 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotogrammetry-Reconstructed 3D Head Meshes for Accessible Individual Head-Related Transfer Functions
Mar 25, 2026Individual head-related transfer functions (HRTFs) are essential for accurate spatial audio binaural rendering but remain difficult to obtain due to measurement complexity. This study investigates whether photogrammetry-reconstructed (PR) head and ear meshes, acquired with consumer hardware, can provide a practically useful baseline for individual HRTF synthesis. Using the SONICOM HRTF dataset, 72-image photogrammetry captures per subject were processed with Apple's Object Capture API to generate PR meshes for 150 subjects. Mesh2HRTF was used to compute PR synthetic HRTFs, which were compared against measured HRTFs, high-resolution 3D scan-derived HRTFs, KEMAR, and random HRTFs through numerical evaluation, auditory models, and a behavioural sound localisation experiment (N = 27). PR synthetic HRTFs preserved ITD cues but exhibited increased ILD and spectral errors. Auditory-model predictions and behavioural data showed substantially higher quadrant error rates, reduced elevation accuracy, and greater front-back confusions than measured HRTFs, performing worse than random HRTFs on perceptual metrics. Current photogrammetry pipelines support individual HRTF synthesis but are limited by insufficient pinna morphology details and high-frequency spectral fidelity needed for accurate individual HRTFs containing monaural cues.
Enhancing spatial hearing with cochlear implants: exploring the role of AI, multimodal interaction and perceptual training
Feb 14, 2026Cochlear implants (CIs) have been developed to the point where they can restore hearing and speech understanding in a large proportion of patients. Although spatial hearing is central to controlling and directing attention and to enabling speech understanding in noisy environments, it has been largely neglected in the past. We propose here a multi-disciplinary research framework in which physicians, psychologists and engineers collaborate to improve spatial hearing for CI users.
HRTFformer: A Spatially-Aware Transformer for Personalized HRTF Upsampling in Immersive Audio Rendering
Oct 02, 2025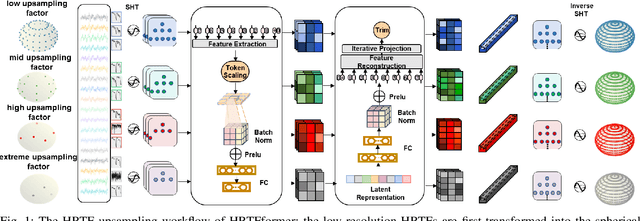
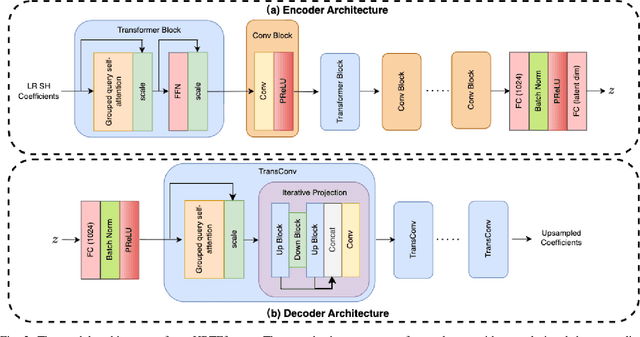
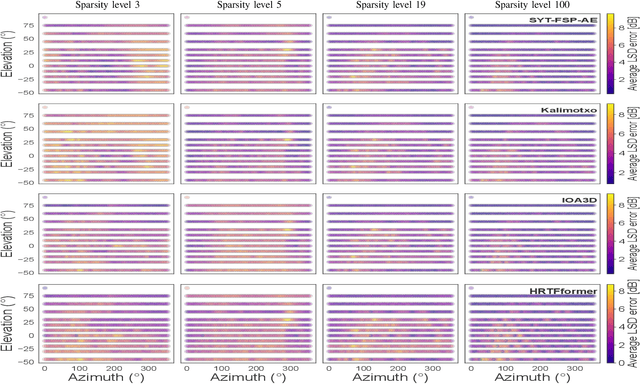
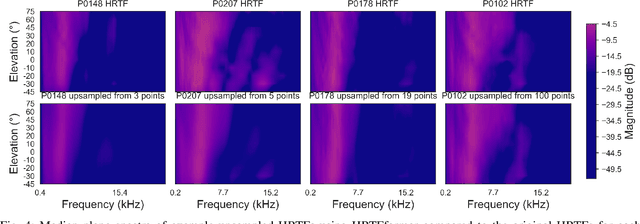
Personalized Head-Related Transfer Functions (HRTFs) are starting to be introduced in many commercial immersive audio applications and are crucial for realistic spatial audio rendering. However, one of the main hesitations regarding their introduction is that creating personalized HRTFs is impractical at scale due to the complexities of the HRTF measurement process. To mitigate this drawback, HRTF spatial upsampling has been proposed with the aim of reducing measurements required. While prior work has seen success with different machine learning (ML) approaches, these models often struggle with long-range spatial consistency and generalization at high upsampling factors. In this paper, we propose a novel transformer-based architecture for HRTF upsampling, leveraging the attention mechanism to better capture spatial correlations across the HRTF sphere. Working in the spherical harmonic (SH) domain, our model learns to reconstruct high-resolution HRTFs from sparse input measurements with significantly improved accuracy. To enhance spatial coherence, we introduce a neighbor dissimilarity loss that promotes magnitude smoothness, yielding more realistic upsampling. We evaluate our method using both perceptual localization models and objective spectral distortion metrics. Experiments show that our model surpasses leading methods by a substantial margin in generating realistic, high-fidelity HRTFs.
Optimal Pairwise Comparison Procedures for Subjective Evaluation
Aug 25, 2025Audio signal processing algorithms are frequently assessed through subjective listening tests in which participants directly score degraded signals on a unidimensional numerical scale. However, this approach is susceptible to inconsistencies in scale calibration between assessors. Pairwise comparisons between degraded signals offer a more intuitive alternative, eliciting the relative scores of candidate signals with lower measurement error and reduced participant fatigue. Yet, due to the quadratic growth of the number of necessary comparisons, a complete set of pairwise comparisons becomes unfeasible for large datasets. This paper compares pairwise comparison procedures to identify the most efficient methods for approximating true quality scores with minimal comparisons. A novel sampling procedure is proposed and benchmarked against state-of-the-art methods on simulated datasets. Bayesian sampling produces the most robust score estimates among previously established methods, while the proposed procedure consistently converges fastest on the underlying ranking with comparable score accuracy.
Effects of auditory distance cues and reverberation on spatial perception and listening strategies
May 23, 2025Spatial hearing, the brain's ability to use auditory cues to identify the origin of sounds, is crucial for everyday listening. While simplified paradigms have advanced the understanding of spatial hearing, their lack of ecological validity limits their applicability to real-life conditions. This study aims to address this gap by investigating the effects of listener movement, reverberation, and distance on localisation accuracy in a more ecologically valid context. Participants performed active localisation tasks with no specific instructions on listening strategy, in either anechoic or reverberant conditions. The results indicate that the head movements were more frequent in reverberant environments, suggesting an adaptive strategy to mitigate uncertainty in binaural cues due to reverberation. While distance did not affect the listening strategy, it influenced the localisation performance. Our outcomes suggest that listening behaviour is adapted depending on the current acoustic conditions to support an effective perception of the space.
A Machine Learning Approach for Denoising and Upsampling HRTFs
Apr 24, 2025The demand for realistic virtual immersive audio continues to grow, with Head-Related Transfer Functions (HRTFs) playing a key role. HRTFs capture how sound reaches our ears, reflecting unique anatomical features and enhancing spatial perception. It has been shown that personalized HRTFs improve localization accuracy, but their measurement remains time-consuming and requires a noise-free environment. Although machine learning has been shown to reduce the required measurement points and, thus, the measurement time, a controlled environment is still necessary. This paper proposes a method to address this constraint by presenting a novel technique that can upsample sparse, noisy HRTF measurements. The proposed approach combines an HRTF Denoisy U-Net for denoising and an Autoencoding Generative Adversarial Network (AE-GAN) for upsampling from three measurement points. The proposed method achieves a log-spectral distortion (LSD) error of 5.41 dB and a cosine similarity loss of 0.0070, demonstrating the method's effectiveness in HRTF upsampling.
EEG-Based Decoding of Sound Location: Comparing Free-Field to Headphone-Based Non-Individual HRTFs
Mar 13, 2025



Sound source localization relies on spatial cues such as interaural time differences (ITD), interaural level differences (ILD), and monaural spectral cues. Individually measured Head-Related Transfer Functions (HRTFs) facilitate precise spatial hearing but are impractical to measure, necessitating non-individual HRTFs, which may compromise localization accuracy and externalization. To further investigate this phenomenon, the neurophysiological differences between free-field and non-individual HRTF listening are explored by decoding sound locations from EEG-derived Event-Related Potentials (ERPs). Twenty-two participants localized stimuli under both conditions with EEG responses recorded and logistic regression classifiers trained to distinguish sound source locations. Lower cortical response amplitudes were observed for KEMAR compared to free-field, especially in front-central and occipital-parietal regions. ANOVA identified significant main effects of auralization condition (F(1, 21) = 34.56, p < 0.0001) and location (F(3, 63) = 18.17, p < 0.0001) on decoding accuracy (DA), which was higher in free-field and interaural-cue-dominated locations. DA negatively correlated with front-back confusion rates (r = -0.57, p < 0.01), linking neural DA to perceptual confusion. These findings demonstrate that headphone-based non-individual HRTFs elicit lower amplitude cortical responses to static, azimuthally-varying locations than free-field conditions. The correlation between EEG-based DA and front-back confusion underscores neurophysiological markers' potential for assessing spatial auditory discrimination.
Perceptual implications of simplifying geometrical acoustics models for Ambisonics-based binaural reverberation
Nov 15, 2024



Different methods can be employed to render virtual reverberation, often requiring substantial information about the room's geometry and the acoustic characteristics of the surfaces. However, fully comprehensive approaches that account for all aspects of a given environment may be computationally costly and redundant from a perceptual standpoint. For these methods, achieving a trade-off between perceptual authenticity and model's complexity becomes a relevant challenge. This study investigates this compromise through the use of geometrical acoustics to render Ambisonics-based binaural reverberation. Its precision is determined, among other factors, by its fidelity to the room's geometry and to the acoustic properties of its materials. The purpose of this study is to investigate the impact of simplifying the room geometry and the frequency resolution of absorption coefficients on the perception of reverberation within a virtual sound scene. Several decimated models based on a single room were perceptually evaluated using the a multi-stimulus comparison method. Additionally, these differences were numerically assessed through the calculation of acoustic parameters of the reverberation. According to numerical and perceptual evaluations, lowering the frequency resolution of absorption coefficients can have a significant impact on the perception of reverberation, while a less notable impact was observed when decimating the geometry of the model.
HRTF upsampling with a generative adversarial network using a gnomonic equiangular projection
Jun 09, 2023



An individualised head-related transfer function (HRTF) is essential for creating realistic virtual reality (VR) and augmented reality (AR) environments. However, acoustically measuring high-quality HRTFs requires expensive equipment and an acoustic lab setting. To overcome these limitations and to make this measurement more efficient HRTF upsampling has been exploited in the past where a high-resolution HRTF is created from a low-resolution one. This paper demonstrates how generative adversarial networks (GANs) can be applied to HRTF upsampling. We propose a novel approach that transforms the HRTF data for convenient use with a convolutional super-resolution generative adversarial network (SRGAN). This new approach is benchmarked against two baselines: barycentric upsampling and a HRTF selection approach. Experimental results show that the proposed method outperforms both baselines in terms of log-spectral distortion (LSD) and localisation performance using perceptual models when the input HRTF is sparse.
On The Relevance Of The Differences Between HRTF Measurement Setups For Machine Learning
Dec 08, 2022


As spatial audio is enjoying a surge in popularity, data-driven machine learning techniques that have been proven successful in other domains are increasingly used to process head-related transfer function measurements. However, these techniques require much data, whereas the existing datasets are ranging from tens to the low hundreds of datapoints. It therefore becomes attractive to combine multiple of these datasets, although they are measured under different conditions. In this paper, we first establish the common ground between a number of datasets, then we investigate potential pitfalls of mixing datasets. We perform a simple experiment to test the relevance of the remaining differences between datasets when applying machine learning techniques. Finally, we pinpoint the most relevant differences.