 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Cache: Bit-Serial In-Cache Acceleration of Deep Neural Networks
May 09, 2018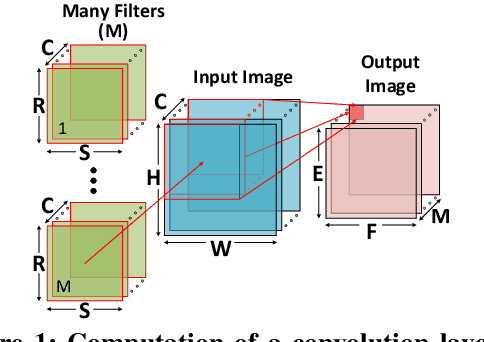
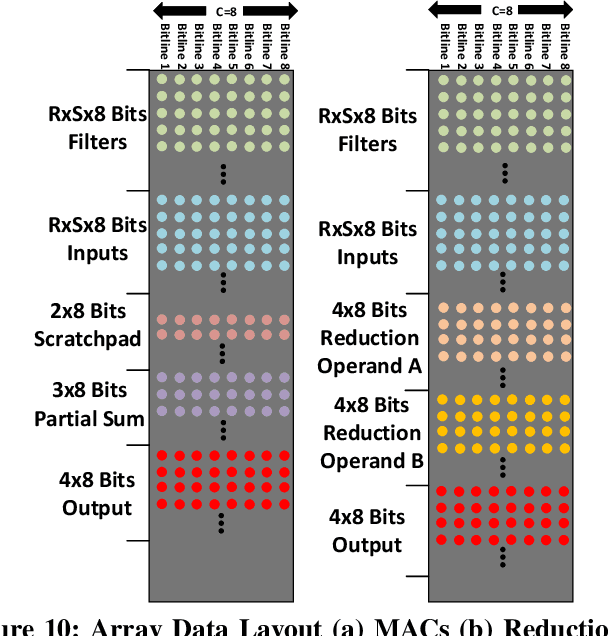
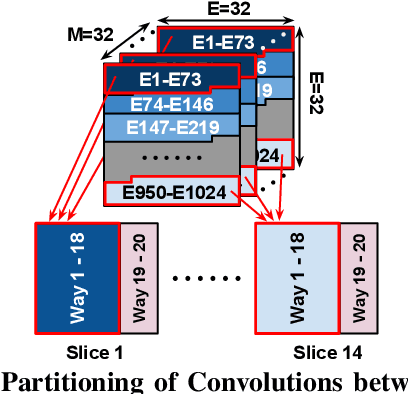
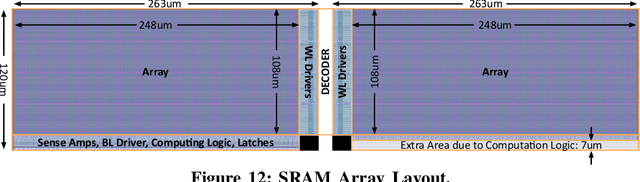
This paper presents the Neural Cache architecture, which re-purposes cache structures to transform them into massively parallel compute units capable of running inferences for Deep Neural Networks. Techniques to do in-situ arithmetic in SRAM arrays, create efficient data mapping and reducing data movement are proposed. The Neural Cache architecture is capable of fully executing convolutional, fully connected, and pooling layers in-cache. The proposed architecture also supports quantization in-cache. Our experimental results show that the proposed architecture can improve inference latency by 18.3x over state-of-art multi-core CPU (Xeon E5), 7.7x over server class GPU (Titan Xp), for Inception v3 model. Neural Cache improves inference throughput by 12.4x over CPU (2.2x over GPU), while reducing power consumption by 50% over CPU (53% over GPU).