 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigher-Order Adversarial Patches for Real-Time Object Detectors
Jan 08, 2026Higher-order adversarial attacks can directly be considered the result of a cat-and-mouse game -- an elaborate action involving constant pursuit, near captures, and repeated escapes. This idiom describes the enduring circular training of adversarial attack patterns and adversarial training the best. The following work investigates the impact of higher-order adversarial attacks on object detectors by successively training attack patterns and hardening object detectors with adversarial training. The YOLOv10 object detector is chosen as a representative, and adversarial patches are used in an evasion attack manner. Our results indicate that higher-order adversarial patches are not only affecting the object detector directly trained on but rather provide a stronger generalization capacity compared to lower-order adversarial patches. Moreover, the results highlight that solely adversarial training is not sufficient to harden an object detector efficiently against this kind of adversarial attack. Code: https://github.com/JensBayer/HigherOrder
Semantic Neural Radiance Fields for Multi-Date Satellite Data
Feb 24, 2025
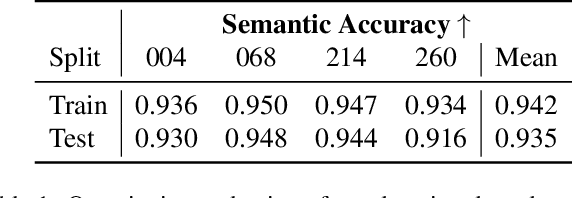
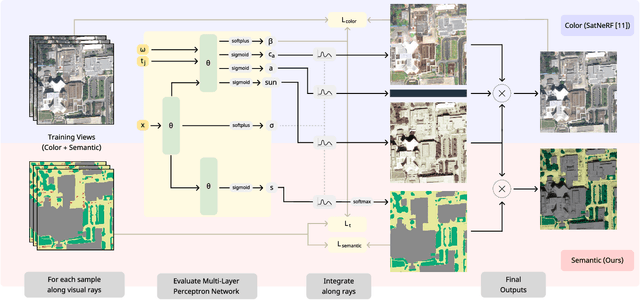
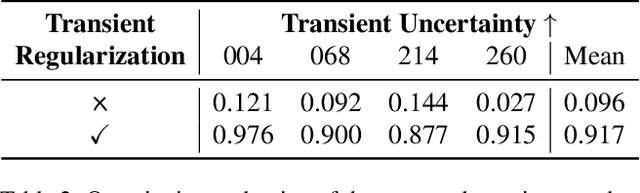
In this work we propose a satellite specific Neural Radiance Fields (NeRF) model capable to obtain a three-dimensional semantic representation (neural semantic field) of the scene. The model derives the output from a set of multi-date satellite images with corresponding pixel-wise semantic labels. We demonstrate the robustness of our approach and its capability to improve noisy input labels. We enhance the color prediction by utilizing the semantic information to address temporal image inconsistencies caused by non-stationary categories such as vehicles. To facilitate further research in this domain, we present a dataset comprising manually generated labels for popular multi-view satellite images. Our code and dataset are available at https://github.com/wagnva/semantic-nerf-for-satellite-data.
Traversing the Subspace of Adversarial Patches
Dec 02, 2024Despite ongoing research on the topic of adversarial examples in deep learning for computer vision, some fundamentals of the nature of these attacks remain unclear. As the manifold hypothesis posits, high-dimensional data tends to be part of a low-dimensional manifold. To verify the thesis with adversarial patches, this paper provides an analysis of a set of adversarial patches and investigates the reconstruction abilities of three different dimensionality reduction methods. Quantitatively, the performance of reconstructed patches in an attack setting is measured and the impact of sampled patches from the latent space during adversarial training is investigated. The evaluation is performed on two publicly available datasets for person detection. The results indicate that more sophisticated dimensionality reduction methods offer no advantages over a simple principal component analysis.
Statewide Visual Geolocalization in the Wild
Sep 25, 2024This work presents a method that is able to predict the geolocation of a street-view photo taken in the wild within a state-sized search region by matching against a database of aerial reference imagery. We partition the search region into geographical cells and train a model to map cells and corresponding photos into a joint embedding space that is used to perform retrieval at test time. The model utilizes aerial images for each cell at multiple levels-of-detail to provide sufficient information about the surrounding scene. We propose a novel layout of the search region with consistent cell resolutions that allows scaling to large geographical regions. Experiments demonstrate that the method successfully localizes 60.6% of all non-panoramic street-view photos uploaded to the crowd-sourcing platform Mapillary in the state of Massachusetts to within 50m of their ground-truth location. Source code is available at https://github.com/fferflo/statewide-visual-geolocalization.
Network transferability of adversarial patches in real-time object detection
Aug 28, 2024Adversarial patches in computer vision can be used, to fool deep neural networks and manipulate their decision-making process. One of the most prominent examples of adversarial patches are evasion attacks for object detectors. By covering parts of objects of interest, these patches suppress the detections and thus make the target object 'invisible' to the object detector. Since these patches are usually optimized on a specific network with a specific train dataset, the transferability across multiple networks and datasets is not given. This paper addresses these issues and investigates the transferability across numerous object detector architectures. Our extensive evaluation across various models on two distinct datasets indicates that patches optimized with larger models provide better network transferability than patches that are optimized with smaller models.
Strike the Balance: On-the-Fly Uncertainty based User Interactions for Long-Term Video Object Segmentation
Jul 31, 2024In this paper, we introduce a variant of video object segmentation (VOS) that bridges interactive and semi-automatic approaches, termed Lazy Video Object Segmentation (ziVOS). In contrast, to both tasks, which handle video object segmentation in an off-line manner (i.e., pre-recorded sequences), we propose through ziVOS to target online recorded sequences. Here, we strive to strike a balance between performance and robustness for long-term scenarios by soliciting user feedback's on-the-fly during the segmentation process. Hence, we aim to maximize the tracking duration of an object of interest, while requiring minimal user corrections to maintain tracking over an extended period. We propose a competitive baseline, i.e., Lazy-XMem, as a reference for future works in ziVOS. Our proposed approach uses an uncertainty estimation of the tracking state to determine whether a user interaction is necessary to refine the model's prediction. To quantitatively assess the performance of our method and the user's workload, we introduce complementary metrics alongside those already established in the field. We evaluate our approach using the recently introduced LVOS dataset, which offers numerous long-term videos. Our code is publicly available at https://github.com/Vujas-Eteph/LazyXMem.
Generating Synthetic Ground Truth Distributions for Multi-step Trajectory Prediction using Probabilistic Composite Bézier Curves
Apr 05, 2024

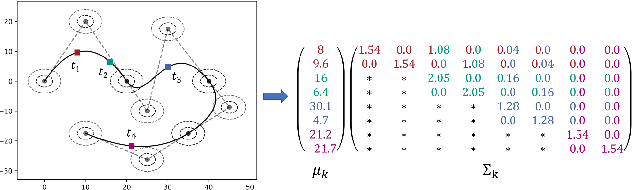

An appropriate data basis grants one of the most important aspects for training and evaluating probabilistic trajectory prediction models based on neural networks. In this regard, a common shortcoming of current benchmark datasets is their limitation to sets of sample trajectories and a lack of actual ground truth distributions, which prevents the use of more expressive error metrics, such as the Wasserstein distance for model evaluation. Towards this end, this paper proposes a novel approach to synthetic dataset generation based on composite probabilistic B\'ezier curves, which is capable of generating ground truth data in terms of probability distributions over full trajectories. This allows the calculation of arbitrary posterior distributions. The paper showcases an exemplary trajectory prediction model evaluation using generated ground truth distribution data.
C-BEV: Contrastive Bird's Eye View Training for Cross-View Image Retrieval and 3-DoF Pose Estimation
Dec 13, 2023To find the geolocation of a street-view image, cross-view geolocalization (CVGL) methods typically perform image retrieval on a database of georeferenced aerial images and determine the location from the visually most similar match. Recent approaches focus mainly on settings where street-view and aerial images are preselected to align w.r.t. translation or orientation, but struggle in challenging real-world scenarios where varying camera poses have to be matched to the same aerial image. We propose a novel trainable retrieval architecture that uses bird's eye view (BEV) maps rather than vectors as embedding representation, and explicitly addresses the many-to-one ambiguity that arises in real-world scenarios. The BEV-based retrieval is trained using the same contrastive setting and loss as classical retrieval. Our method C-BEV surpasses the state-of-the-art on the retrieval task on multiple datasets by a large margin. It is particularly effective in challenging many-to-one scenarios, e.g. increasing the top-1 recall on VIGOR's cross-area split with unknown orientation from 31.1% to 65.0%. Although the model is supervised only through a contrastive objective applied on image pairings, it additionally learns to infer the 3-DoF camera pose on the matching aerial image, and even yields a lower mean pose error than recent methods that are explicitly trained with metric groundtruth.
Utilizing dataset affinity prediction in object detection to assess training data
Nov 16, 2023Data pooling offers various advantages, such as increasing the sample size, improving generalization, reducing sampling bias, and addressing data sparsity and quality, but it is not straightforward and may even be counterproductive. Assessing the effectiveness of pooling datasets in a principled manner is challenging due to the difficulty in estimating the overall information content of individual datasets. Towards this end, we propose incorporating a data source prediction module into standard object detection pipelines. The module runs with minimal overhead during inference time, providing additional information about the data source assigned to individual detections. We show the benefits of the so-called dataset affinity score by automatically selecting samples from a heterogeneous pool of vehicle datasets. The results show that object detectors can be trained on a significantly sparser set of training samples without losing detection accuracy.
Eigenpatches -- Adversarial Patches from Principal Components
Jun 19, 2023Adversarial patches are still a simple yet powerful white box attack that can be used to fool object detectors by suppressing possible detections. The patches of these so-called evasion attacks are computational expensive to produce and require full access to the attacked detector. This paper addresses the problem of computational expensiveness by analyzing 375 generated patches, calculating the principal components of these and show, that linear combinations of the resulting "eigenpatches" can be used to fool object detections successfully.