 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Edit: Enabling Instructional Image Editing with In-Context Generation in Large Scale Diffusion Transformer
Apr 29, 2025Instruction-based image editing enables robust image modification via natural language prompts, yet current methods face a precision-efficiency tradeoff. Fine-tuning methods demand significant computational resources and large datasets, while training-free techniques struggle with instruction comprehension and edit quality. We resolve this dilemma by leveraging large-scale Diffusion Transformer (DiT)' enhanced generation capacity and native contextual awareness. Our solution introduces three contributions: (1) an in-context editing framework for zero-shot instruction compliance using in-context prompting, avoiding structural changes; (2) a LoRA-MoE hybrid tuning strategy that enhances flexibility with efficient adaptation and dynamic expert routing, without extensive retraining; and (3) an early filter inference-time scaling method using vision-language models (VLMs) to select better initial noise early, improving edit quality. Extensive evaluations demonstrate our method's superiority: it outperforms state-of-the-art approaches while requiring only 0.5% training data and 1% trainable parameters compared to conventional baselines. This work establishes a new paradigm that enables high-precision yet efficient instruction-guided editing. Codes and demos can be found in https://river-zhang.github.io/ICEdit-gh-pages/.
Rethinking the Architecture Design for Efficient Generic Event Boundary Detection
Jul 17, 2024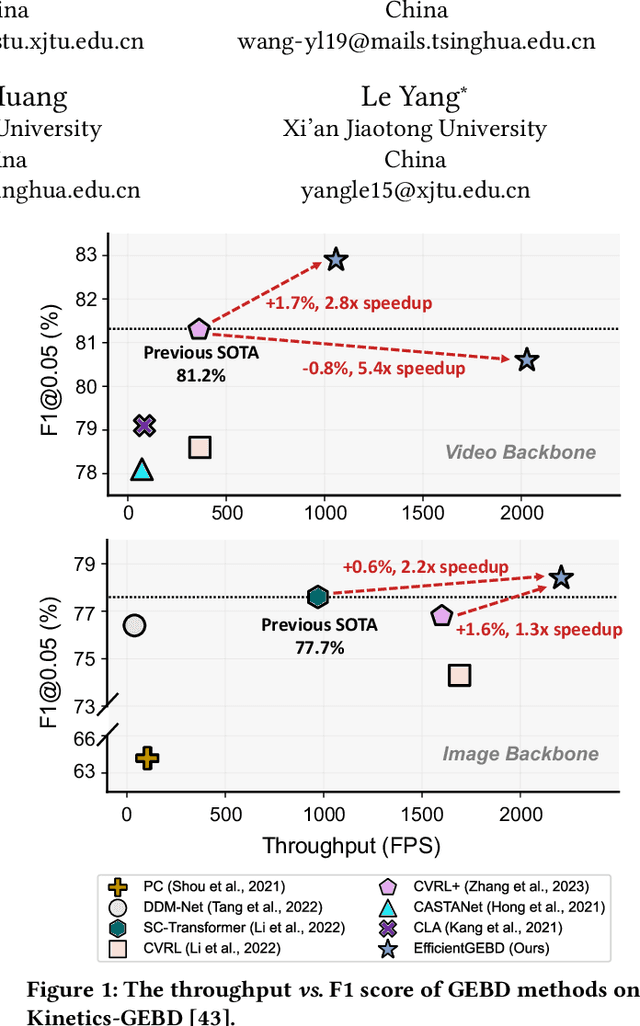

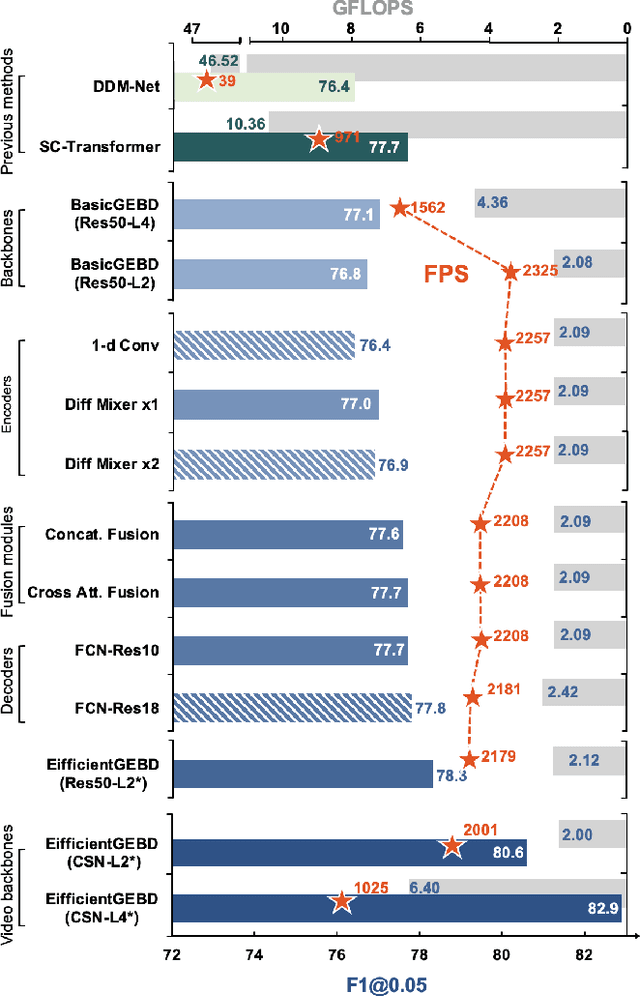

Generic event boundary detection (GEBD), inspired by human visual cognitive behaviors of consistently segmenting videos into meaningful temporal chunks, finds utility in various applications such as video editing and. In this paper, we demonstrate that SOTA GEBD models often prioritize final performance over model complexity, resulting in low inference speed and hindering efficient deployment in real-world scenarios. We contribute to addressing this challenge by experimentally reexamining the architecture of GEBD models and uncovering several surprising findings. Firstly, we reveal that a concise GEBD baseline model already achieves promising performance without any sophisticated design. Secondly, we find that the widely applied image-domain backbones in GEBD models can contain plenty of architecture redundancy, motivating us to gradually ``modernize'' each component to enhance efficiency. Thirdly, we show that the GEBD models using image-domain backbones conducting the spatiotemporal learning in a spatial-then-temporal greedy manner can suffer from a distraction issue, which might be the inefficient villain for GEBD. Using a video-domain backbone to jointly conduct spatiotemporal modeling is an effective solution for this issue. The outcome of our exploration is a family of GEBD models, named EfficientGEBD, significantly outperforms the previous SOTA methods by up to 1.7\% performance gain and 280\% speedup under the same backbone. Our research prompts the community to design modern GEBD methods with the consideration of model complexity, particularly in resource-aware applications. The code is available at \url{https://github.com/Ziwei-Zheng/EfficientGEBD}.
SIFU: Side-view Conditioned Implicit Function for Real-world Usable Clothed Human Reconstruction
Dec 10, 2023Creating high-quality 3D models of clothed humans from single images for real-world applications is crucial. Despite recent advancements, accurately reconstructing humans in complex poses or with loose clothing from in-the-wild images, along with predicting textures for unseen areas, remains a significant challenge. A key limitation of previous methods is their insufficient prior guidance in transitioning from 2D to 3D and in texture prediction. In response, we introduce SIFU (Side-view Conditioned Implicit Function for Real-world Usable Clothed Human Reconstruction), a novel approach combining a Side-view Decoupling Transformer with a 3D Consistent Texture Refinement pipeline.SIFU employs a cross-attention mechanism within the transformer, using SMPL-X normals as queries to effectively decouple side-view features in the process of mapping 2D features to 3D. This method not only improves the precision of the 3D models but also their robustness, especially when SMPL-X estimates are not perfect. Our texture refinement process leverages text-to-image diffusion-based prior to generate realistic and consistent textures for invisible views. Through extensive experiments, SIFU surpasses SOTA methods in both geometry and texture reconstruction, showcasing enhanced robustness in complex scenarios and achieving an unprecedented Chamfer and P2S measurement. Our approach extends to practical applications such as 3D printing and scene building, demonstrating its broad utility in real-world scenarios. Project page https://river-zhang.github.io/SIFU-projectpage/ .
Global-correlated 3D-decoupling Transformer for Clothed Avatar Reconstruction
Sep 26, 2023Reconstructing 3D clothed human avatars from single images is a challenging task, especially when encountering complex poses and loose clothing. Current methods exhibit limitations in performance, largely attributable to their dependence on insufficient 2D image features and inconsistent query methods. Owing to this, we present the Global-correlated 3D-decoupling Transformer for clothed Avatar reconstruction (GTA), a novel transformer-based architecture that reconstructs clothed human avatars from monocular images. Our approach leverages transformer architectures by utilizing a Vision Transformer model as an encoder for capturing global-correlated image features. Subsequently, our innovative 3D-decoupling decoder employs cross-attention to decouple tri-plane features, using learnable embeddings as queries for cross-plane generation. To effectively enhance feature fusion with the tri-plane 3D feature and human body prior, we propose a hybrid prior fusion strategy combining spatial and prior-enhanced queries, leveraging the benefits of spatial localization and human body prior knowledge. Comprehensive experiments on CAPE and THuman2.0 datasets illustrate that our method outperforms state-of-the-art approaches in both geometry and texture reconstruction, exhibiting high robustness to challenging poses and loose clothing, and producing higher-resolution textures. Codes will be available at https://github.com/River-Zhang/GTA.