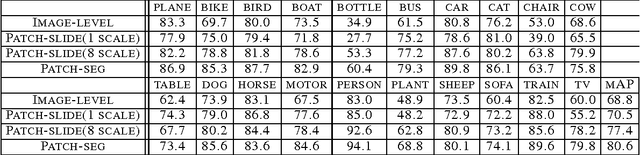
Deep Convolutional Neural Networks (CNN) have exhibited superior performance in many visual recognition tasks including image classification, object detection, and scene label- ing, due to their large learning capacity and resistance to overfit. For the image classification task, most of the current deep CNN- based approaches take the whole size-normalized image as input and have achieved quite promising results. Compared with the previously dominating approaches based on feature extraction, pooling, and classification, the deep CNN-based approaches mainly rely on the learning capability of deep CNN to achieve superior results: the burden of minimizing intra-class variation while maximizing inter-class difference is entirely dependent on the implicit feature learning component of deep CNN; we rely upon the implicitly learned filters and pooling component to select the discriminative regions, which correspond to the activated neurons. However, if the irrelevant regions constitute a large portion of the image of interest, the classification performance of the deep CNN, which takes the whole image as input, can be heavily affected. To solve this issue, we propose a novel latent CNN framework, which treats the most discriminate region as a latent variable. We can jointly learn the global CNN with the latent CNN to avoid the aforementioned big irrelevant region issue, and our experimental results show the evident advantage of the proposed latent CNN over traditional deep CNN: latent CNN outperforms the state-of-the-art performance of deep CNN on standard benchmark datasets including the CIFAR-10, CIFAR- 100, MNIST and PASCAL VOC 2007 Classification dataset.