 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuture Frame Prediction for Robot-assisted Surgery
Paper and Code
Mar 18, 2021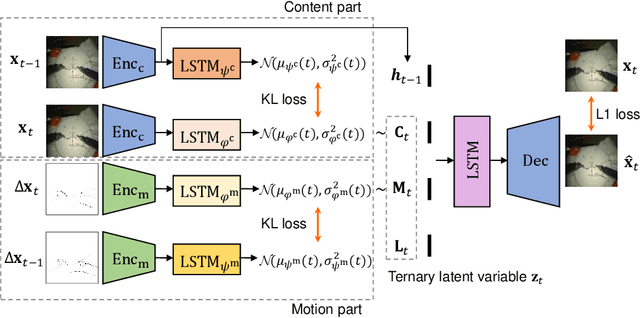
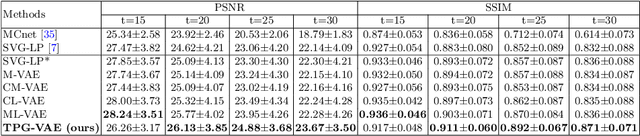

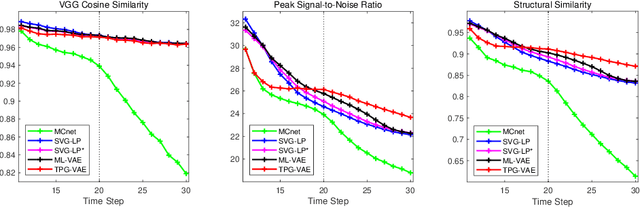
Predicting future frames for robotic surgical video is an interesting, important yet extremely challenging problem, given that the operative tasks may have complex dynamics. Existing approaches on future prediction of natural videos were based on either deterministic models or stochastic models, including deep recurrent neural networks, optical flow, and latent space modeling. However, the potential in predicting meaningful movements of robots with dual arms in surgical scenarios has not been tapped so far, which is typically more challenging than forecasting independent motions of one arm robots in natural scenarios. In this paper, we propose a ternary prior guided variational autoencoder (TPG-VAE) model for future frame prediction in robotic surgical video sequences. Besides content distribution, our model learns motion distribution, which is novel to handle the small movements of surgical tools. Furthermore, we add the invariant prior information from the gesture class into the generation process to constrain the latent space of our model. To our best knowledge, this is the first time that the future frames of dual arm robots are predicted considering their unique characteristics relative to general robotic videos. Experiments demonstrate that our model gains more stable and realistic future frame prediction scenes with the suturing task on the public JIGSAWS dataset.