 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Grid Keypoint Learning for Efficient Video Prediction
Paper and Code
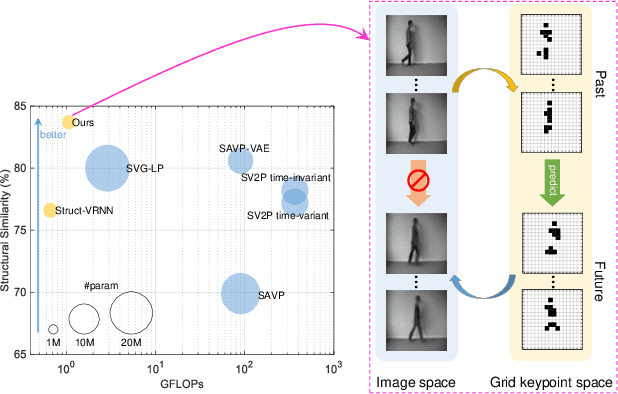
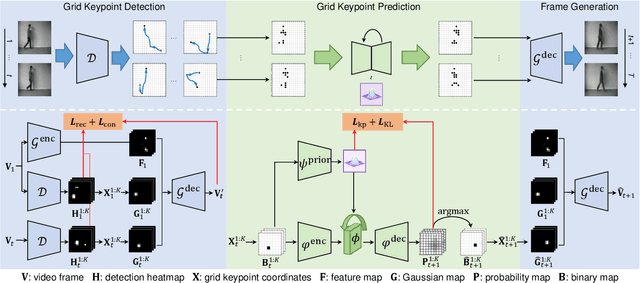
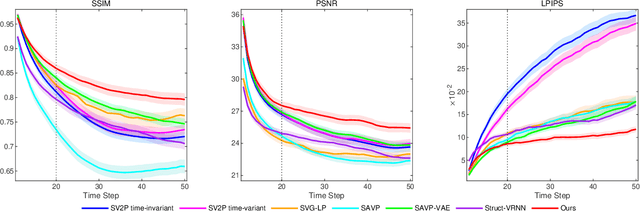

Video prediction methods generally consume substantial computing resources in training and deployment, among which keypoint-based approaches show promising improvement in efficiency by simplifying dense image prediction to light keypoint prediction. However, keypoint locations are often modeled only as continuous coordinates, so noise from semantically insignificant deviations in videos easily disrupt learning stability, leading to inaccurate keypoint modeling. In this paper, we design a new grid keypoint learning framework, aiming at a robust and explainable intermediate keypoint representation for long-term efficient video prediction. We have two major technical contributions. First, we detect keypoints by jumping among candidate locations in our raised grid space and formulate a condensation loss to encourage meaningful keypoints with strong representative capability. Second, we introduce a 2D binary map to represent the detected grid keypoints and then suggest propagating keypoint locations with stochasticity by selecting entries in the discrete grid space, thus preserving the spatial structure of keypoints in the longterm horizon for better future frame generation. Extensive experiments verify that our method outperforms the state-ofthe-art stochastic video prediction methods while saves more than 98% of computing resources. We also demonstrate our method on a robotic-assisted surgery dataset with promising results. Our code is available at https://github.com/xjgaocs/Grid-Keypoint-Learning.