 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSatGeo-NeRF: Geometrically Regularized NeRF for Satellite Imagery
Mar 23, 2026We present SatGeo-NeRF, a geometrically regularized NeRF for satellite imagery that mitigates overfitting-induced geometric artifacts observed in current state-of-the-art models using three model-agnostic regularizers. Gravity-Aligned Planarity Regularization aligns depth-inferred, approximated surface normals with the gravity axis to promote local planarity, coupling adjacent rays via a corresponding surface approximation to facilitate cross-ray gradient flow. Granularity Regularization enforces a coarse-to-fine geometry-learning scheme, and Depth-Supervised Regularization stabilizes early training for improved geometric accuracy. On the DFC2019 satellite reconstruction benchmark, SatGeo-NeRF improves the Mean Altitude Error by 13.9% and 11.7% relative to state-of-the-art baselines such as EO-NeRF and EO-GS.
Semantic Neural Radiance Fields for Multi-Date Satellite Data
Feb 24, 2025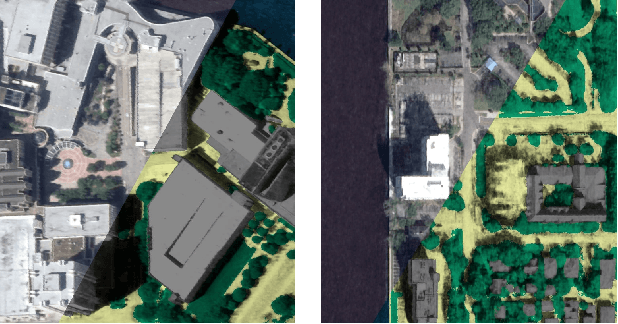
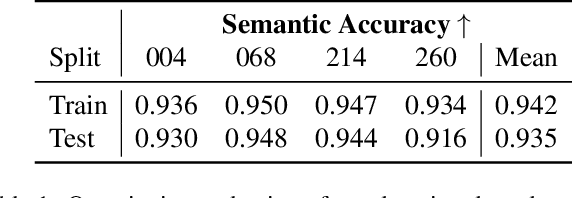
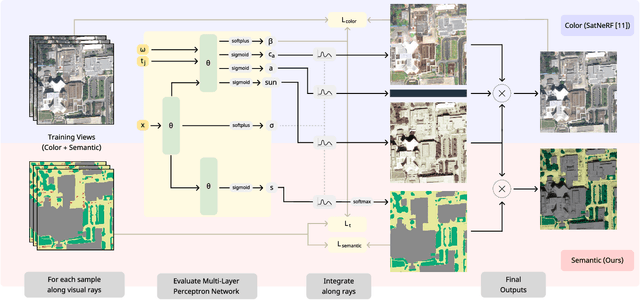
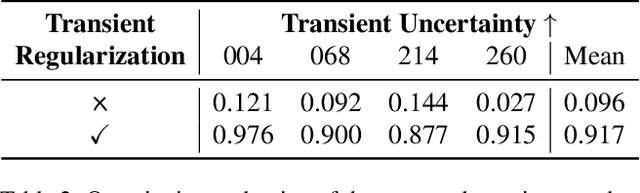
In this work we propose a satellite specific Neural Radiance Fields (NeRF) model capable to obtain a three-dimensional semantic representation (neural semantic field) of the scene. The model derives the output from a set of multi-date satellite images with corresponding pixel-wise semantic labels. We demonstrate the robustness of our approach and its capability to improve noisy input labels. We enhance the color prediction by utilizing the semantic information to address temporal image inconsistencies caused by non-stationary categories such as vehicles. To facilitate further research in this domain, we present a dataset comprising manually generated labels for popular multi-view satellite images. Our code and dataset are available at https://github.com/wagnva/semantic-nerf-for-satellite-data.
Statewide Visual Geolocalization in the Wild
Sep 25, 2024This work presents a method that is able to predict the geolocation of a street-view photo taken in the wild within a state-sized search region by matching against a database of aerial reference imagery. We partition the search region into geographical cells and train a model to map cells and corresponding photos into a joint embedding space that is used to perform retrieval at test time. The model utilizes aerial images for each cell at multiple levels-of-detail to provide sufficient information about the surrounding scene. We propose a novel layout of the search region with consistent cell resolutions that allows scaling to large geographical regions. Experiments demonstrate that the method successfully localizes 60.6% of all non-panoramic street-view photos uploaded to the crowd-sourcing platform Mapillary in the state of Massachusetts to within 50m of their ground-truth location. Source code is available at https://github.com/fferflo/statewide-visual-geolocalization.
Strike the Balance: On-the-Fly Uncertainty based User Interactions for Long-Term Video Object Segmentation
Jul 31, 2024In this paper, we introduce a variant of video object segmentation (VOS) that bridges interactive and semi-automatic approaches, termed Lazy Video Object Segmentation (ziVOS). In contrast, to both tasks, which handle video object segmentation in an off-line manner (i.e., pre-recorded sequences), we propose through ziVOS to target online recorded sequences. Here, we strive to strike a balance between performance and robustness for long-term scenarios by soliciting user feedback's on-the-fly during the segmentation process. Hence, we aim to maximize the tracking duration of an object of interest, while requiring minimal user corrections to maintain tracking over an extended period. We propose a competitive baseline, i.e., Lazy-XMem, as a reference for future works in ziVOS. Our proposed approach uses an uncertainty estimation of the tracking state to determine whether a user interaction is necessary to refine the model's prediction. To quantitatively assess the performance of our method and the user's workload, we introduce complementary metrics alongside those already established in the field. We evaluate our approach using the recently introduced LVOS dataset, which offers numerous long-term videos. Our code is publicly available at https://github.com/Vujas-Eteph/LazyXMem.
C-BEV: Contrastive Bird's Eye View Training for Cross-View Image Retrieval and 3-DoF Pose Estimation
Dec 13, 2023To find the geolocation of a street-view image, cross-view geolocalization (CVGL) methods typically perform image retrieval on a database of georeferenced aerial images and determine the location from the visually most similar match. Recent approaches focus mainly on settings where street-view and aerial images are preselected to align w.r.t. translation or orientation, but struggle in challenging real-world scenarios where varying camera poses have to be matched to the same aerial image. We propose a novel trainable retrieval architecture that uses bird's eye view (BEV) maps rather than vectors as embedding representation, and explicitly addresses the many-to-one ambiguity that arises in real-world scenarios. The BEV-based retrieval is trained using the same contrastive setting and loss as classical retrieval. Our method C-BEV surpasses the state-of-the-art on the retrieval task on multiple datasets by a large margin. It is particularly effective in challenging many-to-one scenarios, e.g. increasing the top-1 recall on VIGOR's cross-area split with unknown orientation from 31.1% to 65.0%. Although the model is supervised only through a contrastive objective applied on image pairings, it additionally learns to infer the 3-DoF camera pose on the matching aerial image, and even yields a lower mean pose error than recent methods that are explicitly trained with metric groundtruth.
Geo-Tiles for Semantic Segmentation of Earth Observation Imagery
Jun 07, 2023To cope with the high requirements during the computation of semantic segmentations of earth observation imagery, current state-of-the-art pipelines divide the corresponding data into smaller images. Existing methods and benchmark datasets oftentimes rely on pixel-based tiling schemes or on geo-tiling schemes employed by web mapping applications. The selection of subimages (comprising size, location and orientation) is crucial. It affects the available context information of each pixel, defines the number of tiles during training, and influences the degree of information degradation while down- and up-sampling the tile contents to the size required by the segmentation model. We propose a new segmentation pipeline for earth observation imagery relying on a tiling scheme that creates geo-tiles based on the geo-information of the raster data. This approach exhibits several beneficial properties compared to pixel-based or common web mapping approaches. The proposed tiling scheme shows flexible customization properties regarding tile granularity, tile stride and image boundary alignment. This allows us to perform a tile specific data augmentation during training and a substitution of pixel predictions with limited context information using data of overlapping tiles during inference. The generated tiles show a consistent spatial tile extent w.r.t. heterogeneous sensors, varying recording distances and different latitudes. We demonstrate how the proposed tiling system allows to improve the results of current state-of-the-art semantic segmentation models. To foster future research we make the source code publicly available.
READMem: Robust Embedding Association for a Diverse Memory in Unconstrained Video Object Segmentation
May 22, 2023We present READMem (Robust Embedding Association for a Diverse Memory), a modular framework for semi-automatic video object segmentation (sVOS) methods designed to handle unconstrained videos. Contemporary sVOS works typically aggregate video frames in an ever-expanding memory, demanding high hardware resources for long-term applications. To mitigate memory requirements and prevent near object duplicates (caused by information of adjacent frames), previous methods introduce a hyper-parameter that controls the frequency of frames eligible to be stored. This parameter has to be adjusted according to concrete video properties (such as rapidity of appearance changes and video length) and does not generalize well. Instead, we integrate the embedding of a new frame into the memory only if it increases the diversity of the memory content. Furthermore, we propose a robust association of the embeddings stored in the memory with query embeddings during the update process. Our approach avoids the accumulation of redundant data, allowing us in return, to restrict the memory size and prevent extreme memory demands in long videos. We extend popular sVOS baselines with READMem, which previously showed limited performance on long videos. Our approach achieves competitive results on the Long-time Video dataset (LV1) while not hindering performance on short sequences. Our code is publicly available.
Uncertainty-aware Vision-based Metric Cross-view Geolocalization
Nov 22, 2022This paper proposes a novel method for vision-based metric cross-view geolocalization (CVGL) that matches the camera images captured from a ground-based vehicle with an aerial image to determine the vehicle's geo-pose. Since aerial images are globally available at low cost, they represent a potential compromise between two established paradigms of autonomous driving, i.e. using expensive high-definition prior maps or relying entirely on the sensor data captured at runtime. We present an end-to-end differentiable model that uses the ground and aerial images to predict a probability distribution over possible vehicle poses. We combine multiple vehicle datasets with aerial images from orthophoto providers on which we demonstrate the feasibility of our method. Since the ground truth poses are often inaccurate w.r.t. the aerial images, we implement a pseudo-label approach to produce more accurate ground truth poses and make them publicly available. While previous works require training data from the target region to achieve reasonable localization accuracy (i.e. same-area evaluation), our approach overcomes this limitation and outperforms previous results even in the strictly more challenging cross-area case. We improve the previous state-of-the-art by a large margin even without ground or aerial data from the test region, which highlights the model's potential for global-scale application. We further integrate the uncertainty-aware predictions in a tracking framework to determine the vehicle's trajectory over time resulting in a mean position error on KITTI-360 of 0.78m.
Continuous Self-Localization on Aerial Images Using Visual and Lidar Sensors
Mar 07, 2022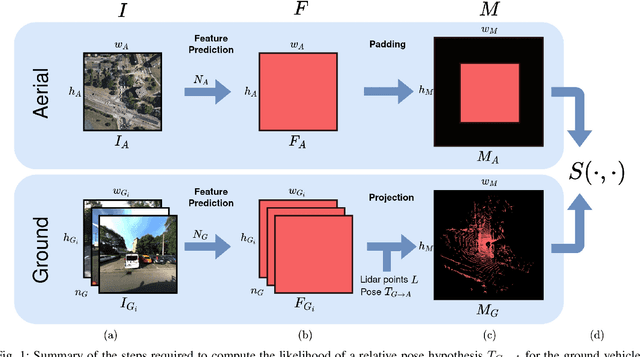
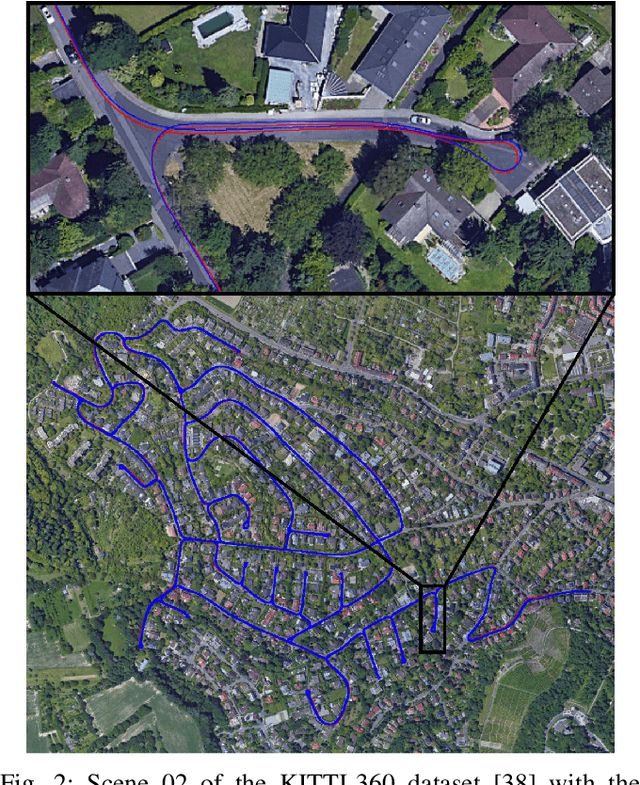
This paper proposes a novel method for geo-tracking, i.e. continuous metric self-localization in outdoor environments by registering a vehicle's sensor information with aerial imagery of an unseen target region. Geo-tracking methods offer the potential to supplant noisy signals from global navigation satellite systems (GNSS) and expensive and hard to maintain prior maps that are typically used for this purpose. The proposed geo-tracking method aligns data from on-board cameras and lidar sensors with geo-registered orthophotos to continuously localize a vehicle. We train a model in a metric learning setting to extract visual features from ground and aerial images. The ground features are projected into a top-down perspective via the lidar points and are matched with the aerial features to determine the relative pose between vehicle and orthophoto. Our method is the first to utilize on-board cameras in an end-to-end differentiable model for metric self-localization on unseen orthophotos. It exhibits strong generalization, is robust to changes in the environment and requires only geo-poses as ground truth. We evaluate our approach on the KITTI-360 dataset and achieve a mean absolute position error (APE) of 0.94m. We further compare with previous approaches on the KITTI odometry dataset and achieve state-of-the-art results on the geo-tracking task.
Revisiting Click-based Interactive Video Object Segmentation
Mar 03, 2022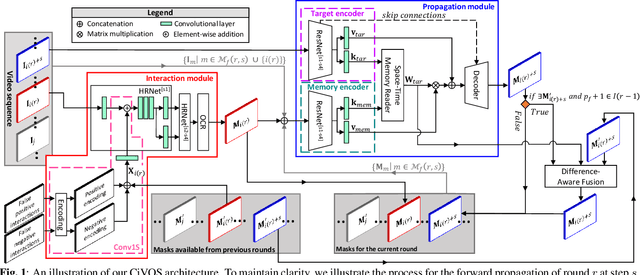
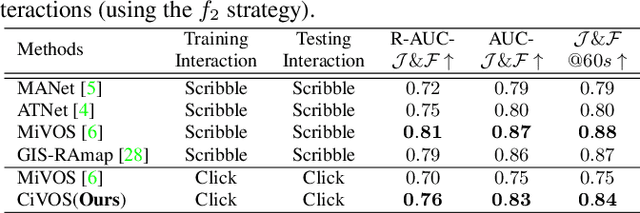
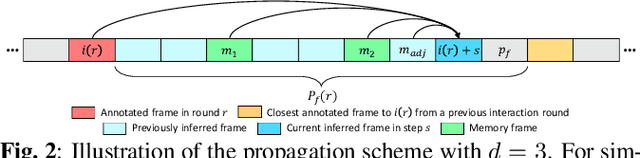

While current methods for interactive Video Object Segmentation (iVOS) rely on scribble-based interactions to generate precise object masks, we propose a Click-based interactive Video Object Segmentation (CiVOS) framework to simplify the required user workload as much as possible. CiVOS builds on de-coupled modules reflecting user interaction and mask propagation. The interaction module converts click-based interactions into an object mask, which is then inferred to the remaining frames by the propagation module. Additional user interactions allow for a refinement of the object mask. The approach is extensively evaluated on the popular interactive~DAVIS dataset, but with an inevitable adaptation of scribble-based interactions with click-based counterparts. We consider several strategies for generating clicks during our evaluation to reflect various user inputs and adjust the DAVIS performance metric to perform a hardware-independent comparison. The presented CiVOS pipeline achieves competitive results, although requiring a lower user workload.