 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigher-Order Adversarial Patches for Real-Time Object Detectors
Jan 08, 2026Higher-order adversarial attacks can directly be considered the result of a cat-and-mouse game -- an elaborate action involving constant pursuit, near captures, and repeated escapes. This idiom describes the enduring circular training of adversarial attack patterns and adversarial training the best. The following work investigates the impact of higher-order adversarial attacks on object detectors by successively training attack patterns and hardening object detectors with adversarial training. The YOLOv10 object detector is chosen as a representative, and adversarial patches are used in an evasion attack manner. Our results indicate that higher-order adversarial patches are not only affecting the object detector directly trained on but rather provide a stronger generalization capacity compared to lower-order adversarial patches. Moreover, the results highlight that solely adversarial training is not sufficient to harden an object detector efficiently against this kind of adversarial attack. Code: https://github.com/JensBayer/HigherOrder
Traversing the Subspace of Adversarial Patches
Dec 02, 2024Despite ongoing research on the topic of adversarial examples in deep learning for computer vision, some fundamentals of the nature of these attacks remain unclear. As the manifold hypothesis posits, high-dimensional data tends to be part of a low-dimensional manifold. To verify the thesis with adversarial patches, this paper provides an analysis of a set of adversarial patches and investigates the reconstruction abilities of three different dimensionality reduction methods. Quantitatively, the performance of reconstructed patches in an attack setting is measured and the impact of sampled patches from the latent space during adversarial training is investigated. The evaluation is performed on two publicly available datasets for person detection. The results indicate that more sophisticated dimensionality reduction methods offer no advantages over a simple principal component analysis.
Network transferability of adversarial patches in real-time object detection
Aug 28, 2024Adversarial patches in computer vision can be used, to fool deep neural networks and manipulate their decision-making process. One of the most prominent examples of adversarial patches are evasion attacks for object detectors. By covering parts of objects of interest, these patches suppress the detections and thus make the target object 'invisible' to the object detector. Since these patches are usually optimized on a specific network with a specific train dataset, the transferability across multiple networks and datasets is not given. This paper addresses these issues and investigates the transferability across numerous object detector architectures. Our extensive evaluation across various models on two distinct datasets indicates that patches optimized with larger models provide better network transferability than patches that are optimized with smaller models.
Eigenpatches -- Adversarial Patches from Principal Components
Jun 19, 2023Adversarial patches are still a simple yet powerful white box attack that can be used to fool object detectors by suppressing possible detections. The patches of these so-called evasion attacks are computational expensive to produce and require full access to the attacked detector. This paper addresses the problem of computational expensiveness by analyzing 375 generated patches, calculating the principal components of these and show, that linear combinations of the resulting "eigenpatches" can be used to fool object detections successfully.
A Comparison of Deep Saliency Map Generators on Multispectral Data in Object Detection
Aug 26, 2021
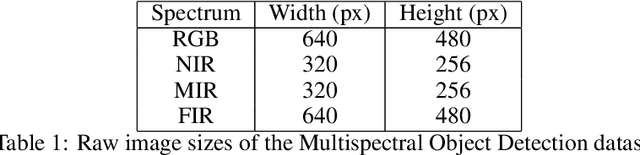

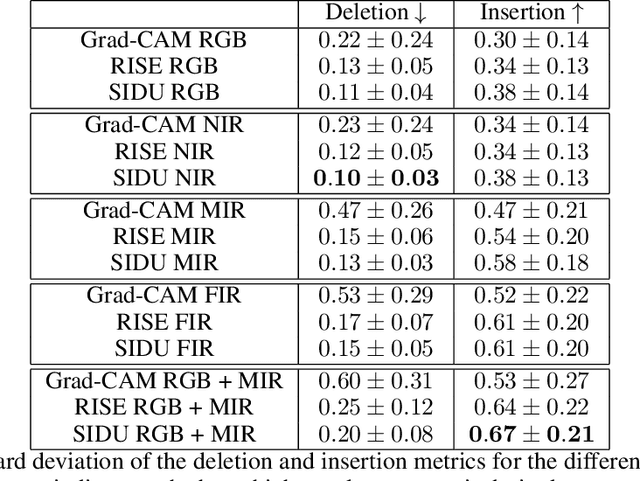
Deep neural networks, especially convolutional deep neural networks, are state-of-the-art methods to classify, segment or even generate images, movies, or sounds. However, these methods lack of a good semantic understanding of what happens internally. The question, why a COVID-19 detector has classified a stack of lung-ct images as positive, is sometimes more interesting than the overall specificity and sensitivity. Especially when human domain expert knowledge disagrees with the given output. This way, human domain experts could also be advised to reconsider their choice, regarding the information pointed out by the system. In addition, the deep learning model can be controlled, and a present dataset bias can be found. Currently, most explainable AI methods in the computer vision domain are purely used on image classification, where the images are ordinary images in the visible spectrum. As a result, there is no comparison on how the methods behave with multimodal image data, as well as most methods have not been investigated on how they behave when used for object detection. This work tries to close the gaps. Firstly, investigating three saliency map generator methods on how their maps differ across the different spectra. This is achieved via accurate and systematic training. Secondly, we examine how they behave when used for object detection. As a practical problem, we chose object detection in the infrared and visual spectrum for autonomous driving. The dataset used in this work is the Multispectral Object Detection Dataset, where each scene is available in the FIR, MIR and NIR as well as visual spectrum. The results show that there are differences between the infrared and visual activation maps. Further, an advanced training with both, the infrared and visual data not only improves the network's output, it also leads to more focused spots in the saliency maps.
Image-based OoD-Detector Principles on Graph-based Input Data in Human Action Recognition
Mar 03, 2020
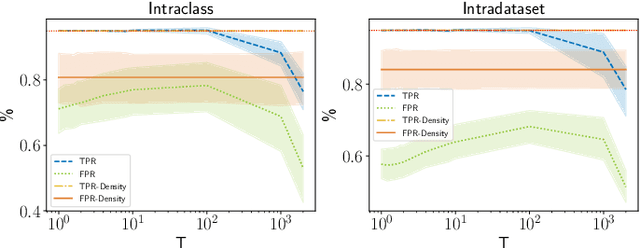
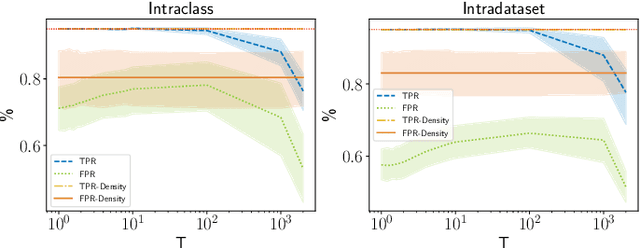
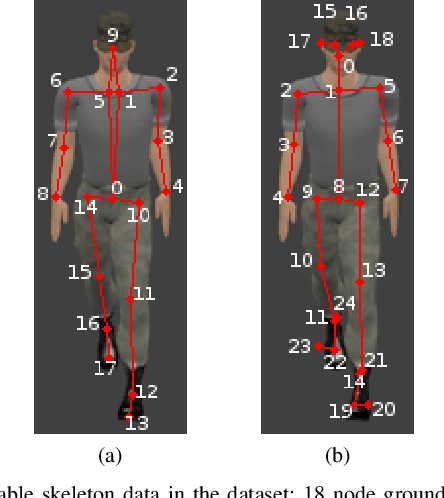
Living in a complex world like ours makes it unacceptable that a practical implementation of a machine learning system assumes a closed world. Therefore, it is necessary for such a learning-based system in a real world environment, to be aware of its own capabilities and limits and to be able to distinguish between confident and unconfident results of the inference, especially if the sample cannot be explained by the underlying distribution. This knowledge is particularly essential in safety-critical environments and tasks e.g. self-driving cars or medical applications. Towards this end, we transfer image-based Out-of-Distribution (OoD)-methods to graph-based data and show the applicability in action recognition. The contribution of this work is (i) the examination of the portability of recent image-based OoD-detectors for graph-based input data, (ii) a Metric Learning-based approach to detect OoD-samples, and (iii) the introduction of a novel semi-synthetic action recognition dataset. The evaluation shows that image-based OoD-methods can be applied to graph-based data. Additionally, there is a gap between the performance on intraclass and intradataset results. First methods as the examined baseline or ODIN provide reasonable results. More sophisticated network architectures - in contrast to their image-based application - were surpassed in the intradataset comparison and even lead to less classification accuracy.
Analysis of Explainers of Black Box Deep Neural Networks for Computer Vision: A Survey
Nov 27, 2019
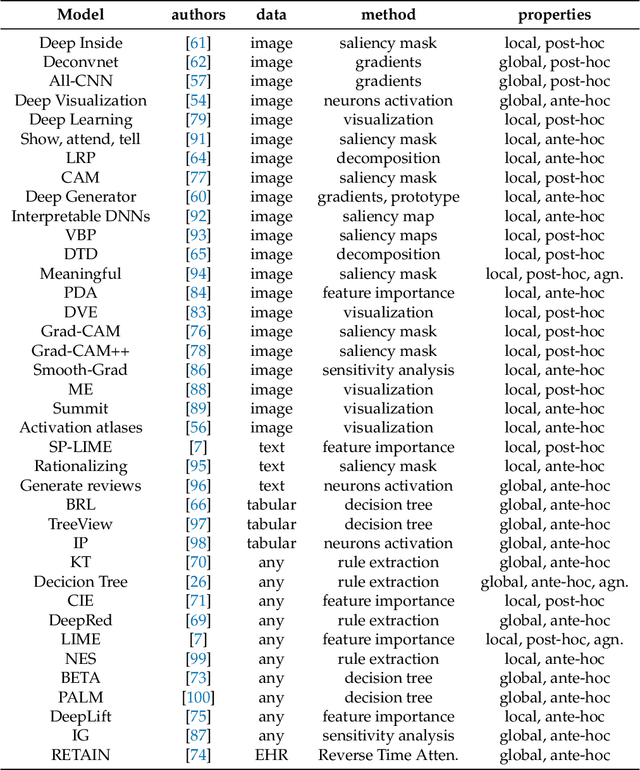


Deep Learning is a state-of-the-art technique to make inference on extensive or complex data. As a black box model due to their multilayer nonlinear structure, Deep Neural Networks are often criticized to be non-transparent and their predictions not traceable by humans. Furthermore, the models learn from artificial datasets, often with bias or contaminated discriminating content. Through their increased distribution, decision-making algorithms can contribute promoting prejudge and unfairness which is not easy to notice due to lack of transparency. Hence, scientists developed several so-called explanators or explainers which try to point out the connection between input and output to represent in a simplified way the inner structure of machine learning black boxes. In this survey we differ the mechanisms and properties of explaining systems for Deep Neural Networks for Computer Vision tasks. We give a comprehensive overview about taxonomy of related studies and compare several survey papers that deal with explainability in general. We work out the drawbacks and gaps and summarize further research ideas.
Investigation on Combining 3D Convolution of Image Data and Optical Flow to Generate Temporal Action Proposals
Mar 14, 2019



In this paper, several variants of two-stream architectures for temporal action proposal generation in long, untrimmed videos are presented. Inspired by the recent advances in the field of human action recognition utilizing 3D convolutions in combination with two-stream networks and based on the Single-Stream Temporal Action Proposals (SST) architecture, four different two-stream architectures utilizing sequences of images on one stream and sequences of images of optical flow on the other stream are subsequently investigated. The four architectures fuse the two separate streams at different depths in the model; for each of them, a broad range of parameters is investigated systematically as well as an optimal parametrization is empirically determined. The experiments on the THUMOS'14 dataset show that all four two-stream architectures are able to outperform the original single-stream SST and achieve state of the art results. Additional experiments revealed that the improvements are not restricted to a single method of calculating optical flow by exchanging the formerly used method of Brox with FlowNet2 and still achieving improvements.