 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuant-Trim in Practice: Improved Cross-Platform Low-Bit Deployment on Edge NPUs
Nov 19, 2025Specialized edge accelerators rely on low-bit quantization, but vendor compilers differ in scaling, clipping, and kernel support, often as black boxes. The same floating-point (FP) checkpoint can therefore yield inconsistent accuracy across backends, forcing practitioners to tweak flags or refactor models to vendor-friendly operator subsets. We introduce Quant-Trim, a training-phase method that produces a hardware-neutral checkpoint robust to backend and precision choices. It combines progressive fake quantization to align training with the deployed integer grid and reverse pruning to tame outlier-driven scale inflation while preserving learnability. Quant-Trim is agnostic to quantization schemes (symmetric/asymmetric,per-tensor/per-channel, INT8/INT4) and requires no vendor-specific graph changes.Across models and tasks, it narrows the FP,low-bit gap, reduces dependence on compiler heuristics/calibration, and avoids per-backend retraining. We report accuracy and edge metrics latency, throughput, energy/inference, and cost under static/dynamic activation scaling and varying operator coverage.
CDGS: Confidence-Aware Depth Regularization for 3D Gaussian Splatting
Feb 20, 20253D Gaussian Splatting (3DGS) has shown significant advantages in novel view synthesis (NVS), particularly in achieving high rendering speeds and high-quality results. However, its geometric accuracy in 3D reconstruction remains limited due to the lack of explicit geometric constraints during optimization. This paper introduces CDGS, a confidence-aware depth regularization approach developed to enhance 3DGS. We leverage multi-cue confidence maps of monocular depth estimation and sparse Structure-from-Motion depth to adaptively adjust depth supervision during the optimization process. Our method demonstrates improved geometric detail preservation in early training stages and achieves competitive performance in both NVS quality and geometric accuracy. Experiments on the publicly available Tanks and Temples benchmark dataset show that our method achieves more stable convergence behavior and more accurate geometric reconstruction results, with improvements of up to 2.31 dB in PSNR for NVS and consistently lower geometric errors in M3C2 distance metrics. Notably, our method reaches comparable F-scores to the original 3DGS with only 50% of the training iterations. We expect this work will facilitate the development of efficient and accurate 3D reconstruction systems for real-world applications such as digital twin creation, heritage preservation, or forestry applications.
On the Issues of TrueDepth Sensor Data for Computer Vision Tasks Across Different iPad Generations
Jan 26, 2022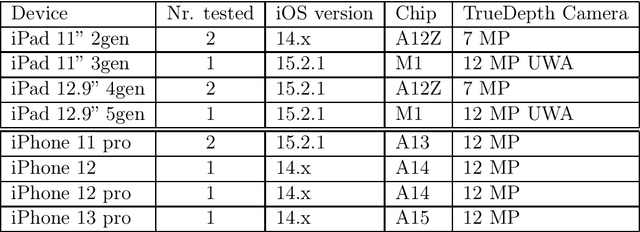
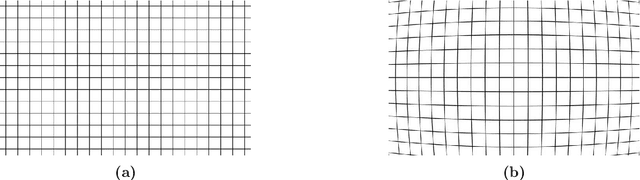

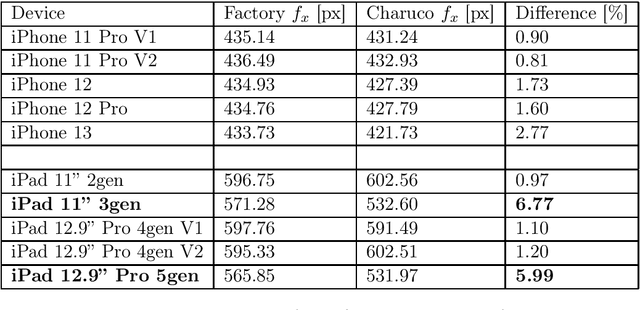
In 2017 Apple introduced the TrueDepth sensor with the iPhone X release. Although its primary use case is biometric face recognition, the exploitation of accurate depth data for other computer vision tasks like segmentation, portrait image generation and metric 3D reconstruction seems natural and lead to the development of various applications. In this report, we investigate the reliability of TrueDepth data - accessed through two different APIs - on various devices including different iPhone and iPad generations and reveal two different and significant issues on all tested iPads.
Point Cloud Upsampling and Normal Estimation using Deep Learning for Robust Surface Reconstruction
Feb 26, 2021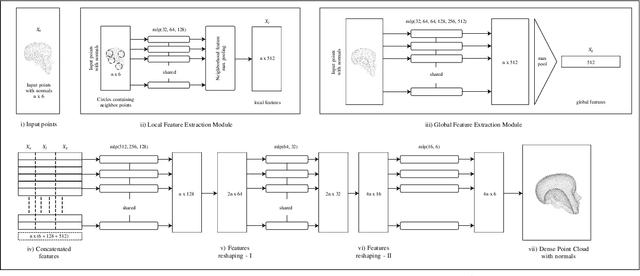
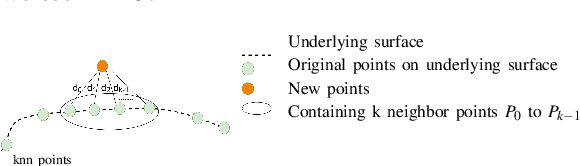

The reconstruction of real-world surfaces is on high demand in various applications. Most existing reconstruction approaches apply 3D scanners for creating point clouds which are generally sparse and of low density. These points clouds will be triangulated and used for visualization in combination with surface normals estimated by geometrical approaches. However, the quality of the reconstruction depends on the density of the point cloud and the estimation of the surface normals. In this paper, we present a novel deep learning architecture for point cloud upsampling that enables subsequent stable and smooth surface reconstruction. A noisy point cloud of low density with corresponding point normals is used to estimate a point cloud with higher density and appendant point normals. To this end, we propose a compound loss function that encourages the network to estimate points that lie on a surface including normals accurately predicting the orientation of the surface. Our results show the benefit of estimating normals together with point positions. The resulting point cloud is smoother, more complete, and the final surface reconstruction is much closer to ground truth.
mdBrief - A Fast Online Adaptable, Distorted Binary Descriptor for Real-Time Applications Using Calibrated Wide-Angle Or Fisheye Cameras
Oct 25, 2016

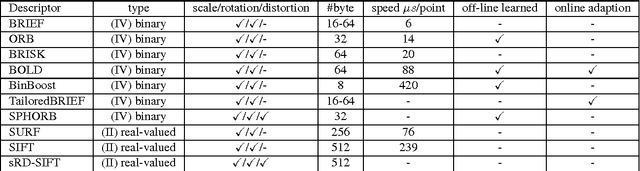
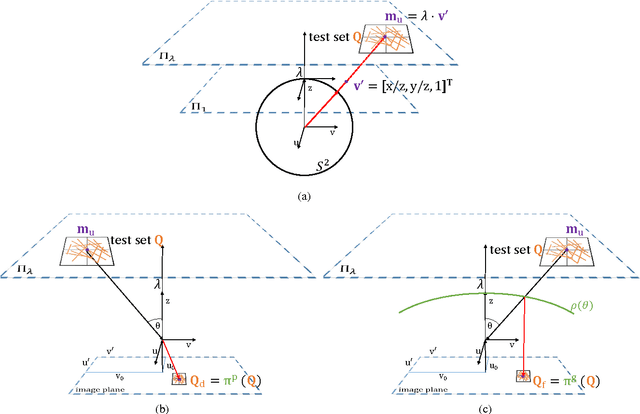
Fast binary descriptors build the core for many vision based applications with real-time demands like object detection, Visual Odometry or SLAM. Commonly it is assumed, that the acquired images and thus the patches extracted around keypoints originate from a perspective projection ignoring image distortion or completely different types of projections such as omnidirectional or fisheye. Usually the deviations from a perfect perspective projection are corrected by undistortion. Latter, however, introduces severe artifacts if the cameras field-of-view gets larger. In this paper, we propose a distorted and masked version of the BRIEF descriptor for calibrated cameras. Instead of correcting the distortion holistically, we distort the binary tests and thus adapt the descriptor to different image regions.
MultiCol-SLAM - A Modular Real-Time Multi-Camera SLAM System
Oct 24, 2016
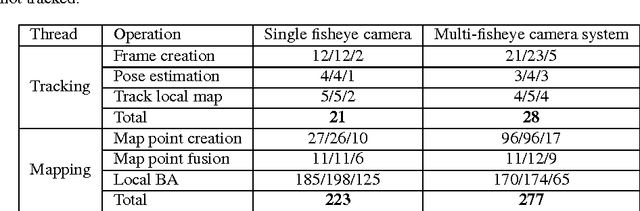
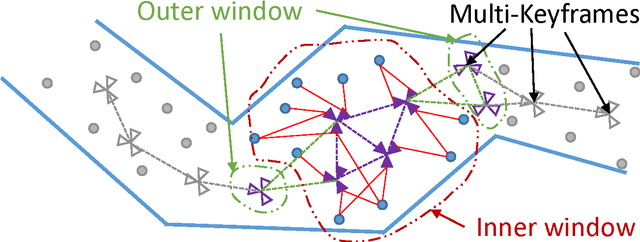
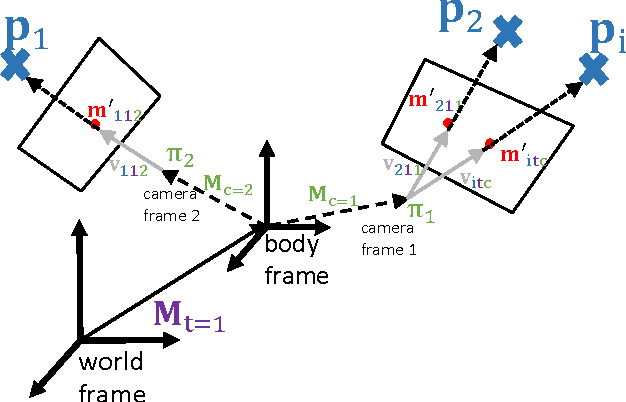
The basis for most vision based applications like robotics, self-driving cars and potentially augmented and virtual reality is a robust, continuous estimation of the position and orientation of a camera system w.r.t the observed environment (scene). In recent years many vision based systems that perform simultaneous localization and mapping (SLAM) have been presented and released as open source. In this paper, we extend and improve upon a state-of-the-art SLAM to make it applicable to arbitrary, rigidly coupled multi-camera systems (MCS) using the MultiCol model. In addition, we include a performance evaluation on accurate ground truth and compare the robustness of the proposed method to a single camera version of the SLAM system. An open source implementation of the proposed multi-fisheye camera SLAM system can be found on-line https://github.com/urbste/MultiCol-SLAM.
MLPnP - A Real-Time Maximum Likelihood Solution to the Perspective-n-Point Problem
Jul 27, 2016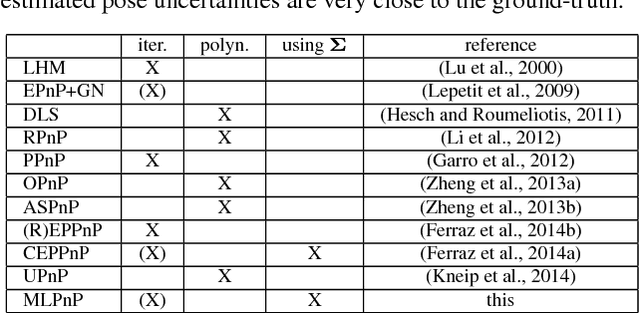
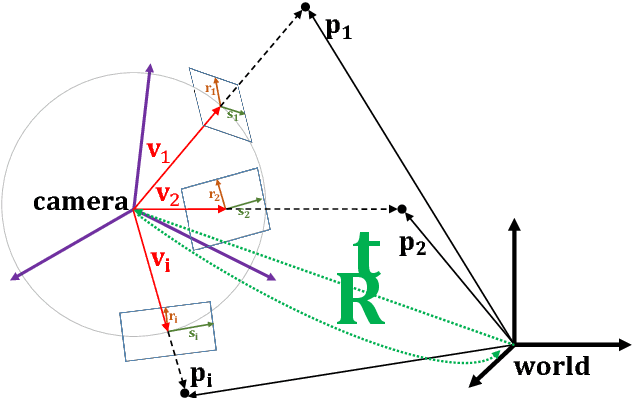
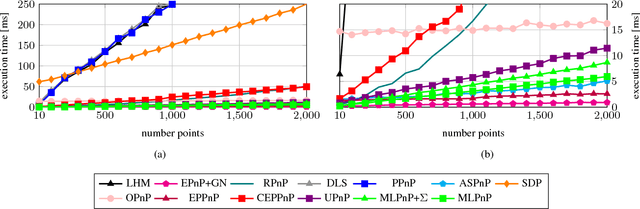

In this paper, a statistically optimal solution to the Perspective-n-Point (PnP) problem is presented. Many solutions to the PnP problem are geometrically optimal, but do not consider the uncertainties of the observations. In addition, it would be desirable to have an internal estimation of the accuracy of the estimated rotation and translation parameters of the camera pose. Thus, we propose a novel maximum likelihood solution to the PnP problem, that incorporates image observation uncertainties and remains real-time capable at the same time. Further, the presented method is general, as is works with 3D direction vectors instead of 2D image points and is thus able to cope with arbitrary central camera models. This is achieved by projecting (and thus reducing) the covariance matrices of the observations to the corresponding vector tangent space.