 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Neural Radiance Fields for Multi-Date Satellite Data
Feb 24, 2025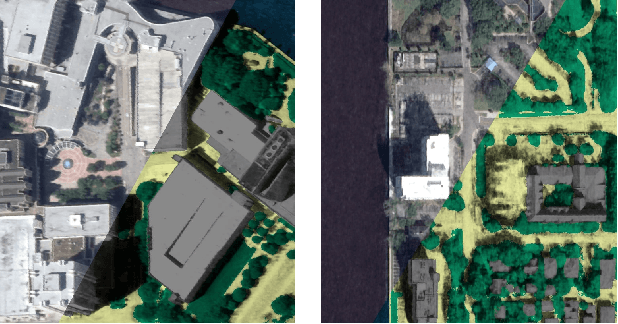
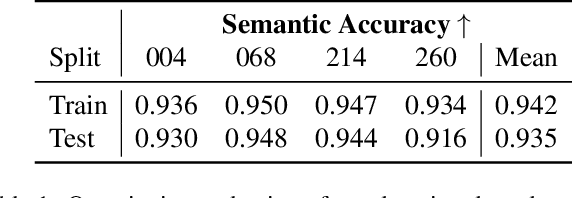
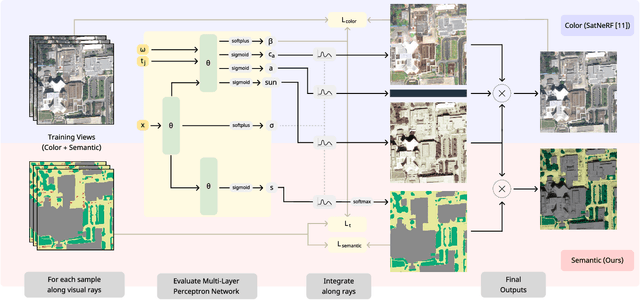
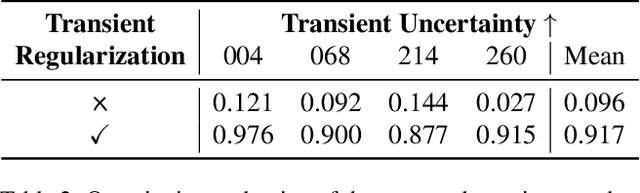
In this work we propose a satellite specific Neural Radiance Fields (NeRF) model capable to obtain a three-dimensional semantic representation (neural semantic field) of the scene. The model derives the output from a set of multi-date satellite images with corresponding pixel-wise semantic labels. We demonstrate the robustness of our approach and its capability to improve noisy input labels. We enhance the color prediction by utilizing the semantic information to address temporal image inconsistencies caused by non-stationary categories such as vehicles. To facilitate further research in this domain, we present a dataset comprising manually generated labels for popular multi-view satellite images. Our code and dataset are available at https://github.com/wagnva/semantic-nerf-for-satellite-data.
Statewide Visual Geolocalization in the Wild
Sep 25, 2024This work presents a method that is able to predict the geolocation of a street-view photo taken in the wild within a state-sized search region by matching against a database of aerial reference imagery. We partition the search region into geographical cells and train a model to map cells and corresponding photos into a joint embedding space that is used to perform retrieval at test time. The model utilizes aerial images for each cell at multiple levels-of-detail to provide sufficient information about the surrounding scene. We propose a novel layout of the search region with consistent cell resolutions that allows scaling to large geographical regions. Experiments demonstrate that the method successfully localizes 60.6% of all non-panoramic street-view photos uploaded to the crowd-sourcing platform Mapillary in the state of Massachusetts to within 50m of their ground-truth location. Source code is available at https://github.com/fferflo/statewide-visual-geolocalization.
C-BEV: Contrastive Bird's Eye View Training for Cross-View Image Retrieval and 3-DoF Pose Estimation
Dec 13, 2023To find the geolocation of a street-view image, cross-view geolocalization (CVGL) methods typically perform image retrieval on a database of georeferenced aerial images and determine the location from the visually most similar match. Recent approaches focus mainly on settings where street-view and aerial images are preselected to align w.r.t. translation or orientation, but struggle in challenging real-world scenarios where varying camera poses have to be matched to the same aerial image. We propose a novel trainable retrieval architecture that uses bird's eye view (BEV) maps rather than vectors as embedding representation, and explicitly addresses the many-to-one ambiguity that arises in real-world scenarios. The BEV-based retrieval is trained using the same contrastive setting and loss as classical retrieval. Our method C-BEV surpasses the state-of-the-art on the retrieval task on multiple datasets by a large margin. It is particularly effective in challenging many-to-one scenarios, e.g. increasing the top-1 recall on VIGOR's cross-area split with unknown orientation from 31.1% to 65.0%. Although the model is supervised only through a contrastive objective applied on image pairings, it additionally learns to infer the 3-DoF camera pose on the matching aerial image, and even yields a lower mean pose error than recent methods that are explicitly trained with metric groundtruth.
Geo-Tiles for Semantic Segmentation of Earth Observation Imagery
Jun 07, 2023To cope with the high requirements during the computation of semantic segmentations of earth observation imagery, current state-of-the-art pipelines divide the corresponding data into smaller images. Existing methods and benchmark datasets oftentimes rely on pixel-based tiling schemes or on geo-tiling schemes employed by web mapping applications. The selection of subimages (comprising size, location and orientation) is crucial. It affects the available context information of each pixel, defines the number of tiles during training, and influences the degree of information degradation while down- and up-sampling the tile contents to the size required by the segmentation model. We propose a new segmentation pipeline for earth observation imagery relying on a tiling scheme that creates geo-tiles based on the geo-information of the raster data. This approach exhibits several beneficial properties compared to pixel-based or common web mapping approaches. The proposed tiling scheme shows flexible customization properties regarding tile granularity, tile stride and image boundary alignment. This allows us to perform a tile specific data augmentation during training and a substitution of pixel predictions with limited context information using data of overlapping tiles during inference. The generated tiles show a consistent spatial tile extent w.r.t. heterogeneous sensors, varying recording distances and different latitudes. We demonstrate how the proposed tiling system allows to improve the results of current state-of-the-art semantic segmentation models. To foster future research we make the source code publicly available.
Uncertainty-aware Vision-based Metric Cross-view Geolocalization
Nov 22, 2022This paper proposes a novel method for vision-based metric cross-view geolocalization (CVGL) that matches the camera images captured from a ground-based vehicle with an aerial image to determine the vehicle's geo-pose. Since aerial images are globally available at low cost, they represent a potential compromise between two established paradigms of autonomous driving, i.e. using expensive high-definition prior maps or relying entirely on the sensor data captured at runtime. We present an end-to-end differentiable model that uses the ground and aerial images to predict a probability distribution over possible vehicle poses. We combine multiple vehicle datasets with aerial images from orthophoto providers on which we demonstrate the feasibility of our method. Since the ground truth poses are often inaccurate w.r.t. the aerial images, we implement a pseudo-label approach to produce more accurate ground truth poses and make them publicly available. While previous works require training data from the target region to achieve reasonable localization accuracy (i.e. same-area evaluation), our approach overcomes this limitation and outperforms previous results even in the strictly more challenging cross-area case. We improve the previous state-of-the-art by a large margin even without ground or aerial data from the test region, which highlights the model's potential for global-scale application. We further integrate the uncertainty-aware predictions in a tracking framework to determine the vehicle's trajectory over time resulting in a mean position error on KITTI-360 of 0.78m.
Continuous Self-Localization on Aerial Images Using Visual and Lidar Sensors
Mar 07, 2022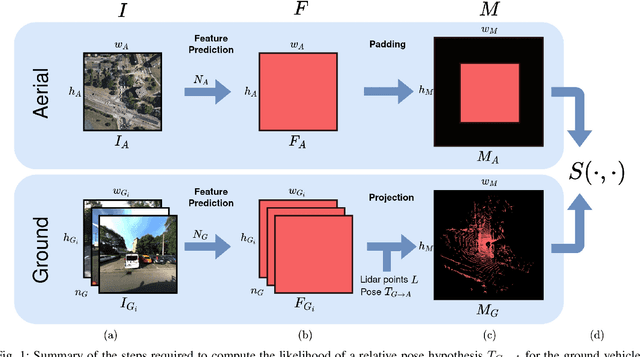
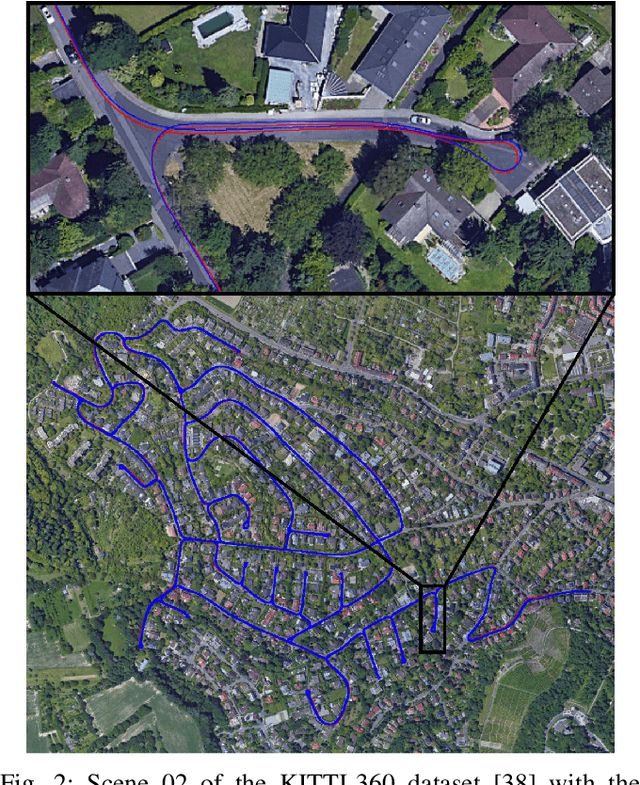
This paper proposes a novel method for geo-tracking, i.e. continuous metric self-localization in outdoor environments by registering a vehicle's sensor information with aerial imagery of an unseen target region. Geo-tracking methods offer the potential to supplant noisy signals from global navigation satellite systems (GNSS) and expensive and hard to maintain prior maps that are typically used for this purpose. The proposed geo-tracking method aligns data from on-board cameras and lidar sensors with geo-registered orthophotos to continuously localize a vehicle. We train a model in a metric learning setting to extract visual features from ground and aerial images. The ground features are projected into a top-down perspective via the lidar points and are matched with the aerial features to determine the relative pose between vehicle and orthophoto. Our method is the first to utilize on-board cameras in an end-to-end differentiable model for metric self-localization on unseen orthophotos. It exhibits strong generalization, is robust to changes in the environment and requires only geo-poses as ground truth. We evaluate our approach on the KITTI-360 dataset and achieve a mean absolute position error (APE) of 0.94m. We further compare with previous approaches on the KITTI odometry dataset and achieve state-of-the-art results on the geo-tracking task.
Improving Semantic Image Segmentation via Label Fusion in Semantically Textured Meshes
Nov 22, 2021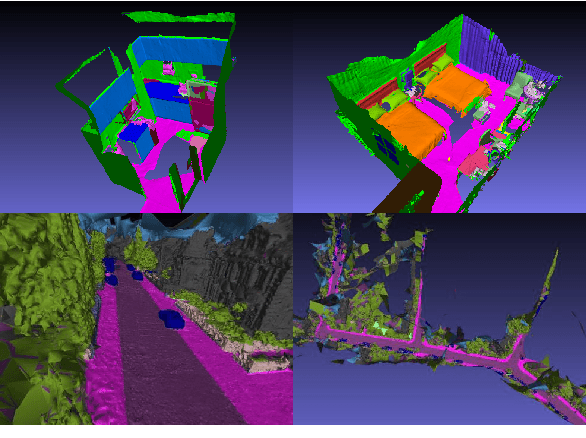

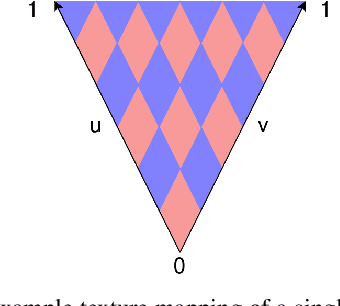
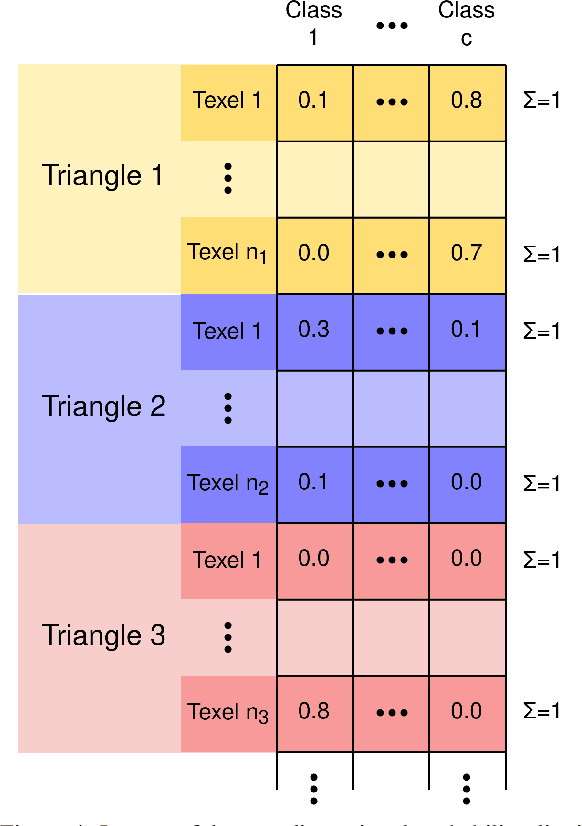
Models for semantic segmentation require a large amount of hand-labeled training data which is costly and time-consuming to produce. For this purpose, we present a label fusion framework that is capable of improving semantic pixel labels of video sequences in an unsupervised manner. We make use of a 3D mesh representation of the environment and fuse the predictions of different frames into a consistent representation using semantic mesh textures. Rendering the semantic mesh using the original intrinsic and extrinsic camera parameters yields a set of improved semantic segmentation images. Due to our optimized CUDA implementation, we are able to exploit the entire $c$-dimensional probability distribution of annotations over $c$ classes in an uncertainty-aware manner. We evaluate our method on the Scannet dataset where we improve annotations produced by the state-of-the-art segmentation network ESANet from $52.05 \%$ to $58.25 \%$ pixel accuracy. We publish the source code of our framework online to foster future research in this area (\url{https://github.com/fferflo/semantic-meshes}). To the best of our knowledge, this is the first publicly available label fusion framework for semantic image segmentation based on meshes with semantic textures.
3D Surface Reconstruction From Multi-Date Satellite Images
Feb 04, 2021


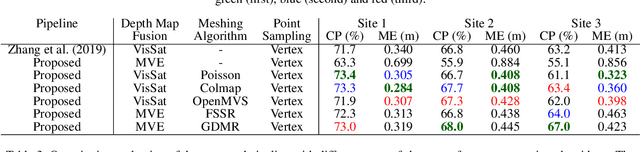
The reconstruction of accurate three-dimensional environment models is one of the most fundamental goals in the field of photogrammetry. Since satellite images provide suitable properties for obtaining large-scale environment reconstructions, there exist a variety of Stereo Matching based methods to reconstruct point clouds for satellite image pairs. Recently, the first Structure from Motion (SfM) based approach has been proposed, which allows to reconstruct point clouds from multiple satellite images. In this work, we propose an extension of this SfM based pipeline that allows us to reconstruct not only point clouds but watertight meshes including texture information. We provide a detailed description of several steps that are mandatory to exploit state-of-the-art mesh reconstruction algorithms in the context of satellite imagery. This includes a decomposition of finite projective camera calibration matrices, a skew correction of corresponding depth maps and input images as well as the recovery of real-world depth maps from reparameterized depth values. The paper presents an extensive quantitative evaluation on multi-date satellite images demonstrating that the proposed pipeline combined with current meshing algorithms outperforms state-of-the-art point cloud reconstruction algorithms in terms of completeness and median error. We make the source code of our pipeline publicly available.
A Photogrammetry-based Framework to Facilitate Image-based Modeling and Automatic Camera Tracking
Dec 02, 2020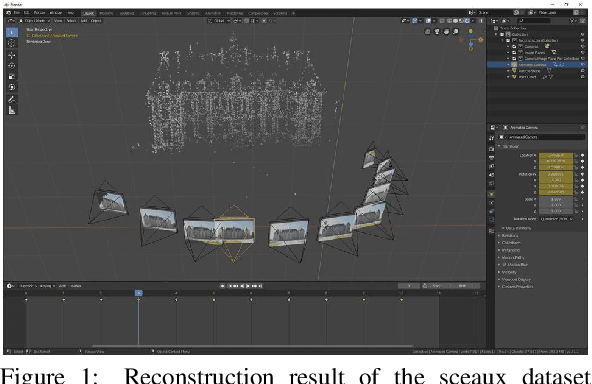
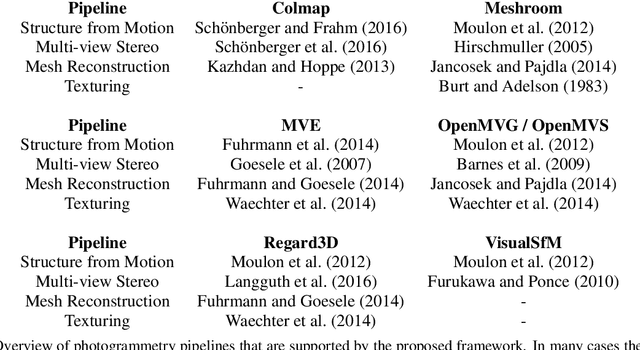
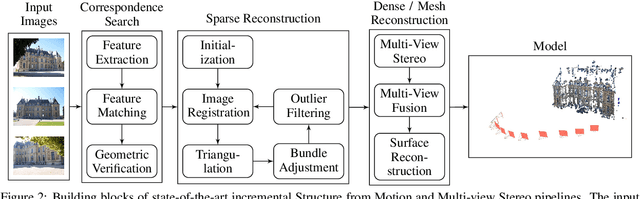

We propose a framework that extends Blender to exploit Structure from Motion (SfM) and Multi-View Stereo (MVS) techniques for image-based modeling tasks such as sculpting or camera and motion tracking. Applying SfM allows us to determine camera motions without manually defining feature tracks or calibrating the cameras used to capture the image data. With MVS we are able to automatically compute dense scene models, which is not feasible with the built-in tools of Blender. Currently, our framework supports several state-of-the-art SfM and MVS pipelines. The modular system design enables us to integrate further approaches without additional effort. The framework is publicly available as an open source software package.
Stereo 3D Object Trajectory Reconstruction
Aug 27, 2018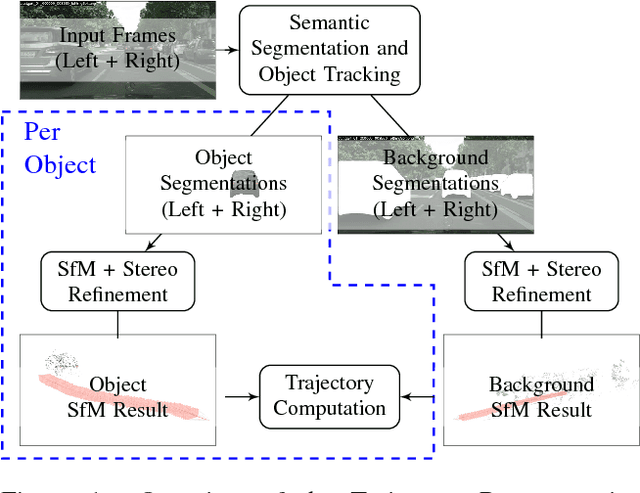
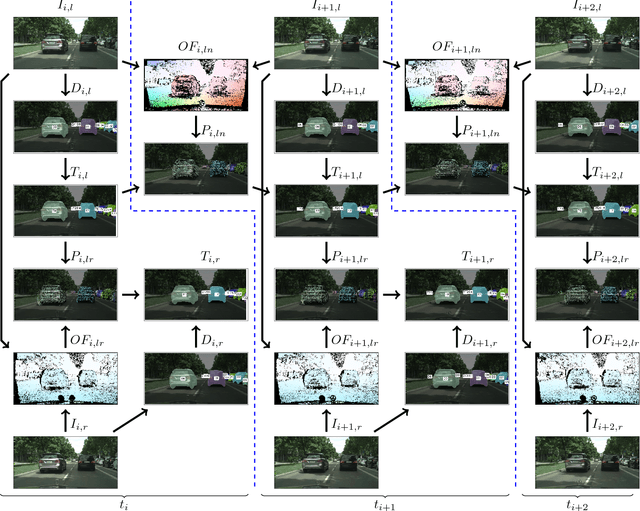

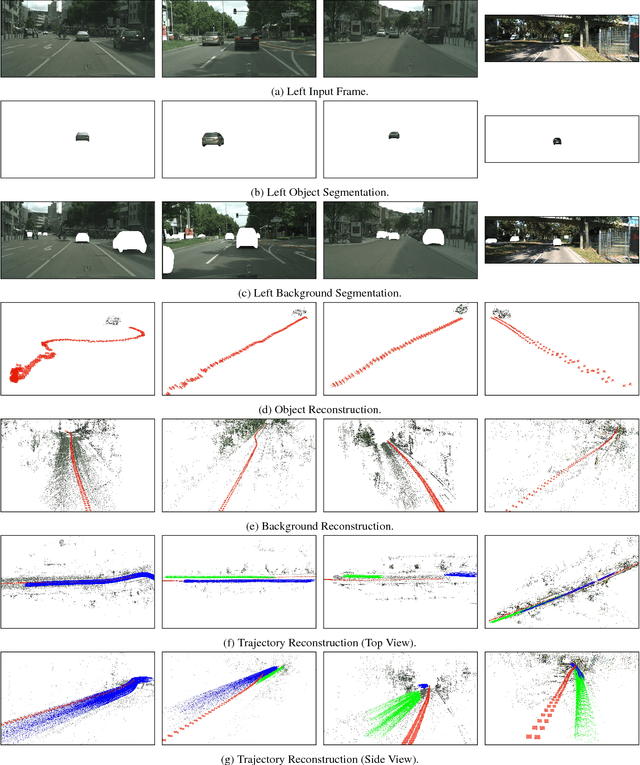
We present a method to reconstruct the three-dimensional trajectory of a moving instance of a known object category using stereo video data. We track the two-dimensional shape of objects on pixel level exploiting instance-aware semantic segmentation techniques and optical flow cues. We apply Structure from Motion (SfM) techniques to object and background images to determine for each frame initial camera poses relative to object instances and background structures. We refine the initial SfM results by integrating stereo camera constraints exploiting factor graphs. We compute the object trajectory by combining object and background camera pose information. In contrast to stereo matching methods, our approach leverages temporal adjacent views for object point triangulation. As opposed to monocular trajectory reconstruction approaches, our method shows no degenerated cases. We evaluate our approach using publicly available video data of vehicles in urban scenes.