 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of Deep Saliency Map Generators on Multispectral Data in Object Detection
Paper and Code

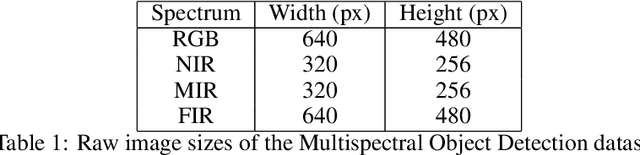

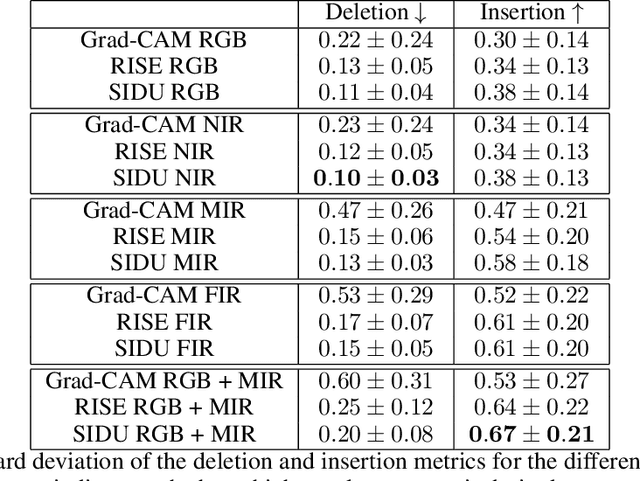
Deep neural networks, especially convolutional deep neural networks, are state-of-the-art methods to classify, segment or even generate images, movies, or sounds. However, these methods lack of a good semantic understanding of what happens internally. The question, why a COVID-19 detector has classified a stack of lung-ct images as positive, is sometimes more interesting than the overall specificity and sensitivity. Especially when human domain expert knowledge disagrees with the given output. This way, human domain experts could also be advised to reconsider their choice, regarding the information pointed out by the system. In addition, the deep learning model can be controlled, and a present dataset bias can be found. Currently, most explainable AI methods in the computer vision domain are purely used on image classification, where the images are ordinary images in the visible spectrum. As a result, there is no comparison on how the methods behave with multimodal image data, as well as most methods have not been investigated on how they behave when used for object detection. This work tries to close the gaps. Firstly, investigating three saliency map generator methods on how their maps differ across the different spectra. This is achieved via accurate and systematic training. Secondly, we examine how they behave when used for object detection. As a practical problem, we chose object detection in the infrared and visual spectrum for autonomous driving. The dataset used in this work is the Multispectral Object Detection Dataset, where each scene is available in the FIR, MIR and NIR as well as visual spectrum. The results show that there are differences between the infrared and visual activation maps. Further, an advanced training with both, the infrared and visual data not only improves the network's output, it also leads to more focused spots in the saliency maps.