 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalient Object Detection From Arbitrary Modalities
May 06, 2024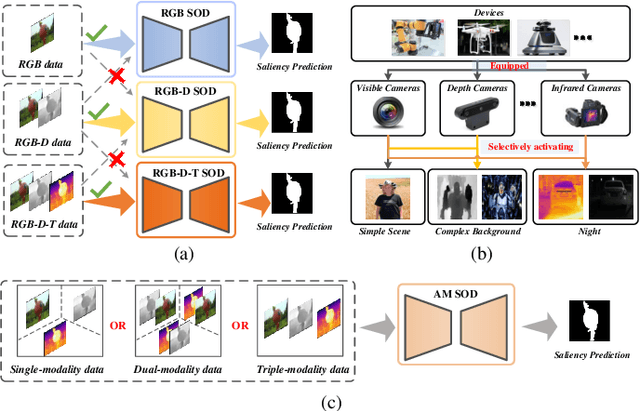
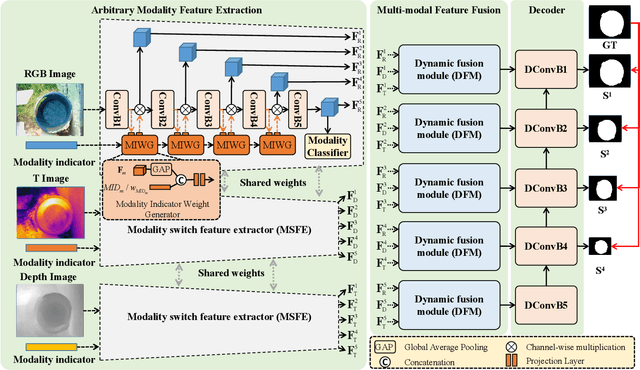
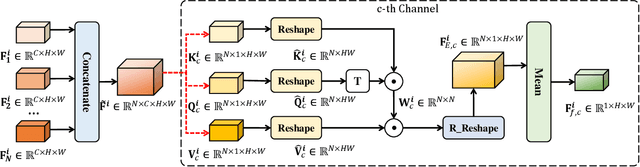
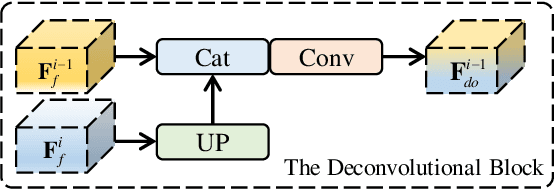
Toward desirable saliency prediction, the types and numbers of inputs for a salient object detection (SOD) algorithm may dynamically change in many real-life applications. However, existing SOD algorithms are mainly designed or trained for one particular type of inputs, failing to be generalized to other types of inputs. Consequentially, more types of SOD algorithms need to be prepared in advance for handling different types of inputs, raising huge hardware and research costs. Differently, in this paper, we propose a new type of SOD task, termed Arbitrary Modality SOD (AM SOD). The most prominent characteristics of AM SOD are that the modality types and modality numbers will be arbitrary or dynamically changed. The former means that the inputs to the AM SOD algorithm may be arbitrary modalities such as RGB, depths, or even any combination of them. While, the latter indicates that the inputs may have arbitrary modality numbers as the input type is changed, e.g. single-modality RGB image, dual-modality RGB-Depth (RGB-D) images or triple-modality RGB-Depth-Thermal (RGB-D-T) images. Accordingly, a preliminary solution to the above challenges, \i.e. a modality switch network (MSN), is proposed in this paper. In particular, a modality switch feature extractor (MSFE) is first designed to extract discriminative features from each modality effectively by introducing some modality indicators, which will generate some weights for modality switching. Subsequently, a dynamic fusion module (DFM) is proposed to adaptively fuse features from a variable number of modalities based on a novel Transformer structure. Finally, a new dataset, named AM-XD, is constructed to facilitate research on AM SOD. Extensive experiments demonstrate that our AM SOD method can effectively cope with changes in the type and number of input modalities for robust salient object detection.
Modality Prompts for Arbitrary Modality Salient Object Detection
May 06, 2024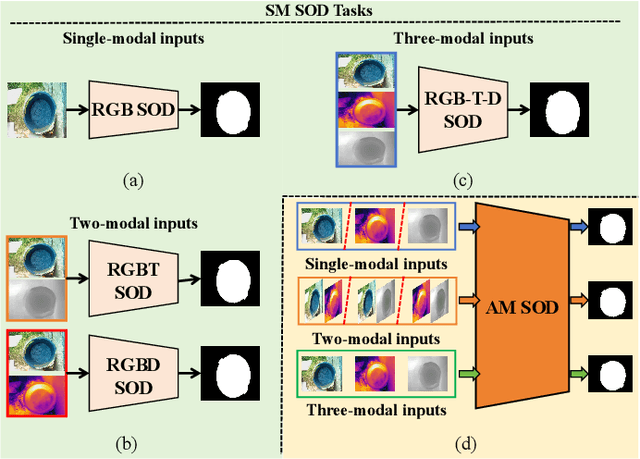



This paper delves into the task of arbitrary modality salient object detection (AM SOD), aiming to detect salient objects from arbitrary modalities, eg RGB images, RGB-D images, and RGB-D-T images. A novel modality-adaptive Transformer (MAT) will be proposed to investigate two fundamental challenges of AM SOD, ie more diverse modality discrepancies caused by varying modality types that need to be processed, and dynamic fusion design caused by an uncertain number of modalities present in the inputs of multimodal fusion strategy. Specifically, inspired by prompt learning's ability of aligning the distributions of pre-trained models to the characteristic of downstream tasks by learning some prompts, MAT will first present a modality-adaptive feature extractor (MAFE) to tackle the diverse modality discrepancies by introducing a modality prompt for each modality. In the training stage, a new modality translation contractive (MTC) loss will be further designed to assist MAFE in learning those modality-distinguishable modality prompts. Accordingly, in the testing stage, MAFE can employ those learned modality prompts to adaptively adjust its feature space according to the characteristics of the input modalities, thus being able to extract discriminative unimodal features. Then, MAFE will present a channel-wise and spatial-wise fusion hybrid (CSFH) strategy to meet the demand for dynamic fusion. For that, CSFH dedicates a channel-wise dynamic fusion module (CDFM) and a novel spatial-wise dynamic fusion module (SDFM) to fuse the unimodal features from varying numbers of modalities and meanwhile effectively capture cross-modal complementary semantic and detail information, respectively. Moreover, CSFH will carefully align CDFM and SDFM to different levels of unimodal features based on their characteristics for more effective complementary information exploitation.
On Exploring Pose Estimation as an Auxiliary Learning Task for Visible-Infrared Person Re-identification
Jan 11, 2022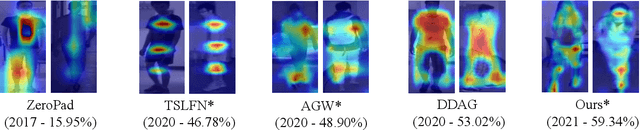

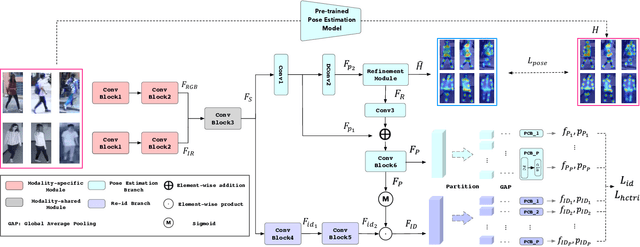
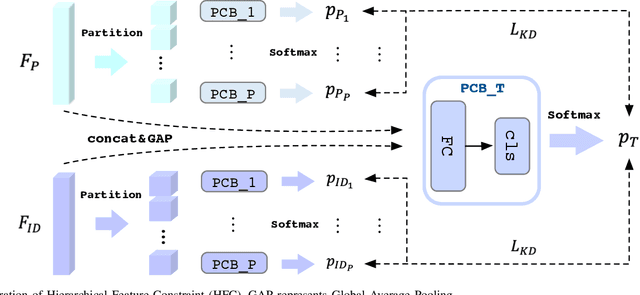
Visible-infrared person re-identification (VI-ReID) has been challenging due to the existence of large discrepancies between visible and infrared modalities. Most pioneering approaches reduce intra-class variations and inter-modality discrepancies by learning modality-shared and ID-related features. However, an explicit modality-shared cue, i.e., body keypoints, has not been fully exploited in VI-ReID. Additionally, existing feature learning paradigms imposed constraints on either global features or partitioned feature stripes, which neglect the prediction consistency of global and part features. To address the above problems, we exploit Pose Estimation as an auxiliary learning task to assist the VI-ReID task in an end-to-end framework. By jointly training these two tasks in a mutually beneficial manner, our model learns higher quality modality-shared and ID-related features. On top of it, the learnings of global features and local features are seamlessly synchronized by Hierarchical Feature Constraint (HFC), where the former supervises the latter using the knowledge distillation strategy. Experimental results on two benchmark VI-ReID datasets show that the proposed method consistently improves state-of-the-art methods by significant margins. Specifically, our method achieves nearly 20$\%$ mAP improvements against the state-of-the-art method on the RegDB dataset. Our intriguing findings highlight the usage of auxiliary task learning in VI-ReID.
Middle-level Fusion for Lightweight RGB-D Salient Object Detection
May 06, 2021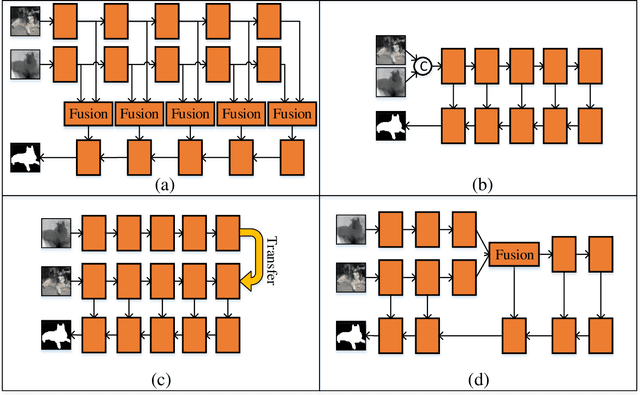
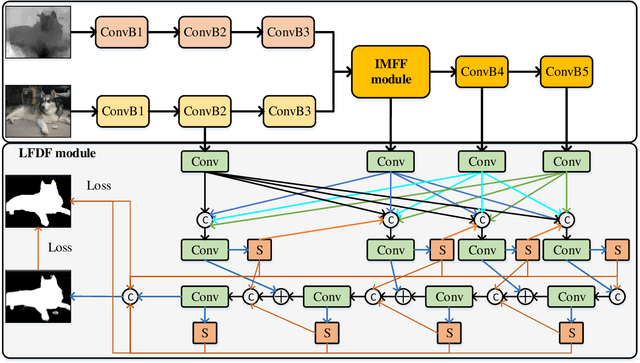
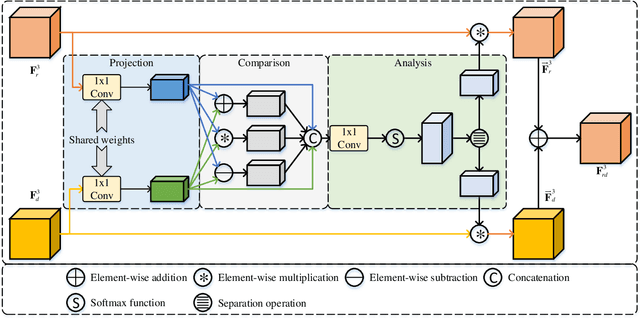

Most existing RGB-D salient object detection (SOD) models require large computational costs and memory consumption to accurately detect the salient objects. This limits the real-life applications of these RGB-D SOD models. To address this issue, a novel lightweight RGB-D SOD model is presented in this paper. Different from most existing models which usually employ the two-stream or single-stream structure, we propose to employ the middle-level fusion structure for designing lightweight RGB-D SOD model, due to the fact that the middle-level fusion structure can simultaneously exploit the modality-shared and modality-specific information as the two-stream structure and can significantly reduce the network's parameters as the single-stream structure. Based on this structure, a novel information-aware multi-modal feature fusion (IMFF) module is first designed to effectively capture the cross-modal complementary information. Then, a novel lightweight feature-level and decision-level feature fusion (LFDF) module is designed to aggregate the feature-level and the decision-level saliency information in different stages with less parameters. With IMFF and LFDF modules incorporated in the middle-level fusion structure, our proposed model has only 3.9M parameters and runs at 33 FPS. Furthermore, the experimental results on several benchmark datasets verify the effectiveness and superiority of the proposed method over some state-of-the-art methods.
Exploring Modality-shared Appearance Features and Modality-invariant Relation Features for Cross-modality Person Re-Identification
Apr 23, 2021


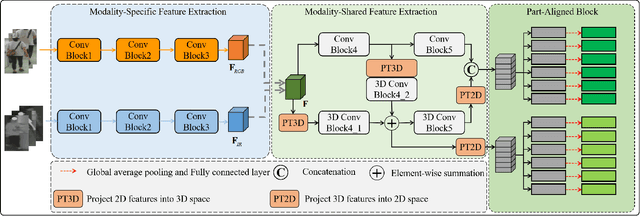
Most existing cross-modality person re-identification works rely on discriminative modality-shared features for reducing cross-modality variations and intra-modality variations. Despite some initial success, such modality-shared appearance features cannot capture enough modality-invariant discriminative information due to a massive discrepancy between RGB and infrared images. To address this issue, on the top of appearance features, we further capture the modality-invariant relations among different person parts (referred to as modality-invariant relation features), which are the complement to those modality-shared appearance features and help to identify persons with similar appearances but different body shapes. To this end, a Multi-level Two-streamed Modality-shared Feature Extraction (MTMFE) sub-network is designed, where the modality-shared appearance features and modality-invariant relation features are first extracted in a shared 2D feature space and a shared 3D feature space, respectively. The two features are then fused into the final modality-shared features such that both cross-modality variations and intra-modality variations can be reduced. Besides, a novel cross-modality quadruplet loss is proposed to further reduce the cross-modality variations. Experimental results on several benchmark datasets demonstrate that our proposed method exceeds state-of-the-art algorithms by a noticeable margin.