 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing Vision-Language Semantics for Deepfake Video Detection
Mar 25, 2026Recent Deepfake Video Detection (DFD) studies have demonstrated that pre-trained Vision-Language Models (VLMs) such as CLIP exhibit strong generalization capabilities in detecting artifacts across different identities. However, existing approaches focus on leveraging visual features only, overlooking their most distinctive strength -- the rich vision-language semantics embedded in the latent space. We propose VLAForge, a novel DFD framework that unleashes the potential of such cross-modal semantics to enhance model's discriminability in deepfake detection. This work i) enhances the visual perception of VLM through a ForgePerceiver, which acts as an independent learner to capture diverse, subtle forgery cues both granularly and holistically, while preserving the pretrained Vision-Language Alignment (VLA) knowledge, and ii) provides a complementary discriminative cue -- Identity-Aware VLA score, derived by coupling cross-modal semantics with the forgery cues learned by ForgePerceiver. Notably, the VLA score is augmented by an identity prior-informed text prompting to capture authenticity cues tailored to each identity, thereby enabling more discriminative cross-modal semantics. Comprehensive experiments on video DFD benchmarks, including classical face-swapping forgeries and recent full-face generation forgeries, demonstrate that our VLAForge substantially outperforms state-of-the-art methods at both frame and video levels. Code is available at https://github.com/mala-lab/VLAForge.
FG-Portrait: 3D Flow Guided Editable Portrait Animation
Mar 24, 2026Motion transfer from the driving to the source portrait remains a key challenge in the portrait animation. Current diffusion-based approaches condition only on the driving motion, which fails to capture source-to-driving correspondences and consequently yields suboptimal motion transfer. Although flow estimation provides an alternative, predicting dense correspondences from 2D input is ill-posed and often yields inaccurate animation. We address this problem by introducing 3D flows, a learning-free and geometry-driven motion correspondence directly computed from parametric 3D head models. To integrate this 3D prior into diffusion model, we introduce 3D flow encoding to query potential 3D flows for each target pixel to indicate its displacement back to the source location. To obtain 3D flows aligned with 2D motion changes, we further propose depth-guided sampling to accurately locate the corresponding 3D points for each pixel. Beyond high-fidelity portrait animation, our model further supports user-specified editing of facial expression and head pose. Extensive experiments demonstrate the superiority of our method on consistent driving motion transfer as well as faithful source identity preservation.
Diffusion-Based Makeup Transfer with Facial Region-Aware Makeup Features
Mar 20, 2026Current diffusion-based makeup transfer methods commonly use the makeup information encoded by off-the-shelf foundation models (e.g., CLIP) as condition to preserve the makeup style of reference image in the generation. Although effective, these works mainly have two limitations: (1) foundation models pre-trained for generic tasks struggle to capture makeup styles; (2) the makeup features of reference image are injected to the diffusion denoising model as a whole for global makeup transfer, overlooking the facial region-aware makeup features (i.e., eyes, mouth, etc) and limiting the regional controllability for region-specific makeup transfer. To address these, in this work, we propose Facial Region-Aware Makeup features (FRAM), which has two stages: (1) makeup CLIP fine-tuning; (2) identity and facial region-aware makeup injection. For makeup CLIP fine-tuning, unlike prior works using off-the-shelf CLIP, we synthesize annotated makeup style data using GPT-o3 and text-driven image editing model, and then use the data to train a makeup CLIP encoder through self-supervised and image-text contrastive learning. For identity and facial region-aware makeup injection, we construct before-and-after makeup image pairs from the edited images in stage 1 and then use them to learn to inject identity of source image and makeup of reference image to the diffusion denoising model for makeup transfer. Specifically, we use learnable tokens to query the makeup CLIP encoder to extract facial region-aware makeup features for makeup injection, which is learned via an attention loss to enable regional control. As for identity injection, we use a ControlNet Union to encode source image and its 3D mesh simultaneously. The experimental results verify the superiority of our regional controllability and our makeup transfer performance.
TeFlow: Enabling Multi-frame Supervision for Self-Supervised Feed-forward Scene Flow Estimation
Feb 22, 2026Self-supervised feed-forward methods for scene flow estimation offer real-time efficiency, but their supervision from two-frame point correspondences is unreliable and often breaks down under occlusions. Multi-frame supervision has the potential to provide more stable guidance by incorporating motion cues from past frames, yet naive extensions of two-frame objectives are ineffective because point correspondences vary abruptly across frames, producing inconsistent signals. In the paper, we present TeFlow, enabling multi-frame supervision for feed-forward models by mining temporally consistent supervision. TeFlow introduces a temporal ensembling strategy that forms reliable supervisory signals by aggregating the most temporally consistent motion cues from a candidate pool built across multiple frames. Extensive evaluations demonstrate that TeFlow establishes a new state-of-the-art for self-supervised feed-forward methods, achieving performance gains of up to 33\% on the challenging Argoverse 2 and nuScenes datasets. Our method performs on par with leading optimization-based methods, yet speeds up 150 times. The code is open-sourced at https://github.com/KTH-RPL/OpenSceneFlow along with trained model weights.
SAM-Body4D: Training-Free 4D Human Body Mesh Recovery from Videos
Dec 09, 2025Human Mesh Recovery (HMR) aims to reconstruct 3D human pose and shape from 2D observations and is fundamental to human-centric understanding in real-world scenarios. While recent image-based HMR methods such as SAM 3D Body achieve strong robustness on in-the-wild images, they rely on per-frame inference when applied to videos, leading to temporal inconsistency and degraded performance under occlusions. We address these issues without extra training by leveraging the inherent human continuity in videos. We propose SAM-Body4D, a training-free framework for temporally consistent and occlusion-robust HMR from videos. We first generate identity-consistent masklets using a promptable video segmentation model, then refine them with an Occlusion-Aware module to recover missing regions. The refined masklets guide SAM 3D Body to produce consistent full-body mesh trajectories, while a padding-based parallel strategy enables efficient multi-human inference. Experimental results demonstrate that SAM-Body4D achieves improved temporal stability and robustness in challenging in-the-wild videos, without any retraining. Our code and demo are available at: https://github.com/gaomingqi/sam-body4d.
Unlocking the Potential of Diffusion Priors in Blind Face Restoration
Aug 12, 2025
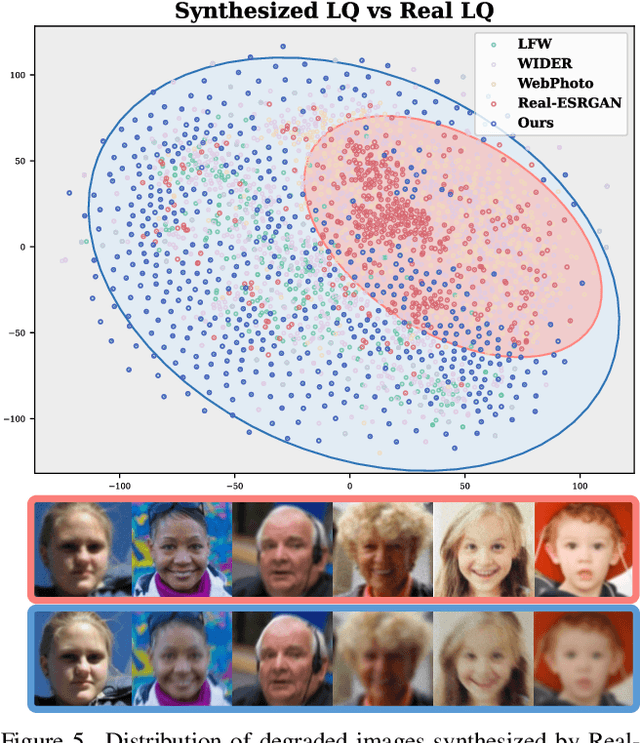
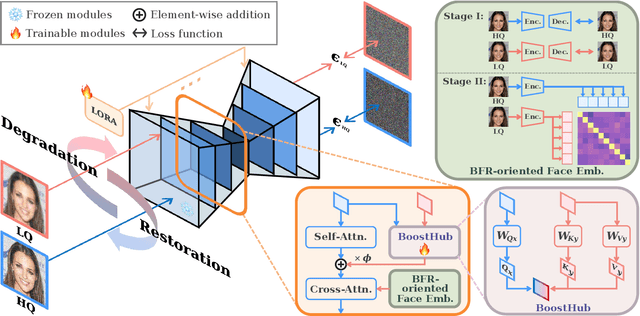
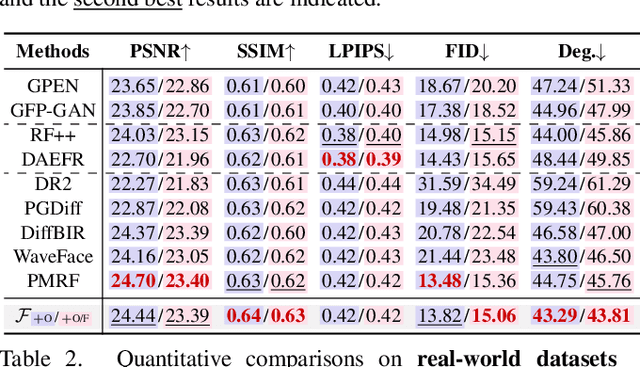
Although diffusion prior is rising as a powerful solution for blind face restoration (BFR), the inherent gap between the vanilla diffusion model and BFR settings hinders its seamless adaptation. The gap mainly stems from the discrepancy between 1) high-quality (HQ) and low-quality (LQ) images and 2) synthesized and real-world images. The vanilla diffusion model is trained on images with no or less degradations, whereas BFR handles moderately to severely degraded images. Additionally, LQ images used for training are synthesized by a naive degradation model with limited degradation patterns, which fails to simulate complex and unknown degradations in real-world scenarios. In this work, we use a unified network FLIPNET that switches between two modes to resolve specific gaps. In Restoration mode, the model gradually integrates BFR-oriented features and face embeddings from LQ images to achieve authentic and faithful face restoration. In Degradation mode, the model synthesizes real-world like degraded images based on the knowledge learned from real-world degradation datasets. Extensive evaluations on benchmark datasets show that our model 1) outperforms previous diffusion prior based BFR methods in terms of authenticity and fidelity, and 2) outperforms the naive degradation model in modeling the real-world degradations.
WaveFace: Authentic Face Restoration with Efficient Frequency Recovery
Mar 19, 2024
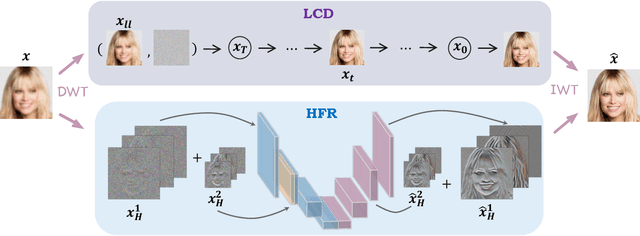


Although diffusion models are rising as a powerful solution for blind face restoration, they are criticized for two problems: 1) slow training and inference speed, and 2) failure in preserving identity and recovering fine-grained facial details. In this work, we propose WaveFace to solve the problems in the frequency domain, where low- and high-frequency components decomposed by wavelet transformation are considered individually to maximize authenticity as well as efficiency. The diffusion model is applied to recover the low-frequency component only, which presents general information of the original image but 1/16 in size. To preserve the original identity, the generation is conditioned on the low-frequency component of low-quality images at each denoising step. Meanwhile, high-frequency components at multiple decomposition levels are handled by a unified network, which recovers complex facial details in a single step. Evaluations on four benchmark datasets show that: 1) WaveFace outperforms state-of-the-art methods in authenticity, especially in terms of identity preservation, and 2) authentic images are restored with the efficiency 10x faster than existing diffusion model-based BFR methods.
Confidence-guided Centroids for Unsupervised Person Re-Identification
Nov 22, 2022



Unsupervised person re-identification (ReID) aims to train a feature extractor for identity retrieval without exploiting identity labels. Due to the blind trust in imperfect clustering results, the learning is inevitably misled by unreliable pseudo labels. Albeit the pseudo label refinement has been investigated by previous works, they generally leverage auxiliary information such as camera IDs and body part predictions. This work explores the internal characteristics of clusters to refine pseudo labels. To this end, Confidence-Guided Centroids (CGC) are proposed to provide reliable cluster-wise prototypes for feature learning. Since samples with high confidence are exclusively involved in the formation of centroids, the identity information of low-confidence samples, i.e., boundary samples, are NOT likely to contribute to the corresponding centroid. Given the new centroids, current learning scheme, where samples are enforced to learn from their assigned centroids solely, is unwise. To remedy the situation, we propose to use Confidence-Guided pseudo Label (CGL), which enables samples to approach not only the originally assigned centroid but other centroids that are potentially embedded with their identity information. Empowered by confidence-guided centroids and labels, our method yields comparable performance with, or even outperforms, state-of-the-art pseudo label refinement works that largely leverage auxiliary information.
Physically-Based Face Rendering for NIR-VIS Face Recognition
Nov 11, 2022Near infrared (NIR) to Visible (VIS) face matching is challenging due to the significant domain gaps as well as a lack of sufficient data for cross-modality model training. To overcome this problem, we propose a novel method for paired NIR-VIS facial image generation. Specifically, we reconstruct 3D face shape and reflectance from a large 2D facial dataset and introduce a novel method of transforming the VIS reflectance to NIR reflectance. We then use a physically-based renderer to generate a vast, high-resolution and photorealistic dataset consisting of various poses and identities in the NIR and VIS spectra. Moreover, to facilitate the identity feature learning, we propose an IDentity-based Maximum Mean Discrepancy (ID-MMD) loss, which not only reduces the modality gap between NIR and VIS images at the domain level but encourages the network to focus on the identity features instead of facial details, such as poses and accessories. Extensive experiments conducted on four challenging NIR-VIS face recognition benchmarks demonstrate that the proposed method can achieve comparable performance with the state-of-the-art (SOTA) methods without requiring any existing NIR-VIS face recognition datasets. With slightly fine-tuning on the target NIR-VIS face recognition datasets, our method can significantly surpass the SOTA performance. Code and pretrained models are released under the insightface (https://github.com/deepinsight/insightface/tree/master/recognition).
On Exploring Pose Estimation as an Auxiliary Learning Task for Visible-Infrared Person Re-identification
Jan 11, 2022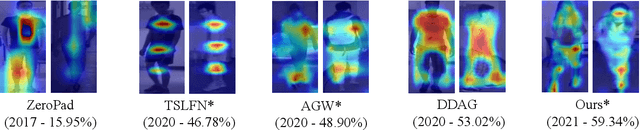

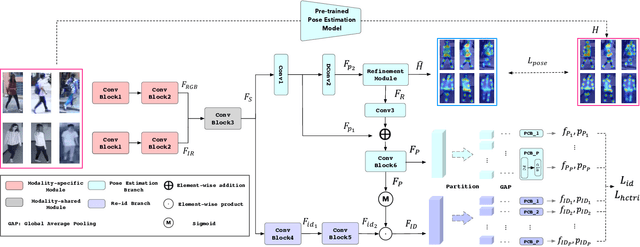
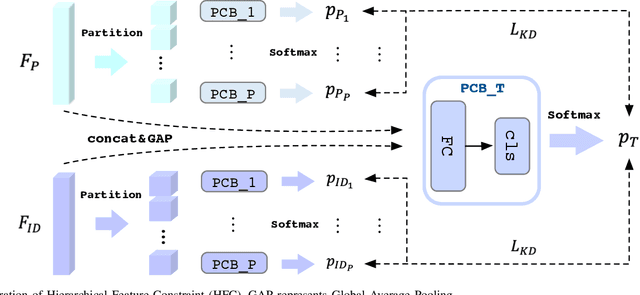
Visible-infrared person re-identification (VI-ReID) has been challenging due to the existence of large discrepancies between visible and infrared modalities. Most pioneering approaches reduce intra-class variations and inter-modality discrepancies by learning modality-shared and ID-related features. However, an explicit modality-shared cue, i.e., body keypoints, has not been fully exploited in VI-ReID. Additionally, existing feature learning paradigms imposed constraints on either global features or partitioned feature stripes, which neglect the prediction consistency of global and part features. To address the above problems, we exploit Pose Estimation as an auxiliary learning task to assist the VI-ReID task in an end-to-end framework. By jointly training these two tasks in a mutually beneficial manner, our model learns higher quality modality-shared and ID-related features. On top of it, the learnings of global features and local features are seamlessly synchronized by Hierarchical Feature Constraint (HFC), where the former supervises the latter using the knowledge distillation strategy. Experimental results on two benchmark VI-ReID datasets show that the proposed method consistently improves state-of-the-art methods by significant margins. Specifically, our method achieves nearly 20$\%$ mAP improvements against the state-of-the-art method on the RegDB dataset. Our intriguing findings highlight the usage of auxiliary task learning in VI-ReID.