 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Adversarial Camouflage via Voronoi Diagrams
Jun 16, 2026Pixel-wise adversarial patches are computationally heavy and often visually detectable, limiting utility in security-critical systems. We present adversarial Voronoi camouflage that optimizes only seed-point locations under fixed, printable palettes using a soft assignment, producing structured, splinter camouflage-like patterns without additional regularization. Evaluated on person detection with COCO-style AP@[.5:.95], naive placement (Inria -> COCO) performs comparably bad, while garment-level application via segmentation mask (3DPeople) results in a significant AP drop. The attack transfers to out-of-domain backgrounds and across detector families (YOLOv9/10/11/12), indicating robustness in black-box settings. Repainting with different palettes largely nullifies the effect, and single-color tweaks show limited tolerance (<=0.17), highlighting a structure-palette coupling. The parameter-efficient, palette-constrained design improves visual plausibility while degrading real-time detector performance. Physical validation and color calibration are left for future work. Code: https://github.com/JensBayer/Voronoi This paper was originally presented at the International Conference on Military Communication and Information Systems (ICMCIS), organized by the Information Systems Technology (IST) Scientific and Technical Committee, IST-224-RSY - the ICMCIS, held in Bath, United Kingdom, 12-13 May 2026.
Higher-Order Adversarial Patches for Real-Time Object Detectors
Jan 08, 2026Higher-order adversarial attacks can directly be considered the result of a cat-and-mouse game -- an elaborate action involving constant pursuit, near captures, and repeated escapes. This idiom describes the enduring circular training of adversarial attack patterns and adversarial training the best. The following work investigates the impact of higher-order adversarial attacks on object detectors by successively training attack patterns and hardening object detectors with adversarial training. The YOLOv10 object detector is chosen as a representative, and adversarial patches are used in an evasion attack manner. Our results indicate that higher-order adversarial patches are not only affecting the object detector directly trained on but rather provide a stronger generalization capacity compared to lower-order adversarial patches. Moreover, the results highlight that solely adversarial training is not sufficient to harden an object detector efficiently against this kind of adversarial attack. Code: https://github.com/JensBayer/HigherOrder
Traversing the Subspace of Adversarial Patches
Dec 02, 2024Despite ongoing research on the topic of adversarial examples in deep learning for computer vision, some fundamentals of the nature of these attacks remain unclear. As the manifold hypothesis posits, high-dimensional data tends to be part of a low-dimensional manifold. To verify the thesis with adversarial patches, this paper provides an analysis of a set of adversarial patches and investigates the reconstruction abilities of three different dimensionality reduction methods. Quantitatively, the performance of reconstructed patches in an attack setting is measured and the impact of sampled patches from the latent space during adversarial training is investigated. The evaluation is performed on two publicly available datasets for person detection. The results indicate that more sophisticated dimensionality reduction methods offer no advantages over a simple principal component analysis.
Network transferability of adversarial patches in real-time object detection
Aug 28, 2024Adversarial patches in computer vision can be used, to fool deep neural networks and manipulate their decision-making process. One of the most prominent examples of adversarial patches are evasion attacks for object detectors. By covering parts of objects of interest, these patches suppress the detections and thus make the target object 'invisible' to the object detector. Since these patches are usually optimized on a specific network with a specific train dataset, the transferability across multiple networks and datasets is not given. This paper addresses these issues and investigates the transferability across numerous object detector architectures. Our extensive evaluation across various models on two distinct datasets indicates that patches optimized with larger models provide better network transferability than patches that are optimized with smaller models.
Strike the Balance: On-the-Fly Uncertainty based User Interactions for Long-Term Video Object Segmentation
Jul 31, 2024In this paper, we introduce a variant of video object segmentation (VOS) that bridges interactive and semi-automatic approaches, termed Lazy Video Object Segmentation (ziVOS). In contrast, to both tasks, which handle video object segmentation in an off-line manner (i.e., pre-recorded sequences), we propose through ziVOS to target online recorded sequences. Here, we strive to strike a balance between performance and robustness for long-term scenarios by soliciting user feedback's on-the-fly during the segmentation process. Hence, we aim to maximize the tracking duration of an object of interest, while requiring minimal user corrections to maintain tracking over an extended period. We propose a competitive baseline, i.e., Lazy-XMem, as a reference for future works in ziVOS. Our proposed approach uses an uncertainty estimation of the tracking state to determine whether a user interaction is necessary to refine the model's prediction. To quantitatively assess the performance of our method and the user's workload, we introduce complementary metrics alongside those already established in the field. We evaluate our approach using the recently introduced LVOS dataset, which offers numerous long-term videos. Our code is publicly available at https://github.com/Vujas-Eteph/LazyXMem.
Generating Synthetic Ground Truth Distributions for Multi-step Trajectory Prediction using Probabilistic Composite Bézier Curves
Apr 05, 2024

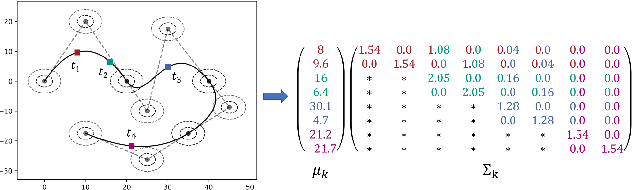

An appropriate data basis grants one of the most important aspects for training and evaluating probabilistic trajectory prediction models based on neural networks. In this regard, a common shortcoming of current benchmark datasets is their limitation to sets of sample trajectories and a lack of actual ground truth distributions, which prevents the use of more expressive error metrics, such as the Wasserstein distance for model evaluation. Towards this end, this paper proposes a novel approach to synthetic dataset generation based on composite probabilistic B\'ezier curves, which is capable of generating ground truth data in terms of probability distributions over full trajectories. This allows the calculation of arbitrary posterior distributions. The paper showcases an exemplary trajectory prediction model evaluation using generated ground truth distribution data.
Utilizing dataset affinity prediction in object detection to assess training data
Nov 16, 2023Data pooling offers various advantages, such as increasing the sample size, improving generalization, reducing sampling bias, and addressing data sparsity and quality, but it is not straightforward and may even be counterproductive. Assessing the effectiveness of pooling datasets in a principled manner is challenging due to the difficulty in estimating the overall information content of individual datasets. Towards this end, we propose incorporating a data source prediction module into standard object detection pipelines. The module runs with minimal overhead during inference time, providing additional information about the data source assigned to individual detections. We show the benefits of the so-called dataset affinity score by automatically selecting samples from a heterogeneous pool of vehicle datasets. The results show that object detectors can be trained on a significantly sparser set of training samples without losing detection accuracy.
Eigenpatches -- Adversarial Patches from Principal Components
Jun 19, 2023Adversarial patches are still a simple yet powerful white box attack that can be used to fool object detectors by suppressing possible detections. The patches of these so-called evasion attacks are computational expensive to produce and require full access to the attacked detector. This paper addresses the problem of computational expensiveness by analyzing 375 generated patches, calculating the principal components of these and show, that linear combinations of the resulting "eigenpatches" can be used to fool object detections successfully.
READMem: Robust Embedding Association for a Diverse Memory in Unconstrained Video Object Segmentation
May 22, 2023We present READMem (Robust Embedding Association for a Diverse Memory), a modular framework for semi-automatic video object segmentation (sVOS) methods designed to handle unconstrained videos. Contemporary sVOS works typically aggregate video frames in an ever-expanding memory, demanding high hardware resources for long-term applications. To mitigate memory requirements and prevent near object duplicates (caused by information of adjacent frames), previous methods introduce a hyper-parameter that controls the frequency of frames eligible to be stored. This parameter has to be adjusted according to concrete video properties (such as rapidity of appearance changes and video length) and does not generalize well. Instead, we integrate the embedding of a new frame into the memory only if it increases the diversity of the memory content. Furthermore, we propose a robust association of the embeddings stored in the memory with query embeddings during the update process. Our approach avoids the accumulation of redundant data, allowing us in return, to restrict the memory size and prevent extreme memory demands in long videos. We extend popular sVOS baselines with READMem, which previously showed limited performance on long videos. Our approach achieves competitive results on the Long-time Video dataset (LV1) while not hindering performance on short sequences. Our code is publicly available.
Bézier Curve Gaussian Processes
May 03, 2022



Probabilistic models for sequential data are the basis for a variety of applications concerned with processing timely ordered information. The predominant approach in this domain is given by neural networks, which incorporate either stochastic units or components. This paper proposes a new probabilistic sequence model building on probabilistic B\'ezier curves. Using Gaussian distributed control points, these parametric curves pose a special case for Gaussian processes (GP). Combined with a Mixture Density network, Bayesian conditional inference can be performed without the need for mean field variational approximation or Monte Carlo simulation, which is a requirement of common approaches. For assessing this hybrid model's viability, it is applied to an exemplary sequence prediction task. In this case the model is used for pedestrian trajectory prediction, where a generated prediction also serves as a GP prior. Following this, the initial prediction can be refined using the GP framework by calculating different posterior distributions, in order to adapt more towards a given observed trajectory segment.