 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking the Architecture Design for Efficient Generic Event Boundary Detection
Paper and Code
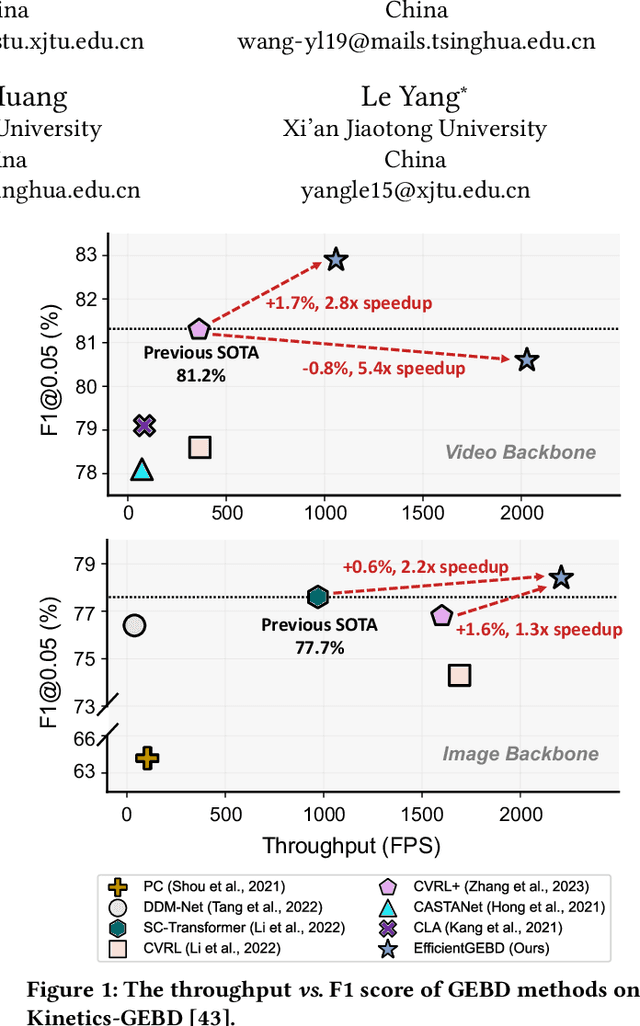

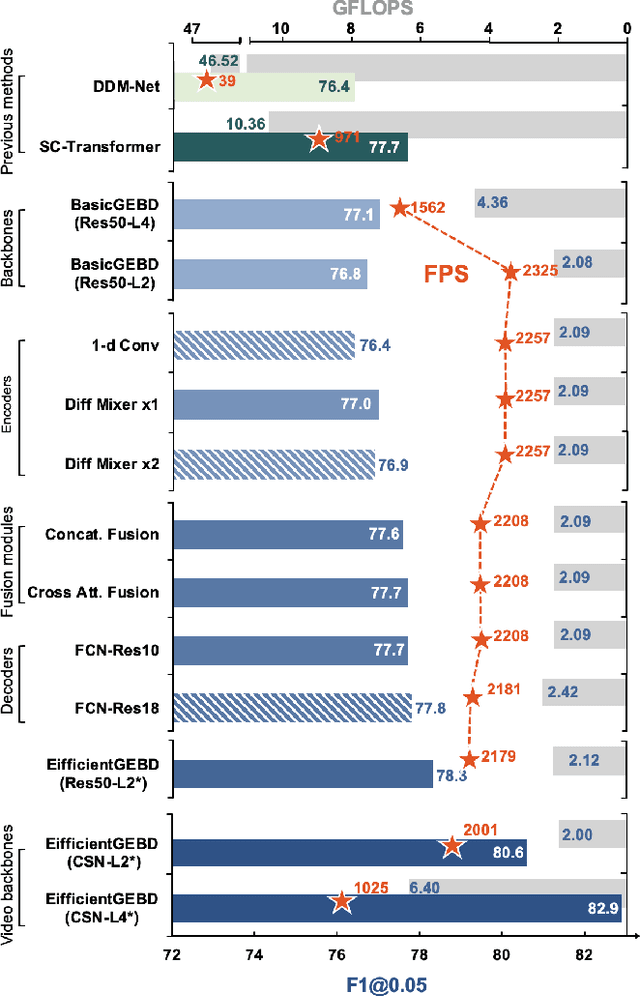

Generic event boundary detection (GEBD), inspired by human visual cognitive behaviors of consistently segmenting videos into meaningful temporal chunks, finds utility in various applications such as video editing and. In this paper, we demonstrate that SOTA GEBD models often prioritize final performance over model complexity, resulting in low inference speed and hindering efficient deployment in real-world scenarios. We contribute to addressing this challenge by experimentally reexamining the architecture of GEBD models and uncovering several surprising findings. Firstly, we reveal that a concise GEBD baseline model already achieves promising performance without any sophisticated design. Secondly, we find that the widely applied image-domain backbones in GEBD models can contain plenty of architecture redundancy, motivating us to gradually ``modernize'' each component to enhance efficiency. Thirdly, we show that the GEBD models using image-domain backbones conducting the spatiotemporal learning in a spatial-then-temporal greedy manner can suffer from a distraction issue, which might be the inefficient villain for GEBD. Using a video-domain backbone to jointly conduct spatiotemporal modeling is an effective solution for this issue. The outcome of our exploration is a family of GEBD models, named EfficientGEBD, significantly outperforms the previous SOTA methods by up to 1.7\% performance gain and 280\% speedup under the same backbone. Our research prompts the community to design modern GEBD methods with the consideration of model complexity, particularly in resource-aware applications. The code is available at \url{https://github.com/Ziwei-Zheng/EfficientGEBD}.