 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Modality-shared Appearance Features and Modality-invariant Relation Features for Cross-modality Person Re-Identification
Paper and Code
Apr 23, 2021


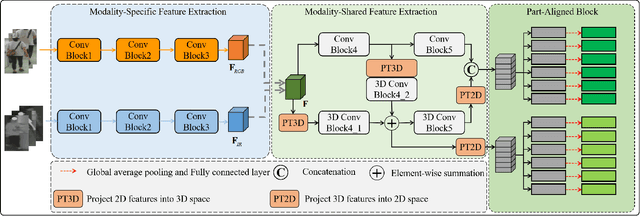
Most existing cross-modality person re-identification works rely on discriminative modality-shared features for reducing cross-modality variations and intra-modality variations. Despite some initial success, such modality-shared appearance features cannot capture enough modality-invariant discriminative information due to a massive discrepancy between RGB and infrared images. To address this issue, on the top of appearance features, we further capture the modality-invariant relations among different person parts (referred to as modality-invariant relation features), which are the complement to those modality-shared appearance features and help to identify persons with similar appearances but different body shapes. To this end, a Multi-level Two-streamed Modality-shared Feature Extraction (MTMFE) sub-network is designed, where the modality-shared appearance features and modality-invariant relation features are first extracted in a shared 2D feature space and a shared 3D feature space, respectively. The two features are then fused into the final modality-shared features such that both cross-modality variations and intra-modality variations can be reduced. Besides, a novel cross-modality quadruplet loss is proposed to further reduce the cross-modality variations. Experimental results on several benchmark datasets demonstrate that our proposed method exceeds state-of-the-art algorithms by a noticeable margin.