Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree Branches: Detecting Actions With Richer Features
Paper and Code
Aug 13, 2019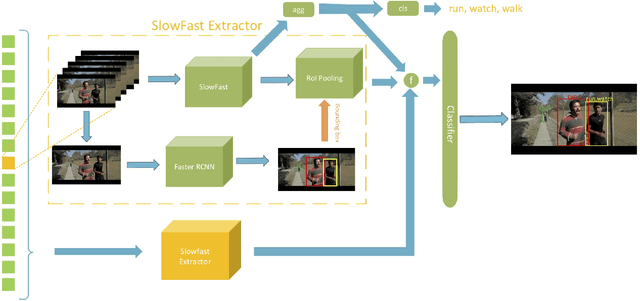

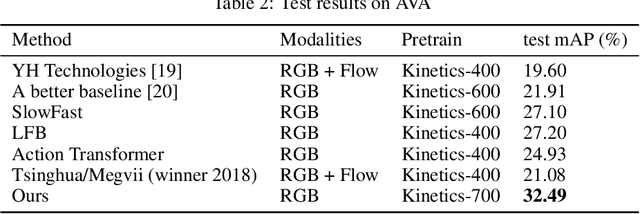
We present our three branch solutions for International Challenge on Activity Recognition at CVPR2019. This model seeks to fuse richer information of global video clip, short human attention and long-term human activity into a unified model. We have participated in two tasks: Task A, the Kinetics challenge and Task B, spatio-temporal action localization challenge. For Kinetics, we achieve 21.59% error rate. For the AVA challenge, our final model obtains 32.49% mAP on the test sets, which outperforms all submissions to the AVA challenge at CVPR 2018 for more than 10% mAP. As the future work, we will introduce human activity knowledge, which is a new dataset including key information of human activity.
View paper on