 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollectiveSFT: Scaling Large Language Models for Chinese Medical Benchmark with Collective Instructions in Healthcare
Jul 29, 2024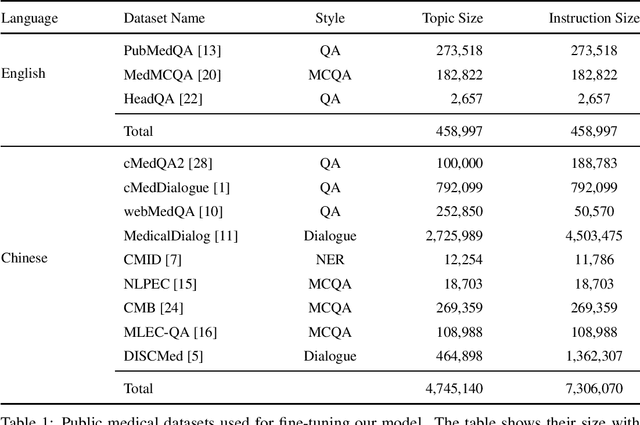

The rapid progress in Large Language Models (LLMs) has prompted the creation of numerous benchmarks to evaluate their capabilities.This study focuses on the Comprehensive Medical Benchmark in Chinese (CMB), showcasing how dataset diversity and distribution in supervised fine-tuning (SFT) may enhance LLM performance.Remarkably, We successfully trained a smaller base model to achieve scores comparable to larger models, indicating that a diverse and well-distributed dataset can optimize performance regardless of model size.This study suggests that even smaller models may reach high performance levels with carefully curated and varied datasets.By integrating a wide range of instructional content, our approach addresses potential issues such as data quality inconsistencies. Our results imply that a broader spectrum of training data may enhance a model's ability to generalize and perform effectively across different medical scenarios, highlighting the importance of dataset quality and diversity in fine-tuning processes.