 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive State Augmentations for Reinforcement Learning-Based Recommender Systems
May 18, 2023



Learning reinforcement learning (RL)-based recommenders from historical user-item interaction sequences is vital to generate high-reward recommendations and improve long-term cumulative benefits. However, existing RL recommendation methods encounter difficulties (i) to estimate the value functions for states which are not contained in the offline training data, and (ii) to learn effective state representations from user implicit feedback due to the lack of contrastive signals. In this work, we propose contrastive state augmentations (CSA) for the training of RL-based recommender systems. To tackle the first issue, we propose four state augmentation strategies to enlarge the state space of the offline data. The proposed method improves the generalization capability of the recommender by making the RL agent visit the local state regions and ensuring the learned value functions are similar between the original and augmented states. For the second issue, we propose introducing contrastive signals between augmented states and the state randomly sampled from other sessions to improve the state representation learning further. To verify the effectiveness of the proposed CSA, we conduct extensive experiments on two publicly accessible datasets and one dataset collected from a real-life e-commerce platform. We also conduct experiments on a simulated environment as the online evaluation setting. Experimental results demonstrate that CSA can effectively improve recommendation performance.
Debiasing Learning for Membership Inference Attacks Against Recommender Systems
Jun 28, 2022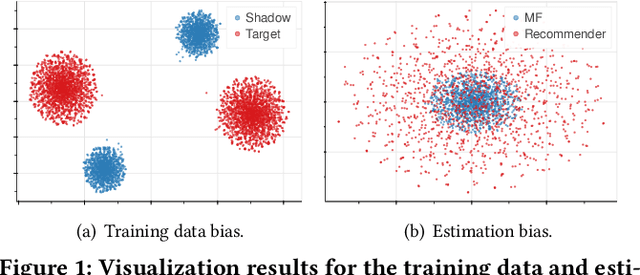
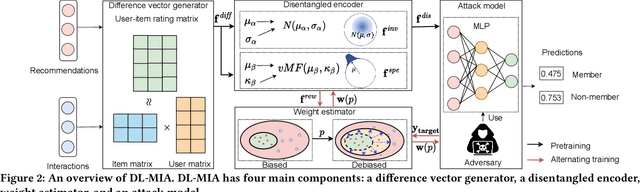

Learned recommender systems may inadvertently leak information about their training data, leading to privacy violations. We investigate privacy threats faced by recommender systems through the lens of membership inference. In such attacks, an adversary aims to infer whether a user's data is used to train the target recommender. To achieve this, previous work has used a shadow recommender to derive training data for the attack model, and then predicts the membership by calculating difference vectors between users' historical interactions and recommended items. State-of-the-art methods face two challenging problems: (1) training data for the attack model is biased due to the gap between shadow and target recommenders, and (2) hidden states in recommenders are not observational, resulting in inaccurate estimations of difference vectors. To address the above limitations, we propose a Debiasing Learning for Membership Inference Attacks against recommender systems (DL-MIA) framework that has four main components: (1) a difference vector generator, (2) a disentangled encoder, (3) a weight estimator, and (4) an attack model. To mitigate the gap between recommenders, a variational auto-encoder (VAE) based disentangled encoder is devised to identify recommender invariant and specific features. To reduce the estimation bias, we design a weight estimator, assigning a truth-level score for each difference vector to indicate estimation accuracy. We evaluate DL-MIA against both general recommenders and sequential recommenders on three real-world datasets. Experimental results show that DL-MIA effectively alleviates training and estimation biases simultaneously, and achieves state-of-the-art attack performance.
Cooperative event-based rigid formation control
Jan 11, 2019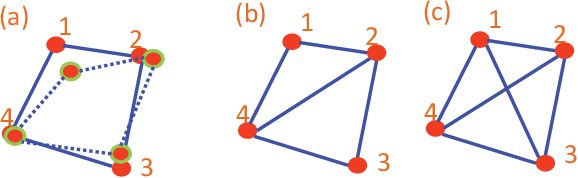
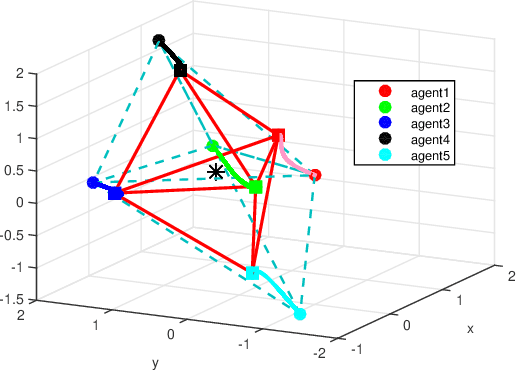
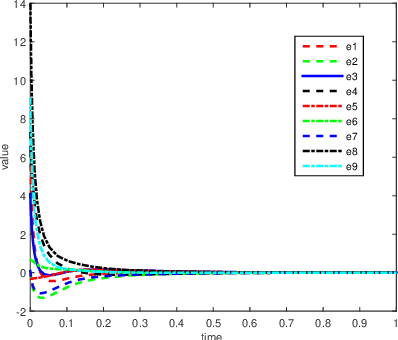
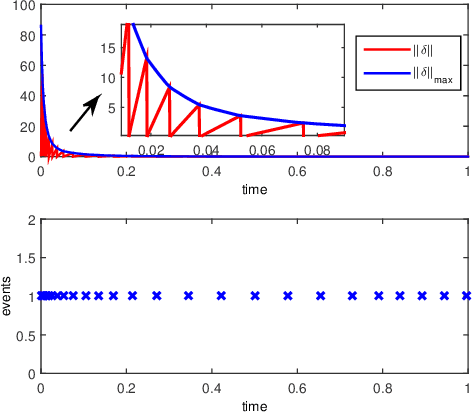
This paper discusses cooperative stabilization control of rigid formations via an event-based approach. We first design a centralized event-based formation control system, in which a central event controller determines the next triggering time and broadcasts the event signal to all the agents for control input update. We then build on this approach to propose a distributed event control strategy, in which each agent can use its local event trigger and local information to update the control input at its own event time. For both cases, the triggering condition, event function and triggering behavior are discussed in detail, and the exponential convergence of the event-based formation system is guaranteed.