 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPA-Pack: Object-Property-Aware Robotic Bin Packing
May 19, 2025Robotic bin packing aids in a wide range of real-world scenarios such as e-commerce and warehouses. Yet, existing works focus mainly on considering the shape of objects to optimize packing compactness and neglect object properties such as fragility, edibility, and chemistry that humans typically consider when packing objects. This paper presents OPA-Pack (Object-Property-Aware Packing framework), the first framework that equips the robot with object property considerations in planning the object packing. Technical-wise, we develop a novel object property recognition scheme with retrieval-augmented generation and chain-of-thought reasoning, and build a dataset with object property annotations for 1,032 everyday objects. Also, we formulate OPA-Net, aiming to jointly separate incompatible object pairs and reduce pressure on fragile objects, while compacting the packing. Further, OPA-Net consists of a property embedding layer to encode the property of candidate objects to be packed, together with a fragility heightmap and an avoidance heightmap to keep track of the packed objects. Then, we design a reward function and adopt a deep Q-learning scheme to train OPA-Net. Experimental results manifest that OPA-Pack greatly improves the accuracy of separating incompatible object pairs (from 52% to 95%) and largely reduces pressure on fragile objects (by 29.4%), while maintaining good packing compactness. Besides, we demonstrate the effectiveness of OPA-Pack on a real packing platform, showcasing its practicality in real-world scenarios.
SKU-Patch: Towards Efficient Instance Segmentation for Unseen Objects in Auto-Store
Nov 08, 2023



In large-scale storehouses, precise instance masks are crucial for robotic bin picking but are challenging to obtain. Existing instance segmentation methods typically rely on a tedious process of scene collection, mask annotation, and network fine-tuning for every single Stock Keeping Unit (SKU). This paper presents SKU-Patch, a new patch-guided instance segmentation solution, leveraging only a few image patches for each incoming new SKU to predict accurate and robust masks, without tedious manual effort and model re-training. Technical-wise, we design a novel transformer-based network with (i) a patch-image correlation encoder to capture multi-level image features calibrated by patch information and (ii) a patch-aware transformer decoder with parallel task heads to generate instance masks. Extensive experiments on four storehouse benchmarks manifest that SKU-Patch is able to achieve the best performance over the state-of-the-art methods. Also, SKU-Patch yields an average of nearly 100% grasping success rate on more than 50 unseen SKUs in a robot-aided auto-store logistic pipeline, showing its effectiveness and practicality.
SDF-Pack: Towards Compact Bin Packing with Signed-Distance-Field Minimization
Jul 14, 2023Robotic bin packing is very challenging, especially when considering practical needs such as object variety and packing compactness. This paper presents SDF-Pack, a new approach based on signed distance field (SDF) to model the geometric condition of objects in a container and compute the object placement locations and packing orders for achieving a more compact bin packing. Our method adopts a truncated SDF representation to localize the computation, and based on it, we formulate the SDF minimization heuristic to find optimized placements to compactly pack objects with the existing ones. To further improve space utilization, if the packing sequence is controllable, our method can suggest which object to be packed next. Experimental results on a large variety of everyday objects show that our method can consistently achieve higher packing compactness over 1,000 packing cases, enabling us to pack more objects into the container, compared with the existing heuristics under various packing settings.
Accurate Grid Keypoint Learning for Efficient Video Prediction
Jul 28, 2021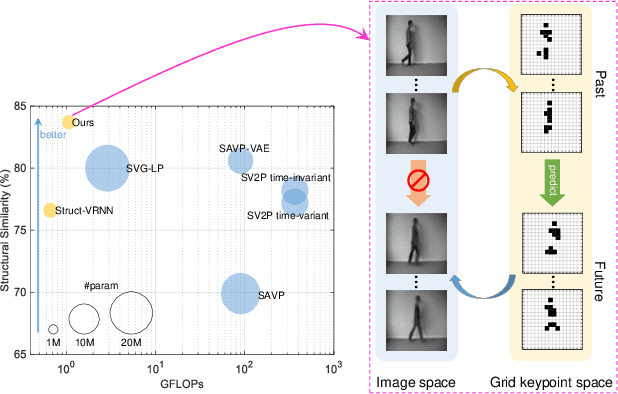
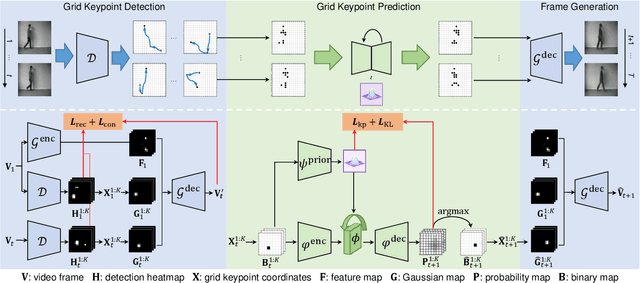
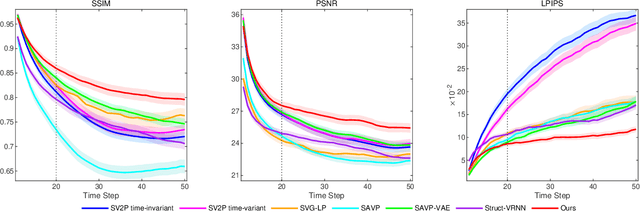

Video prediction methods generally consume substantial computing resources in training and deployment, among which keypoint-based approaches show promising improvement in efficiency by simplifying dense image prediction to light keypoint prediction. However, keypoint locations are often modeled only as continuous coordinates, so noise from semantically insignificant deviations in videos easily disrupt learning stability, leading to inaccurate keypoint modeling. In this paper, we design a new grid keypoint learning framework, aiming at a robust and explainable intermediate keypoint representation for long-term efficient video prediction. We have two major technical contributions. First, we detect keypoints by jumping among candidate locations in our raised grid space and formulate a condensation loss to encourage meaningful keypoints with strong representative capability. Second, we introduce a 2D binary map to represent the detected grid keypoints and then suggest propagating keypoint locations with stochasticity by selecting entries in the discrete grid space, thus preserving the spatial structure of keypoints in the longterm horizon for better future frame generation. Extensive experiments verify that our method outperforms the state-ofthe-art stochastic video prediction methods while saves more than 98% of computing resources. We also demonstrate our method on a robotic-assisted surgery dataset with promising results. Our code is available at https://github.com/xjgaocs/Grid-Keypoint-Learning.
Future Frame Prediction for Robot-assisted Surgery
Mar 18, 2021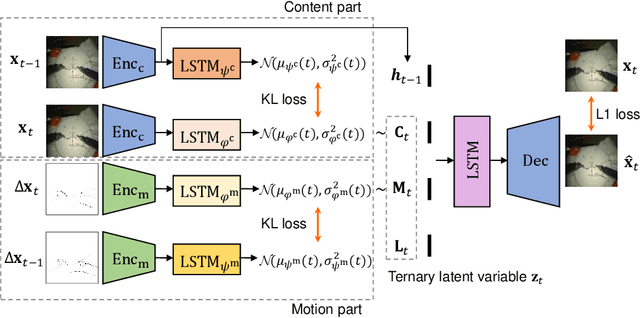
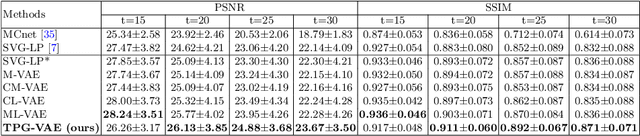

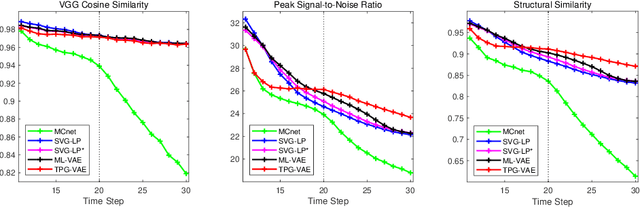
Predicting future frames for robotic surgical video is an interesting, important yet extremely challenging problem, given that the operative tasks may have complex dynamics. Existing approaches on future prediction of natural videos were based on either deterministic models or stochastic models, including deep recurrent neural networks, optical flow, and latent space modeling. However, the potential in predicting meaningful movements of robots with dual arms in surgical scenarios has not been tapped so far, which is typically more challenging than forecasting independent motions of one arm robots in natural scenarios. In this paper, we propose a ternary prior guided variational autoencoder (TPG-VAE) model for future frame prediction in robotic surgical video sequences. Besides content distribution, our model learns motion distribution, which is novel to handle the small movements of surgical tools. Furthermore, we add the invariant prior information from the gesture class into the generation process to constrain the latent space of our model. To our best knowledge, this is the first time that the future frames of dual arm robots are predicted considering their unique characteristics relative to general robotic videos. Experiments demonstrate that our model gains more stable and realistic future frame prediction scenes with the suturing task on the public JIGSAWS dataset.
Trans-SVNet: Accurate Phase Recognition from Surgical Videos via Hybrid Embedding Aggregation Transformer
Mar 17, 2021



Real-time surgical phase recognition is a fundamental task in modern operating rooms. Previous works tackle this task relying on architectures arranged in spatio-temporal order, however, the supportive benefits of intermediate spatial features are not considered. In this paper, we introduce, for the first time in surgical workflow analysis, Transformer to reconsider the ignored complementary effects of spatial and temporal features for accurate surgical phase recognition. Our hybrid embedding aggregation Transformer fuses cleverly designed spatial and temporal embeddings by allowing for active queries based on spatial information from temporal embedding sequences. More importantly, our framework is lightweight and processes the hybrid embeddings in parallel to achieve a high inference speed. Our method is thoroughly validated on two large surgical video datasets, i.e., Cholec80 and M2CAI16 Challenge datasets, and significantly outperforms the state-of-the-art approaches at a processing speed of 91 fps.
Learning Motion Flows for Semi-supervised Instrument Segmentation from Robotic Surgical Video
Jul 06, 2020

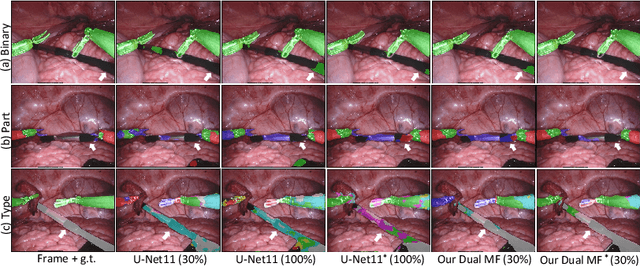
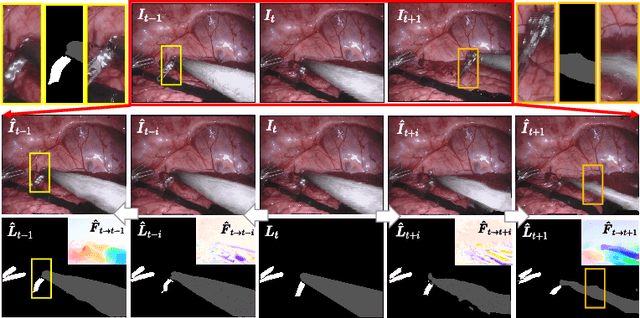
Performing low hertz labeling for surgical videos at intervals can greatly releases the burden of surgeons. In this paper, we study the semi-supervised instrument segmentation from robotic surgical videos with sparse annotations. Unlike most previous methods using unlabeled frames individually, we propose a dual motion based method to wisely learn motion flows for segmentation enhancement by leveraging temporal dynamics. We firstly design a flow predictor to derive the motion for jointly propagating the frame-label pairs given the current labeled frame. Considering the fast instrument motion, we further introduce a flow compensator to estimate intermediate motion within continuous frames, with a novel cycle learning strategy. By exploiting generated data pairs, our framework can recover and even enhance temporal consistency of training sequences to benefit segmentation. We validate our framework with binary, part, and type tasks on 2017 MICCAI EndoVis Robotic Instrument Segmentation Challenge dataset. Results show that our method outperforms the state-of-the-art semi-supervised methods by a large margin, and even exceeds fully supervised training on two tasks.
Automatic Gesture Recognition in Robot-assisted Surgery with Reinforcement Learning and Tree Search
Feb 20, 2020
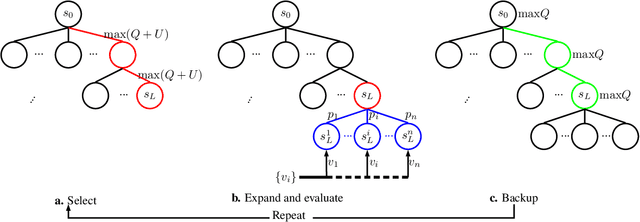


Automatic surgical gesture recognition is fundamental for improving intelligence in robot-assisted surgery, such as conducting complicated tasks of surgery surveillance and skill evaluation. However, current methods treat each frame individually and produce the outcomes without effective consideration on future information. In this paper, we propose a framework based on reinforcement learning and tree search for joint surgical gesture segmentation and classification. An agent is trained to segment and classify the surgical video in a human-like manner whose direct decisions are re-considered by tree search appropriately. Our proposed tree search algorithm unites the outputs from two designed neural networks, i.e., policy and value network. With the integration of complementary information from distinct models, our framework is able to achieve the better performance than baseline methods using either of the neural networks. For an overall evaluation, our developed approach consistently outperforms the existing methods on the suturing task of JIGSAWS dataset in terms of accuracy, edit score and F1 score. Our study highlights the utilization of tree search to refine actions in reinforcement learning framework for surgical robotic applications.
A* Tree Search for Portfolio Management
Jan 07, 2019



We propose a planning-based method to teach an agent to manage portfolio from scratch. Our approach combines deep reinforcement learning techniques with search techniques like AlphaGo. By uniting the advantages in A* search algorithm with Monte Carlo tree search, we come up with a new algorithm named A* tree search in which best information is returned to guide next search. Also, the expansion mode of Monte Carlo tree is improved for a higher utilization of the neural network. The suggested algorithm can also optimize non-differentiable utility function by combinatorial search. This technique is then used in our trading system. The major component is a neural network that is trained by trading experiences from tree search and outputs prior probability to guide search by pruning away branches in turn. Experimental results on simulated and real financial data verify the robustness of the proposed trading system and the trading system produces better strategies than several approaches based on reinforcement learning.