 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShallow Feature Based Dense Attention Network for Crowd Counting
Paper and Code
Jun 17, 2020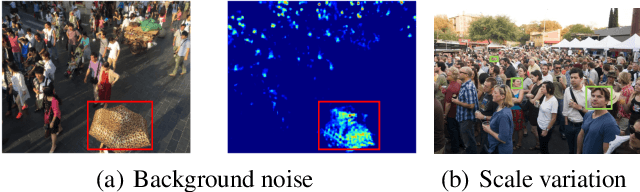
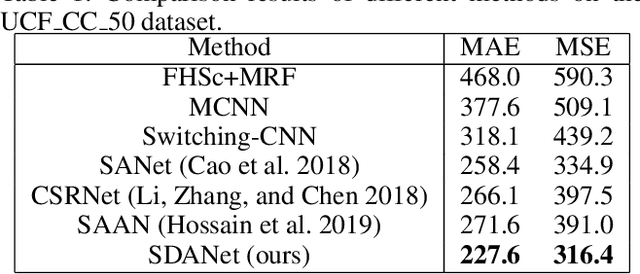
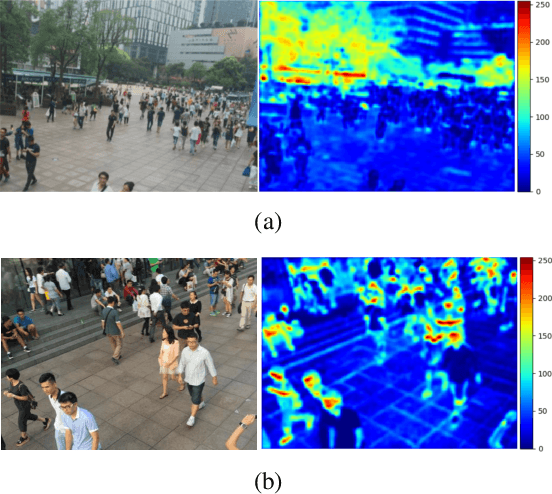
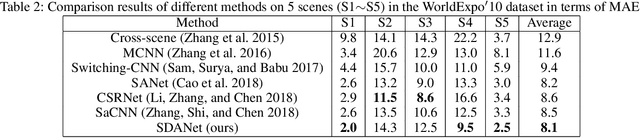
While the performance of crowd counting via deep learning has been improved dramatically in the recent years, it remains an ingrained problem due to cluttered backgrounds and varying scales of people within an image. In this paper, we propose a Shallow feature based Dense Attention Network (SDANet) for crowd counting from still images, which diminishes the impact of backgrounds via involving a shallow feature based attention model, and meanwhile, captures multi-scale information via densely connecting hierarchical image features. Specifically, inspired by the observation that backgrounds and human crowds generally have noticeably different responses in shallow features, we decide to build our attention model upon shallow-feature maps, which results in accurate background-pixel detection. Moreover, considering that the most representative features of people across different scales can appear in different layers of a feature extraction network, to better keep them all, we propose to densely connect hierarchical image features of different layers and subsequently encode them for estimating crowd density. Experimental results on three benchmark datasets clearly demonstrate the superiority of SDANet when dealing with different scenarios. Particularly, on the challenging UCF CC 50 dataset, our method outperforms other existing methods by a large margin, as is evident from a remarkable 11.9% Mean Absolute Error (MAE) drop of our SDANet.