 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelayed Rewards Calibration via Reward Empirical Sufficiency
Feb 23, 2021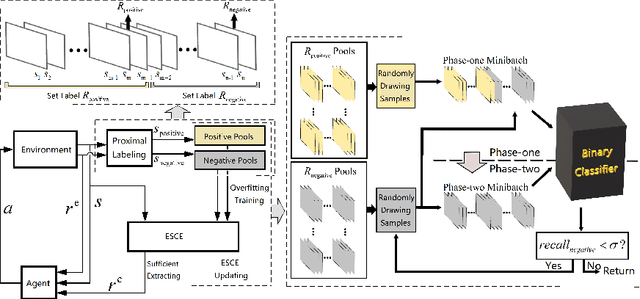
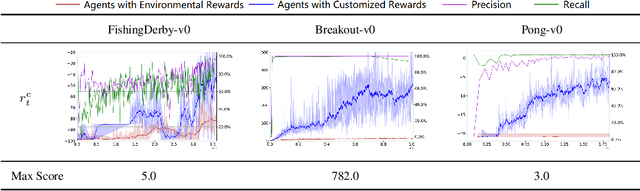

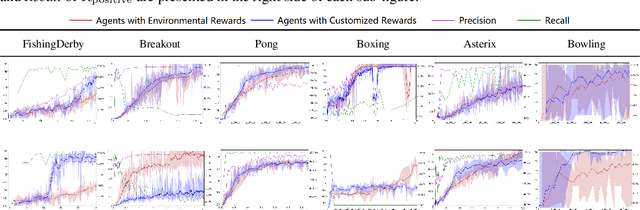
Appropriate credit assignment for delay rewards is a fundamental challenge for reinforcement learning. To tackle this problem, we introduce a delay reward calibration paradigm inspired from a classification perspective. We hypothesize that well-represented state vectors share similarities with each other since they contain the same or equivalent essential information. To this end, we define an empirical sufficient distribution, where the state vectors within the distribution will lead agents to environmental reward signals in the consequent steps. Therefore, a purify-trained classifier is designed to obtain the distribution and generate the calibrated rewards. We examine the correctness of sufficient state extraction by tracking the real-time extraction and building different reward functions in environments. The results demonstrate that the classifier could generate timely and accurate calibrated rewards. Moreover, the rewards are able to make the model training process more efficient. Finally, we identify and discuss that the sufficient states extracted by our model resonate with the observations of humans.