 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFastVID: Dynamic Density Pruning for Fast Video Large Language Models
Paper and Code
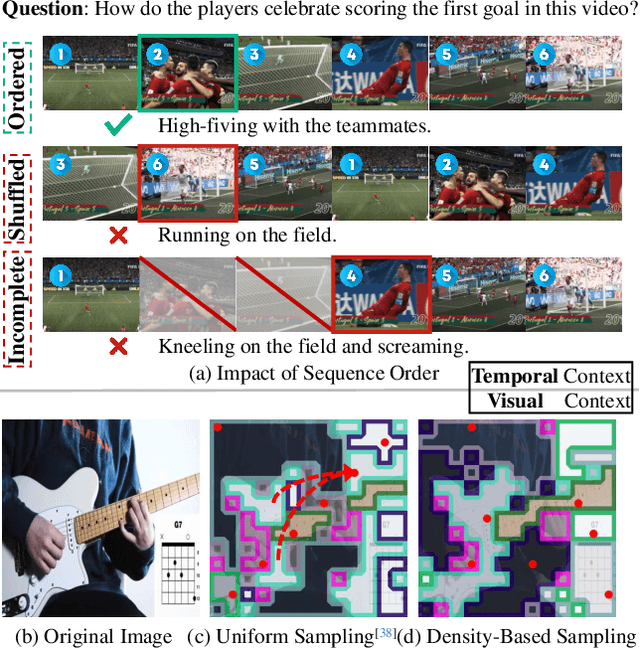
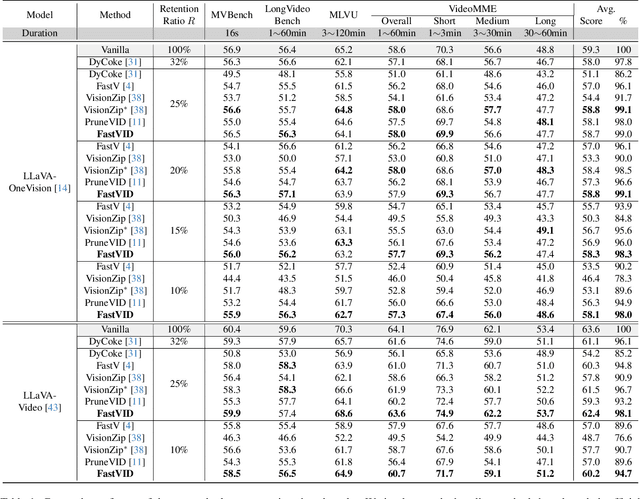
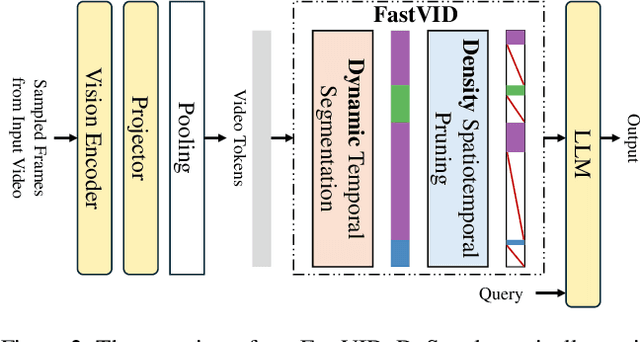
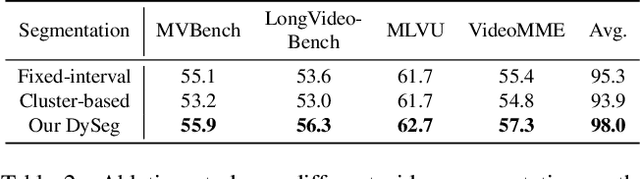
Video Large Language Models have shown impressive capabilities in video comprehension, yet their practical deployment is hindered by substantial inference costs caused by redundant video tokens. Existing pruning techniques fail to fully exploit the spatiotemporal redundancy inherent in video data. To bridge this gap, we perform a systematic analysis of video redundancy from two perspectives: temporal context and visual context. Leveraging this insight, we propose Dynamic Density Pruning for Fast Video LLMs termed FastVID. Specifically, FastVID dynamically partitions videos into temporally ordered segments to preserve temporal structure and applies a density-based token pruning strategy to maintain essential visual information. Our method significantly reduces computational overhead while maintaining temporal and visual integrity. Extensive evaluations show that FastVID achieves state-of-the-art performance across various short- and long-video benchmarks on leading Video LLMs, including LLaVA-OneVision and LLaVA-Video. Notably, FastVID effectively prunes 90% of video tokens while retaining 98.0% of LLaVA-OneVision's original performance. The code is available at https://github.com/LunarShen/FastVID.