 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscoVLA: Discrepancy Reduction in Vision, Language, and Alignment for Parameter-Efficient Video-Text Retrieval
Jun 10, 2025The parameter-efficient adaptation of the image-text pretraining model CLIP for video-text retrieval is a prominent area of research. While CLIP is focused on image-level vision-language matching, video-text retrieval demands comprehensive understanding at the video level. Three key discrepancies emerge in the transfer from image-level to video-level: vision, language, and alignment. However, existing methods mainly focus on vision while neglecting language and alignment. In this paper, we propose Discrepancy Reduction in Vision, Language, and Alignment (DiscoVLA), which simultaneously mitigates all three discrepancies. Specifically, we introduce Image-Video Features Fusion to integrate image-level and video-level features, effectively tackling both vision and language discrepancies. Additionally, we generate pseudo image captions to learn fine-grained image-level alignment. To mitigate alignment discrepancies, we propose Image-to-Video Alignment Distillation, which leverages image-level alignment knowledge to enhance video-level alignment. Extensive experiments demonstrate the superiority of our DiscoVLA. In particular, on MSRVTT with CLIP (ViT-B/16), DiscoVLA outperforms previous methods by 1.5% in R@1, reaching a final score of 50.5% R@1. The code is available at https://github.com/LunarShen/DsicoVLA.
AdaTP: Attention-Debiased Token Pruning for Video Large Language Models
May 26, 2025Video Large Language Models (Video LLMs) have achieved remarkable results in video understanding tasks. However, they often suffer from heavy computational overhead due to the large number of visual tokens generated from multiple video frames. Existing visual token compression methods often rely on attention scores from language models as guidance. However, these scores exhibit inherent biases: global bias reflects a tendency to focus on the two ends of the visual token sequence, while local bias leads to an over-concentration on the same spatial positions across different frames. To address the issue of attention bias, we propose $\textbf{A}$ttention-$\textbf{D}$ebi$\textbf{a}$sed $\textbf{T}$oken $\textbf{P}$runing for Video Large Language Models ($\textbf{AdaTP}$), a novel token pruning pipeline for Video LLMs. AdaTP integrates two dedicated debiasing modules into the pipeline, targeting global attention bias and local attention bias, respectively. Without the need for additional training, our method significantly reduces the computational overhead of Video LLMs while retaining the performance of vanilla models. Extensive evaluation shows that AdaTP achieves state-of-the-art performance in various commonly used video understanding benchmarks. In particular, on LLaVA-OneVision-7B, AdaTP maintains performance without degradation while using only up to $27.3\%$ FLOPs compared to the vanilla model. Our code will be released soon.
FastVID: Dynamic Density Pruning for Fast Video Large Language Models
Mar 14, 2025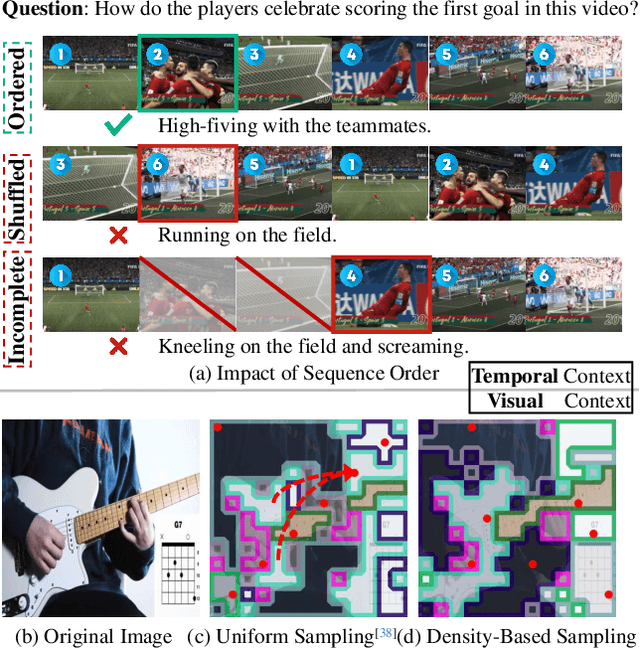
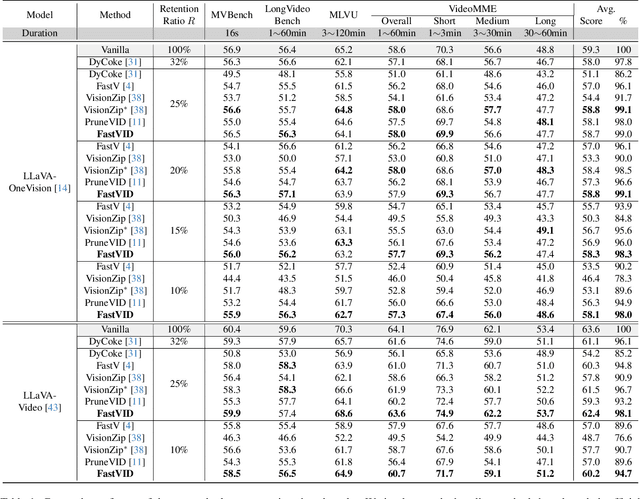
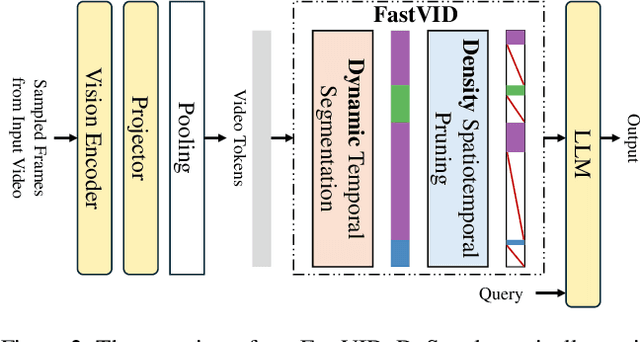
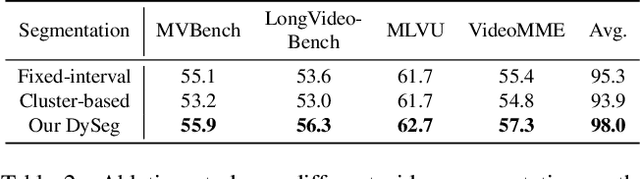
Video Large Language Models have shown impressive capabilities in video comprehension, yet their practical deployment is hindered by substantial inference costs caused by redundant video tokens. Existing pruning techniques fail to fully exploit the spatiotemporal redundancy inherent in video data. To bridge this gap, we perform a systematic analysis of video redundancy from two perspectives: temporal context and visual context. Leveraging this insight, we propose Dynamic Density Pruning for Fast Video LLMs termed FastVID. Specifically, FastVID dynamically partitions videos into temporally ordered segments to preserve temporal structure and applies a density-based token pruning strategy to maintain essential visual information. Our method significantly reduces computational overhead while maintaining temporal and visual integrity. Extensive evaluations show that FastVID achieves state-of-the-art performance across various short- and long-video benchmarks on leading Video LLMs, including LLaVA-OneVision and LLaVA-Video. Notably, FastVID effectively prunes 90% of video tokens while retaining 98.0% of LLaVA-OneVision's original performance. The code is available at https://github.com/LunarShen/FastVID.
LLaVA-MLB: Mitigating and Leveraging Attention Bias for Training-Free Video LLMs
Mar 14, 2025

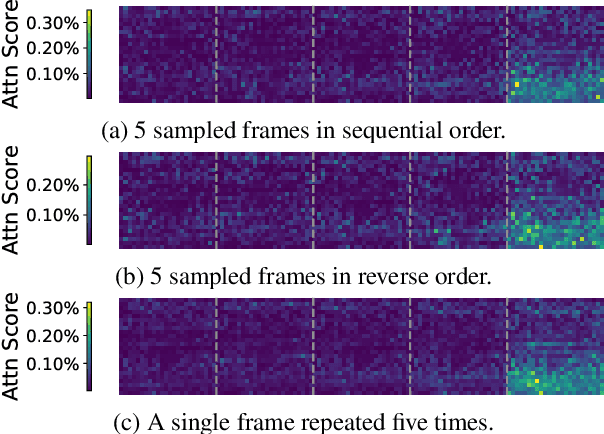
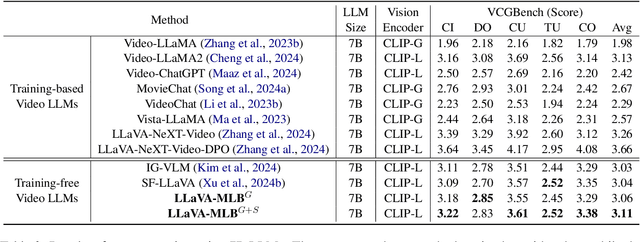
Training-free video large language models (LLMs) leverage pretrained Image LLMs to process video content without the need for further training. A key challenge in such approaches is the difficulty of retaining essential visual and temporal information, constrained by the token limits in Image LLMs. To address this, we propose a two-stage method for selecting query-relevant tokens based on the LLM attention scores: compressing the video sequence and then expanding the sequence. However, during the compression stage, Image LLMs often exhibit a positional attention bias in video sequences, where attention is overly concentrated on later frames, causing early-frame information to be underutilized. To alleviate this attention bias during sequence compression, we propose Gridded Attention Pooling for preserving spatiotemporal structure. Additionally, we introduce Visual Summarization Tail to effectively utilize this bias, facilitating overall video understanding during sequence expansion. In this way, our method effectively Mitigates and Leverages attention Bias (LLaVA-MLB), enabling the frozen Image LLM for detailed video understanding. Experiments on several benchmarks demonstrate that our approach outperforms state-of-the-art methods, achieving superior performance in both efficiency and accuracy. Our code will be released.
TempMe: Video Temporal Token Merging for Efficient Text-Video Retrieval
Sep 02, 2024Most text-video retrieval methods utilize the text-image pre-trained CLIP as a backbone, incorporating complex modules that result in high computational overhead. As a result, many studies focus on efficient fine-tuning. The primary challenge in efficient adaption arises from the inherent differences between image and video modalities. Each sampled video frame must be processed by the image encoder independently, which increases complexity and complicates practical deployment. Although existing efficient methods fine-tune with small trainable parameters, they still incur high inference costs due to the large token number. In this work, we argue that temporal redundancy significantly contributes to the model's high complexity due to the repeated information in consecutive frames. Existing token compression methods for image models fail to solve the unique challenges, as they overlook temporal redundancy across frames. To tackle these problems, we propose Temporal Token Merging (TempMe) to reduce temporal redundancy. Specifically, we introduce a progressive multi-granularity framework. By gradually combining neighboring clips, we merge temporal tokens across different frames and learn video-level features, leading to lower complexity and better performance. Extensive experiments validate the superiority of our TempMe. Compared to previous efficient text-video retrieval methods, TempMe significantly reduces output tokens by 95% and GFLOPs by 51%, while achieving a 1.8X speedup and a 4.4% R-Sum improvement. Additionally, TempMe exhibits robust generalization capabilities by integrating effectively with both efficient and full fine-tuning methods. With full fine-tuning, TempMe achieves a significant 7.9% R-Sum improvement, trains 1.57X faster, and utilizes 75.2% GPU memory usage. Our code will be released.
X-ReID: Cross-Instance Transformer for Identity-Level Person Re-Identification
Feb 04, 2023Currently, most existing person re-identification methods use Instance-Level features, which are extracted only from a single image. However, these Instance-Level features can easily ignore the discriminative information due to the appearance of each identity varies greatly in different images. Thus, it is necessary to exploit Identity-Level features, which can be shared across different images of each identity. In this paper, we propose to promote Instance-Level features to Identity-Level features by employing cross-attention to incorporate information from one image to another of the same identity, thus more unified and discriminative pedestrian information can be obtained. We propose a novel training framework named X-ReID. Specifically, a Cross Intra-Identity Instances module (IntraX) fuses different intra-identity instances to transfer Identity-Level knowledge and make Instance-Level features more compact. A Cross Inter-Identity Instances module (InterX) involves hard positive and hard negative instances to improve the attention response to the same identity instead of different identity, which minimizes intra-identity variation and maximizes inter-identity variation. Extensive experiments on benchmark datasets show the superiority of our method over existing works. Particularly, on the challenging MSMT17, our proposed method gains 1.1% mAP improvements when compared to the second place.
SoccerNet 2022 Challenges Results
Oct 05, 2022



The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.