 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Interaction Aggregation for Action Detection
Apr 16, 2020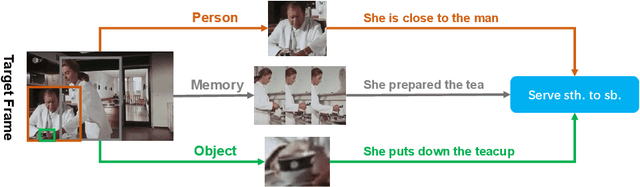
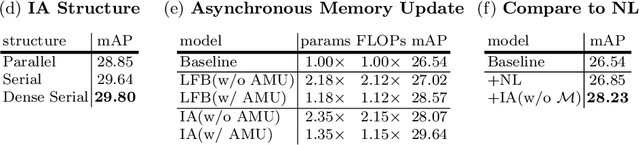
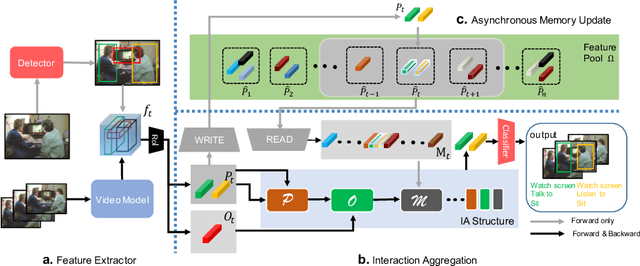

Understanding interaction is an essential part of video action detection. We propose the Asynchronous Interaction Aggregation network (AIA) that leverages different interactions to boost action detection. There are two key designs in it: one is the Interaction Aggregation structure (IA) adopting a uniform paradigm to model and integrate multiple types of interaction; the other is the Asynchronous Memory Update algorithm (AMU) that enables us to achieve better performance by modeling very long-term interaction dynamically without huge computation cost. We provide empirical evidence to show that our network can gain notable accuracy from the integrative interactions and is easy to train end-to-end. Our method reports the new state-of-the-art performance on AVA dataset, with 3.7 mAP gain (12.6% relative improvement) on validation split comparing to our strong baseline. The results on dataset UCF101-24 and EPIC-Kitchens further illustrate the effectiveness of our approach. Source code will be made public at: https://github.com/MVIG-SJTU/AlphAction .
Three Branches: Detecting Actions With Richer Features
Aug 13, 2019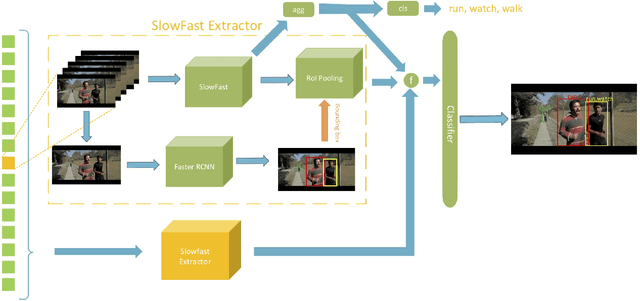

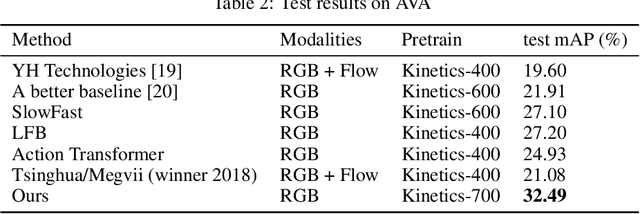
We present our three branch solutions for International Challenge on Activity Recognition at CVPR2019. This model seeks to fuse richer information of global video clip, short human attention and long-term human activity into a unified model. We have participated in two tasks: Task A, the Kinetics challenge and Task B, spatio-temporal action localization challenge. For Kinetics, we achieve 21.59% error rate. For the AVA challenge, our final model obtains 32.49% mAP on the test sets, which outperforms all submissions to the AVA challenge at CVPR 2018 for more than 10% mAP. As the future work, we will introduce human activity knowledge, which is a new dataset including key information of human activity.