 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Bounds for Adversarial Contrastive Learning
Paper and Code
Feb 21, 2023

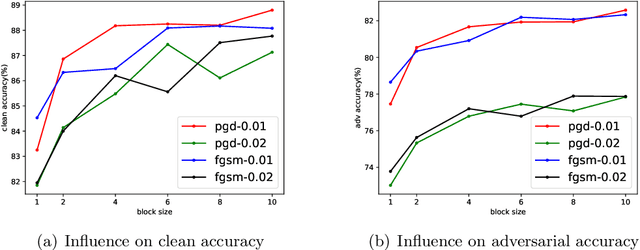

Deep networks are well-known to be fragile to adversarial attacks, and adversarial training is one of the most popular methods used to train a robust model. To take advantage of unlabeled data, recent works have applied adversarial training to contrastive learning (Adversarial Contrastive Learning; ACL for short) and obtain promising robust performance. However, the theory of ACL is not well understood. To fill this gap, we leverage the Rademacher complexity to analyze the generalization performance of ACL, with a particular focus on linear models and multi-layer neural networks under $\ell_p$ attack ($p \ge 1$). Our theory shows that the average adversarial risk of the downstream tasks can be upper bounded by the adversarial unsupervised risk of the upstream task. The experimental results validate our theory.